目 录

1. 网络概述与效果
该网络的论文是Google在2019年发表的文章,作者同时探讨了输入图像分辨率和网络的深度、宽度对准确率的影响,通过网络搜索技术同时探索这三者的合理配置。
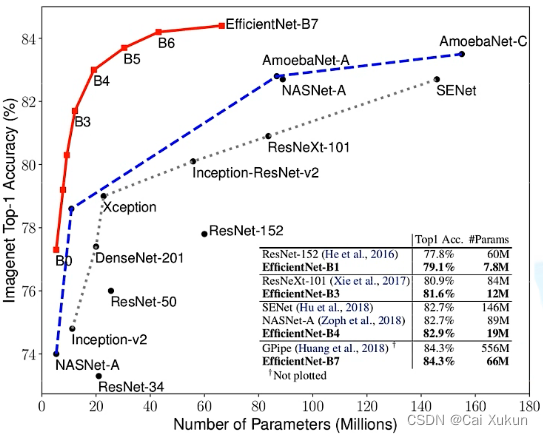
EfficientNet效果如上图,该论文中提出的EfficientNet-B7在ImageNet top-1上达到了当年最高的准确率84.3%,与之前准确率最高的GPipe相比,参数量仅为其1/8.4,推理速度提升了6.1倍。
2. 网络研究背景
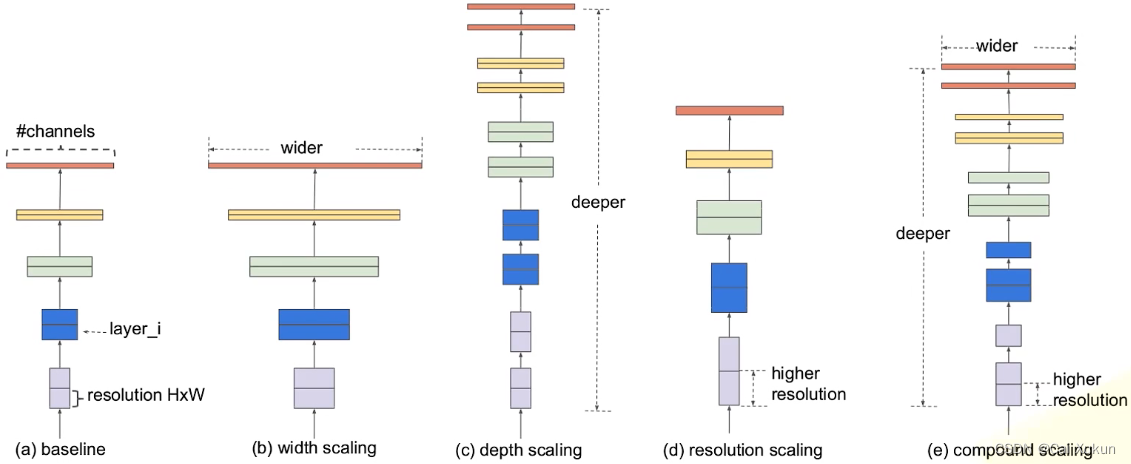
图(a)是一个传统的卷积神经网络;图(b)在图(a)的基础上增大了特征矩阵的channel,即对于每个卷积层使用更多的卷积核,提升特征矩阵channel个数;图(c)在图(a)的基础上增加了网络深度;图(d)提升了输入图像的分辨率,这样得到的特征矩阵得到的高和宽也会相应增加;图(e)则是同时增加网络的宽度、深度和输入图像的分辨率。
- 增加网络的深度能够得到更加丰富和深层次的特征,并且能够很好的应用到其他任务中,但是网络深度过深会面临梯度消失和训练困难的问题;
- 增加网络的宽度能够获得更高细粒度的特征并且也更容易训练,但是宽度很大深度较浅的网络通常很难学到更深层次的特征;
- 增加输入图像的分辨率能够为网络提供更多可学习的细节特征,但对于非常高的输入分辨率,准确率的增益会减小,并且大分辨率图像也会增加计算量。
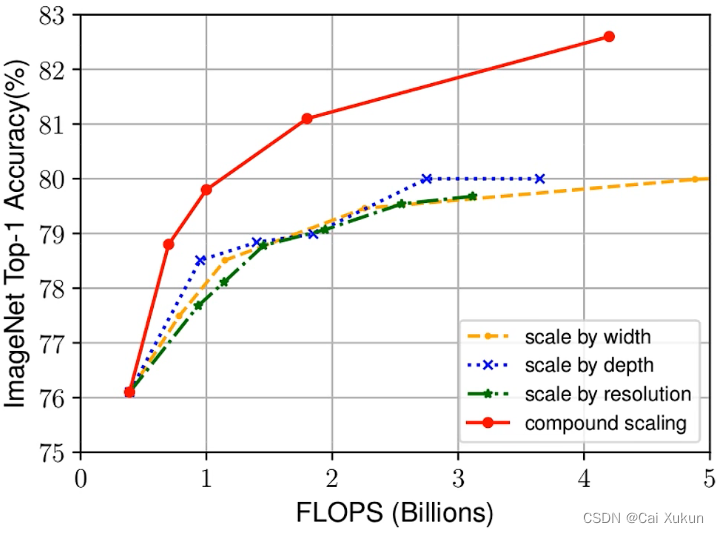
三个虚线分别对应着增加网络的宽度、深度和增加图像的分辨率,可以看到准确率到80%后基本就趋于饱和了;红色的线是同时增大这三项,可以看出没有出现饱和的现象,还在继续增长,这说明同时增加网络的宽度、深度和图像的分辨率可以得到更好的结果;当FLOPS(理论计算量)相同时,同时增大这三项得到的效果也会更好。
3. EfficientNet-B0网络结构
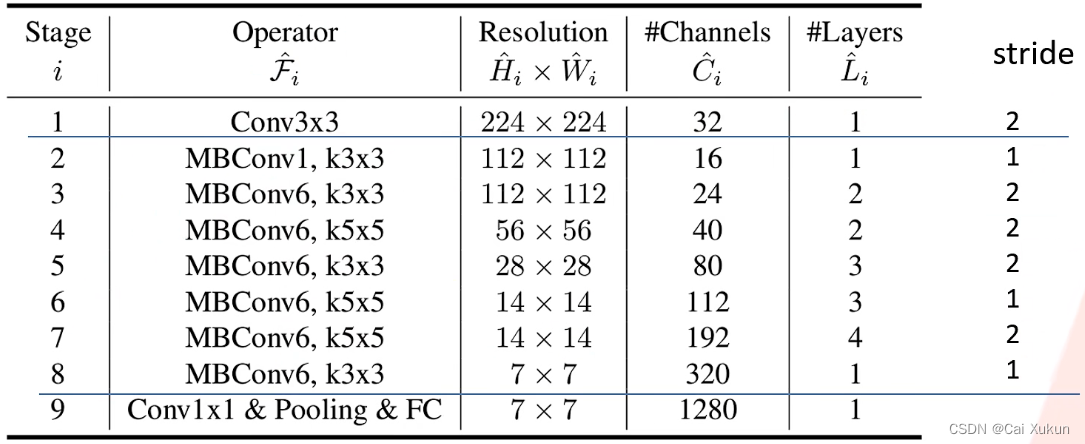
该网络是通过网络搜索技术得到的,其余的EfficientNet网络都是在此基础上进行调整的。网络一共分为9个stage:stage1是一个3×3的卷积层,stage2-8在重复地堆叠MBConv,stage9由一个1×1的卷积层、池化层和全连接层组成的,卷积层后都跟有BN层和Swish激活函数。
Resolution是输入每个stage时特征矩阵的高和宽;Channels是每个特征矩阵输出channel的个数;Layers是将Operator重复多少次;stride可以通过Resolution得出,但要注意每个stage只有第一个Operator的步长为表格中的数据,其余均为1。
3.1 MBConv
MBConv和MobileNet v3所使用的block是相同的,具体结构参考利用Pytorch实现MobileNet网络:

- 第一个1×1的卷积层起到升维作用,卷积核个数是输入特征矩阵channel的n倍,n为上表中MBConv后面跟的数字;
- 最后1×1的卷积层起到降维作用,卷积核个数根据表格中的channels来设置;
- 当n=1时,没有进行升维操作,因此就不需要升维的1×1的卷积层,从表格中看stage2的MBConv结构没有升维的1×1的卷积层;
- 捷径分支只有当MBConv的输入特征矩阵和输出特征矩阵的shape相同时才存在。
3.2 SE模块
SE模块也和MobileNet v3所使用的相同:

不同点在于FC1节点的个数不是输入SE模块特征矩阵channel的1/4,而是输入该MBConv特征矩阵channel的1/4。
3.3 网络参数设置
EfficientNetB1-7网络参数设置如下表:
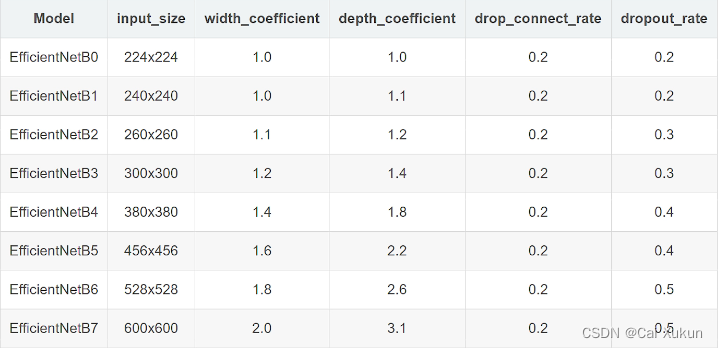
- width_coefficient是channel维度上的倍率因子。以EfficientNetB6为例,width_coefficient为1.8,在EfficientNetB0中stage1的3×3卷积层所使用的卷积核个数是32,在B6中这个层的卷积核个数为32×1.8=57.6,取整到离它最近的8的整数倍,就是56。
- depth_coefficient代表depth维度上的倍率因子(仅对于stage2-8)。比如在EfficientNetB0中stage7的Layers=4,在EfficientNetB6中就是4×2.6=10.4,向上取整这个值就为11。
- drop_connect_rate代表MBConv中Droupout层的失活比例。
- dropout_rate是最后一个全连接层前面的Droupout层的失活比例。
4. 利用Pytorch实现EfficientNet
4.1 注意力模块
# 注意力模块
class SqueezeExcitation(nn.Module):
def __init__(self,
input_c: int, # 输入MBConv的channel
expand_c: int, # MBConv中第一个Conv输出的channel,DW卷积不改变channel数
squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
# 第一个fc节点个数
squeeze_c = input_c // squeeze_factor
# 1×1卷积代替fc
self.fc1 = nn.Conv2d(expand_c, squeeze_c, 1)
self.ac1 = nn.SiLU() # alias Swish
self.fc2 = nn.Conv2d(squeeze_c, expand_c, 1)
self.ac2 = nn.Sigmoid()
# 注意力模块的前向传播
def forward(self, x: Tensor):
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = self.ac1(scale)
scale = self.fc2(scale)
scale = self.ac2(scale)
return scale * x4.2 MBConv模块的具体实现
首先定义一个卷积BN激活整合的类,因为这个组合用到的很多:
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
# BN结构
norm_layer: Optional[Callable[..., nn.Module]] = None,
# 激活函数
activation_layer: Optional[Callable[..., nn.Module]] = None):
padding = (kernel_size - 1) // 2
# 默认使用BN层和SiLU激活函数(和swish激活函数相同)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.SiLU # alias Swish (torch>=1.7)
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer())定义MBConv类:
# MBConv模块的参数设置
class InvertedResidualConfig:
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate
def __init__(self,
kernel: int, # 3 or 5
input_c: int,
out_c: int,
expanded_ratio: int, # 1 or 6
stride: int, # 1 or 2
# 是否使用SE模块
use_se: bool, # True
drop_rate: float,
index: str, # 1a, 2a, 2b, ...
# 网络宽度方向的倍率因子
width_coefficient: float):
# 根据B0和倍率相乘得到其他版本网络的channel
self.input_c = self.adjust_channels(input_c, width_coefficient)
self.kernel = kernel
self.expanded_c = self.input_c * expanded_ratio
self.out_c = self.adjust_channels(out_c, width_coefficient)
self.use_se = use_se
self.stride = stride
self.drop_rate = drop_rate
self.index = index
@staticmethod
def adjust_channels(channels: int, width_coefficient: float):
return _make_divisible(channels * width_coefficient, 8)
# MBConv模块
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
# BN层
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
# 判断stride参数是否有错
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
# 是否使用shortcut连接
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
# 存放层结构
layers = OrderedDict()
activation_layer = nn.SiLU # alias Swish
# expand
# 只有expanded_ratio≠1才使用第一个1×1的卷积层
if cnf.expanded_c != cnf.input_c:
layers.update({"expand_conv": ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# depthwise
layers.update({"dwconv": ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
# DW卷积group数和expanded_c相同
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# 是否使用SE模块
if cnf.use_se:
layers.update({"se": SqueezeExcitation(cnf.input_c,
cnf.expanded_c)})
# project
# 最后1×1的卷积层
layers.update({"project_conv": ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
# 传入nn.Identity表示没有激活函数
activation_layer=nn.Identity)})
self.block = nn.Sequential(layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
# 只有在使用shortcut连接时才使用dropout层
if self.use_res_connect and cnf.drop_rate > 0:
self.dropout = DropPath(cnf.drop_rate)
else:
self.dropout = nn.Identity()
def forward(self, x: Tensor):
result = self.block(x)
result = self.dropout(result)
if self.use_res_connect:
result += x
return result4.3 搭建EfficientNet
# 搭建EfficientNet
class EfficientNet(nn.Module):
def __init__(self,
width_coefficient: float,
depth_coefficient: float,
num_classes: int = 1000,
dropout_rate: float = 0.2,
drop_connect_rate: float = 0.2,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None
):
super(EfficientNet, self).__init__()
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate, repeats
default_cnf = [[3, 32, 16, 1, 1, True, drop_connect_rate, 1],
[3, 16, 24, 6, 2, True, drop_connect_rate, 2],
[5, 24, 40, 6, 2, True, drop_connect_rate, 2],
[3, 40, 80, 6, 2, True, drop_connect_rate, 3],
[5, 80, 112, 6, 1, True, drop_connect_rate, 3],
[5, 112, 192, 6, 2, True, drop_connect_rate, 4],
[3, 192, 320, 6, 1, True, drop_connect_rate, 1]]
# 重复次数以及其他版本网络的向上取整
def round_repeats(repeats):
"""Round number of repeats based on depth multiplier."""
return int(math.ceil(depth_coefficient * repeats))
if block is None:
block = InvertedResidual
if norm_layer is None:
# eps和momentum是BN的超参数
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
adjust_channels = partial(InvertedResidualConfig.adjust_channels,
width_coefficient=width_coefficient)
# build inverted_residual_setting
bneck_conf = partial(InvertedResidualConfig,
width_coefficient=width_coefficient)
b = 0
num_blocks = float(sum(round_repeats(i[-1]) for i in default_cnf))
inverted_residual_setting = []
for stage, args in enumerate(default_cnf):
cnf = copy.copy(args)
for i in range(round_repeats(cnf.pop(-1))):
if i > 0:
# strides equal 1 except first cnf
cnf[-3] = 1 # strides
cnf[1] = cnf[2] # input_channel equal output_channel
cnf[-1] = args[-2] * b / num_blocks # update dropout ratio
index = str(stage + 1) + chr(i + 97) # 1a, 2a, 2b, ...
inverted_residual_setting.append(bneck_conf(*cnf, index))
b += 1
# create layers
layers = OrderedDict()
# first conv
layers.update({"stem_conv": ConvBNActivation(in_planes=3,
out_planes=adjust_channels(32),
kernel_size=3,
stride=2,
norm_layer=norm_layer)})
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.update({cnf.index: block(cnf, norm_layer)})
# build top
last_conv_input_c = inverted_residual_setting[-1].out_c
last_conv_output_c = adjust_channels(1280)
layers.update({"top": ConvBNActivation(in_planes=last_conv_input_c,
out_planes=last_conv_output_c,
kernel_size=1,
norm_layer=norm_layer)})
self.features = nn.Sequential(layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
classifier = []
if dropout_rate > 0:
classifier.append(nn.Dropout(p=dropout_rate, inplace=True))
classifier.append(nn.Linear(last_conv_output_c, num_classes))
self.classifier = nn.Sequential(*classifier)
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x: Tensor):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x: Tensor):
return self._forward_impl(x)在训练过程中,可以更换不同版本的网络模型:
# 使用哪个版本的网络
from model import efficientnet_b0 as create_model
img_size = {"B0": 224,
"B1": 240,
"B2": 260,
"B3": 300,
"B4": 380,
"B5": 456,
"B6": 528,
"B7": 600}
num_model = "B0"5 训练结果
使用EfficientNet-B0网络,不使用预训练权重,训练所有参数,经过30个epoch的结果如下:
[epoch 26] accuracy: 0.819
[epoch 27] mean loss 0.579: 100%|██████████| 184/184 [00:34<00:00, 5.28it/s]
100%|██████████| 46/46 [00:14<00:00, 3.25it/s]
[epoch 27] accuracy: 0.814
[epoch 28] mean loss 0.595: 100%|██████████| 184/184 [00:32<00:00, 5.69it/s]
100%|██████████| 46/46 [00:14<00:00, 3.23it/s]
[epoch 28] accuracy: 0.825
[epoch 29] mean loss 0.566: 100%|██████████| 184/184 [00:33<00:00, 5.48it/s]
100%|██████████| 46/46 [00:15<00:00, 2.89it/s]
[epoch 29] accuracy: 0.826