完整的视频课堂链接如下:
完整的视频课堂投影片连接:
前一課堂筆記連結:
Menu this round (Case Study)
- AlexNet
- VGG net
- GoogleNet
- ResNet
AlexNet
此神经网络大致结构(8层):
CONV1 >>> MAX POOL1 >>> NORM1 >>> CONV2 >>> MAX POOL2 >>> NORM2
>>> CONV3 >>> CONV4 >>> CONV5 >>> MAX POOL3 >>> Fully Connected6 >>> FC7 >>> FC8
** 注意这边标注的是一个大致的 AlexNet 框架组成内容,并没有写出细节。
开始估算整个神经网络需要占用的资源前,先回忆一下神经个数计算方法(点击),如果现在有个 input image: 227*227*3,使用 96 个 filter matrix: 11*11,步距为 4 单位,根据没有 zero padding 的算法:[(N - F) / stride] + 1;得出的 output volumn 即为:55*55*96;而实际需要参与计算的参数个数则为:(11*11*3)*96 = 34848(个)。
依照同样的方式持续算下去更深层神经网络每一层的情况,注意 POOLING 层是没有参数的,NORM 层是一种藉由数学算法调整全体数据集分布的环节,也是没有参数参与的,详情见讲义第九页:

计算这些神经网络细节的目的是为了能够更好的让神经网络框架与硬件匹配,对于不同水平性能的硬件(如老式的 GPU)可能没有那么多的暂存空间让神经网络部署,这种情况我们需要有技巧的避开,避开方法可以是换一个更高级的硬件,或是用两个没那么高级的硬件联合容纳该神经网络。
AlexNet 也是在2012年崛起的一种神经网络,直接在辨识的准确度上拉高了水平几乎 10% 大幅领先,风靡了一阵子。后来才又被 ZFNet (11.7%) 打败,接着就是 VGG (7.3%) -> GoogleNet (6.7%) -> ResNet (3.57%)。发展的走势基本上沿着更深层的神经网络算法发展,最深可以到 19~22 层的深度,训练这些无数个 parameters 需要耗时约两周,用高级的计算机持续运行。
VGGNet
此神经网络大致结构(16层):
CONV1-1 >>> CONV1-2 >>> POOL1 >>> CONV2-1 >>> CONV2-2 >>> POOL2 >>> CONV3-1 >>> CONV3-2 >>> POOL3 >>> CONV4-1 >>> CONV4-2 >>> CONV4-3 >>> POOL4 >>> CONV5-1 >>> CONV5-2 >>> CONV5-3 >>> POOL5 >>> FC6 >>> FC7 >>> FC8 >>> SOFTMAX
改进后的此神经网络深度较 AlexNet 深了 2 倍,并且 filter matrix 缩小成 3*3,随着层数越深,使用的 filter matrix 也更多。卷积核缩小并把神经层加深,就这个 3*3 的 case 来说其实是等效于 7*7 的单层卷积核效果,但是小一点的核可以让整体参数不那么多,对于硬件资源应用来说比较节约,也可以插入更多非线性影响因子,可以更好的拟合自然中不规则的问题,故这是个比较推崇的方法。

更多关于计算神经网络架构占用内存空间的算式,可以自行参考讲义链接里的内容。
这个方法有 16 与 19 层的深度差别,19 层的准确率不会好多少,同时占用的内存也不会多太多,两种层数都是可以用的模型。做迁移学习的时候,前面 CONV 与 POOLING 的层训练出来的参数尤其好用,只要把 FC 用来分辨 1000 种结果输出的层与前几个同为 FC 的层加以改造,就可以在没有大量数据的情况下完成准确的训练模型,可以算是一种电脑的“大脑移植手术”!
GoogleNet
设计初衷就是让计算更有效率,即便神经网络深到了 22 层。
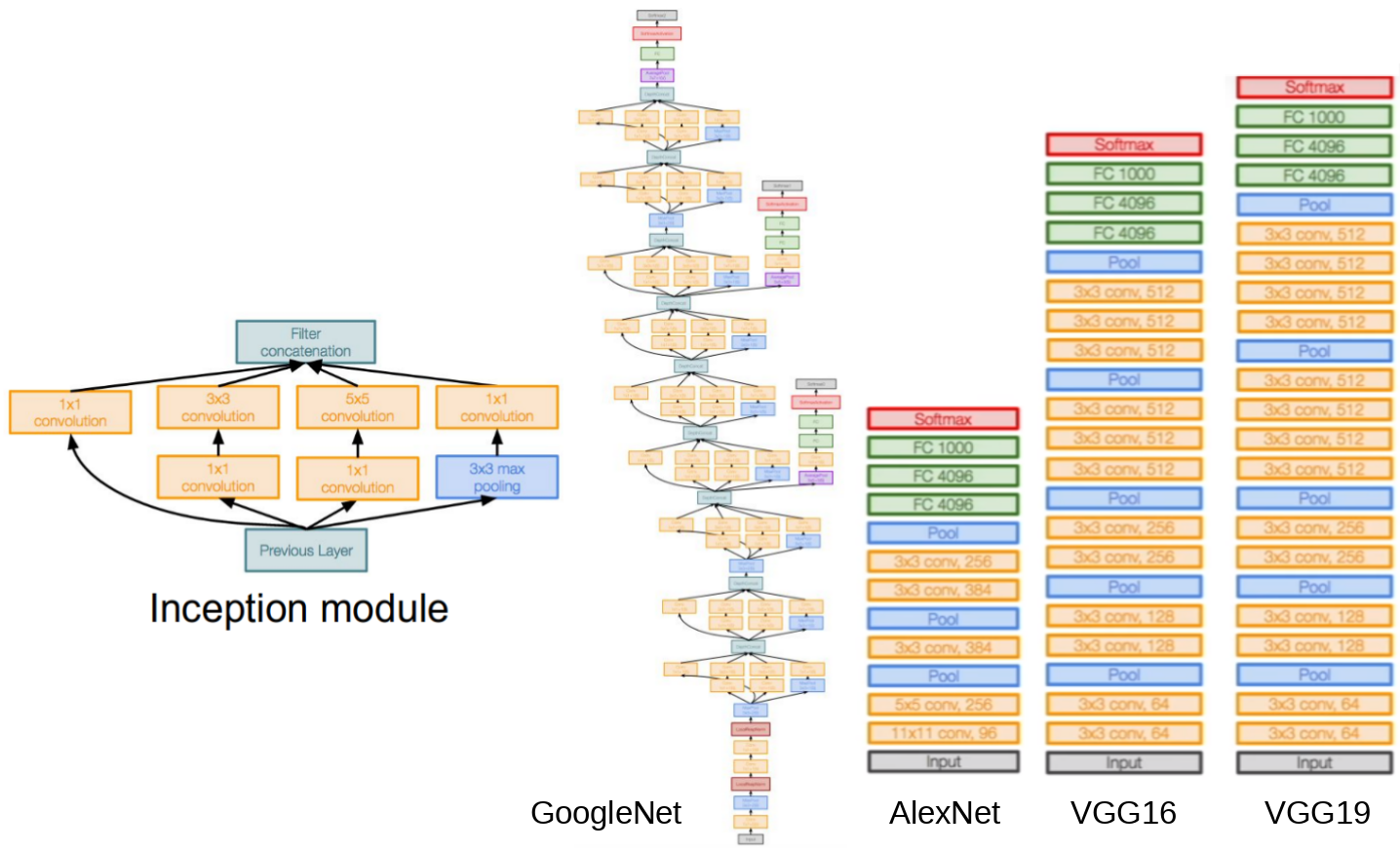
对上述所有的神经网络做了比较,GoogleNet 引入了 inception module 的概念,并去除了 FC 全连接层,让整个神经网络的参数少至只有约 5 百万个,甚至是只有 8 层神经网络的 AlexNet 参数量的 1/12,不止有效提升准确性,还提升效率。
Inception module
可以看成它为神经网络中的神经网络,为了让个别神经元里面的数据布局更为巧妙而设计。module 里面的内容主要就是平行处理多种不同尺寸的卷积核,和一个 Pooling operation,并且把个别输出结果堆叠起来成为下一层神经网络的输入数据。
但是要能够叠起来条件是尺寸要一样,因此越大的 filter matrix 就用 zero padding 的方式想办法把尺寸硬是维持成最小的 filter matrix 卷积出来的大小。不过随着层数增加,input 的“厚度”也会跟着越来越可怕,这将占用大量的计算资源。
解决办法使用 bottleneck filter,它和 1*1 卷积核是同个概念,用小于 input data 厚度的卷积核数做一次 CONV 让厚度变薄将大幅减轻计算负担,并不会对准确性造成什么影响。
完整 GoogleNet 结构如下:
- Stem Network: CONV >>> POOL >>> CONV >>> POOL
- Inception module
- 2.1 Auxiliary classification outputs 用于在较浅层的神经网络中插入额外的梯度 - Classifier output without FC layers
ResNet
这个 model 一共有 152 层神经网络,并且再一次击败所有对手,达到 3.57 的错误率,直接又低了 GoogleNet 一个层级,其全名叫做 Residual Net,使用的是 residual connections 的方法达到百余层的深度,同时还能够保证如此深的神经网络不会让效果打折扣。
The link of the published paper: https://arxiv.org/pdf/1512.03385v1.pdf

一般来说并不是越深的神经曾表现的越好,神经网络有个深度是好事,但是要是“太超过”了那效果反而事倍公半,越深层的 network 到后来越难做 optimization ,对于之前的神经网络技术来说,虽然有一些辅助算法能够让梯度不要爆炸或是消失,但是都没有根本上解决这个问题,只是可以让事情延迟发生罢了。
不过如果我们细想神经网络的深度与准确度的关系,逻辑上应该是可以让第 n 层的准确率在其下一层的时候维持,甚至做一定程度的改进的,随着层数越深,整个神经网络的错误率也应该跟着下降,ResNet 因此修改了计算方法,只 optimize 残差项,即第 n+1 层处理出来的 H(x) 与原本第 n 层的输入 x 相减得到的项 F(x) = H(x) - x,如图:

改进过的神经网络每一个 block 都有一个代表 shortcut 的 X identity,而原本通过神经网络 cell 用来算 H(x) 的调参机制则改成目标瞄准计算 F(x),只关注对 F(x) 参数上的优化,计算过程中如果出现 matrix 不匹配的情况,则使用 zero padding & 1*1 CONV 去补齐。
而一旦到了深层的神经网络中,由于前面累计的 input data 厚度可能会变得非常大,所以 ResNet 中也会套用到在 GoogleNet 介绍到的 bottleneck 方法,用 1*1 的 CONV 卷积核把整个厚度缩减,有利于节约计算资源。
神经网络细节补充:
- 残差网络原理讲解: https://blog.csdn.net/mao_feng/article/details/52734438
- 三种前沿神经网络: https://www.jiqizhixin.com/articles/2017-08-19-4
- ResNet及其变体(简书): https://www.jianshu.com/p/e96b473926ed
并且使用 ResNet 可以让整个资源的负载在有深层神经网络的情况下还很“轻”,同时保持物体鉴别的准确性,详细图表统计可以参考顶部链接之一的讲义 pdf。
等 ResNet 方法被提出来之后,它就被广泛应用到各个算法里面,排列组合互相搭配,深度或是广度的提升状况看最后输出结果是否得到更进一步的准确,其他神经网络架构如下:
- Network in Network (NiN) - 2014
在每个 cell 里面再放入 network 做运算,有点像是 GoogleNet 的感觉。 - Identity Mappings in Deep Residual Networks - 2016
基于 ResNet 做每个 block 的改进,多了一些 activation function 等处理手段。 - Wide Residual Networks - 2016
把原本深入运算的神经网络往广的方向扩展,提升准确性同时还节约计算资源。 - Aggregated Residual Transformations for Deep Neural Networks (ResNeXt) - 2016
基于广的方向扩展外,加上了 GoogleNet 的背后原理改进。 - Deep networks with Stochastic Depth
把层数提到很深,但是随机的去让一些单元参数归零不起作用,提升计算效率同时还可以有 dropout 的效果。

Else
- FractalNet: Ultra-Deep Neural Networks without Residuals - 2017
- Densely Connected Convolutional Networks - 2017
- SqueezeNet: AlexNet-level Accuracy with 50x Fewer Parameters and < 0.5mb model size - 2017