目 录
1 R-CNN(Region with CNN feature)
1 R-CNN(Region with CNN feature)
R-CNN的提出将目标检测领域的最高准确度至少提高了30%,在目标检测瓶颈期时,传统的目标检测算法正确率在30%左右。而R-CNN的出现使正确率到达50%多。
1.1 R-CNN算法流程
分为以下四个步骤:
①使用SS算法(Selective Search)在每一张图像上获取1000~2000个候选区域:

如图通过SS算法通过图像分割的方法得到一系列矩形框,每个矩形框中都可能包含我们要检测的目标。
②对每一个候选区域,使用深度网络(即为图片分类网络)提取特征:
将每一个候选框(假设共有2000个)都缩放(Resize)到227×227的大小,将候选区输入到事先训练好的图像分类网络(去掉全连接层)中,获得4096维的特征(假设展平处理之前的输出矩阵为64×64的),最终得到2000(行)×4096(列)维矩阵,每一行对应一个候选框的特征向量。
③将特征送入每一类的SVM分类器,判断是否属于该类别:

步骤②得到的矩阵为2000×4096, 假设一共有20个类别,则一共有20个SVM分类器,则每一个分类器都有与输入矩阵对应4096个权值向量。将输入矩阵的第一行和SVM分类器的第一列(即第一个类别)相乘,得到的就是第一个候选框所属于第一个类别的概率,最终得到2000×20的矩阵;其中每行代表一个候选框归属于每个类别的概率,每一列则表示每一个候选框所归属不同类别的概率。
然后我们需要剔除每一类的重叠候选框,利用非极大值抑制(NMS)算法:
IoU(Intersection over Union)表示(A∩B)/(A∪B):

我们对每一个类别寻找概率最高的候选框,然后计算其他候选框与该候选框的IoU值,最后删除所有IoU值大于给定阈值的目标,将该候选框保留;然后再从剩下的候选框中寻找概率最高的候选框,再按照该流程计算,直到遍历了所有的候选框。经过该处理后,每一列(即每一类别)都会保留一些高质量的候选框。
比如以下例子:
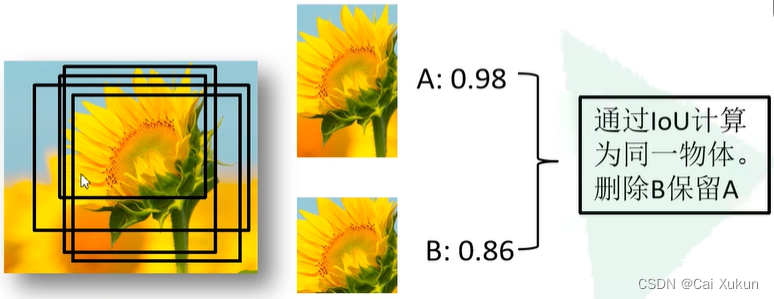
找到A候选框的概率最高为98%,B候选框的概率为86%,经过计算IoU大于给定的阈值,则删除B候选框留下A候选框。
④使用回归器精细修正第③步剩余候选框位置:
一共有20个类别,采用20个回归器进行回归操作(根据第②步输出的特征向量),最终得到每个类别修正后得分最高的候选框。
综上,R-CNN的框架如下:

1.2 R-CNN存在的问题
①测试速度慢:
在一个多核CPU中测试一张图片需要53秒,用SS算法提取候选框用时2秒,一张图像的候选框之间又存在大量的重叠,提取特征操作冗余;
②训练速度慢;
③训练所需空间大:
对于SVM和第④步的回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于有一定深度的网络,如VGG-16,从5千张图像上提取的特征需要数百GB的存储空间。
2 Fast R-CNN

与R-CNN相比训练快9倍,测试推理快213倍,准确率在Pascal VOC数据集上从62%提升至66%。
2.1 Fast R-CNN算法流程
①使用SS算法在一张图像上生成1K~2K个候选区域:
这些候选框不用全部使用,随机采样一些使用,且候选区域要分为正样本(候选框中有检测目标)和负样本(候选框中没有检测目标)。
②将图像输入到网络中得到对应特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵:

将图像直接输入到网络中得到特征图(参考SPP-NET),通过每个候选区域原图和特征图的映射关系,在特征图中能够直接获取特征矩阵,这样候选区域的特征就不用重复地计算了,大幅提升速度。
③将每个特征矩阵通过ROI(Reigon of interest) pooling层缩放到统一的尺寸(论文中为7×7大小)得到新尺寸的特征图,将特征图通过展平通过一系列全连接层得到预测结果:

ROI pooling层是将特征矩阵分为7×7块,每一块都进行最大池化下采样操作,这样可以不用限制图像的尺寸。
最终会得到目标所属的类别和候选框的回归参数,和R-CNN不同在于:在R-CNN中特别训练了SVM分类器对候选框进行分类,训练了回归器对候选框进行调整;但是在Fast R-CNN中只通过一个和网络就完成了。
在网络中对于所属目标概率的分类器,输出N+1个类别的概率(N为检测目标的种类、1为背景):

经过softmax处理,因此概率和为1。
对于候选框的回归器,会输出N+1个类别的候选框回归参数,共(N+1)×4个节点:

根据预测候选框的回归参数最终得到预测的候选框是根据如下公式计算的:
其中分别为候选框的中心x,y坐标以及宽高
分别为预测候选框的中心x,y坐标以及宽高

可以看出候选框回归参数用来候选框中心坐标,选框回归参数
是用来候选框宽高,最终将候选框P根据实际框G调整到预测候选框红色框的位置。
2.2 Fast R-CNN损失的计算
由于我们需要预测目标所属的类别概率和候选框的回归参数,因此需要计算两个损失:分类损失和边界框回归损失。公式如下
分类损失:
边界框回归损失:
其中:
为平衡系数,用来平衡分类损失和边界框回归损失;
若满足该条件(为正样本,则采用该损失)则值为1,否则(为负样本,不采用边界框回归损失)为0;
是分类器预测的softmax概率分布
;
对应目标真实类别标签;
对应候选框回归器预测的对应类别
的回归参数
;
对应真实目标的候选框回归参数
。
综上,Faster R-CNN的框架如下:
