还是大佬勿怪啊 搬来给自己学习啊~~ 发了也没好处 就给自己有个分类留下而已哦~
模型转换还是挺重要的 感谢大佬~
Segment Anything Model(SAM)是Facebook Research近来开源的一种新的图像分割任务、模型,该模型被设计和训练为可提示的,因此它可以将zero-shot transfer零样本迁移到新的图像分布和任务。其分割效果较为惊艳,是目前分割SOTA的算法。关于该算法的详细细节网上有很多的解释,本文主要分享如何将该模型转换为TensorRT的模型,方便后期部署加速模型推理。
SAM代码:https://github.com/facebookresearch/segment-anything
SAM官网:https://segment-anything.com
本文TensorRT代码
https://github.com/BooHwang/segment_anything_tensorrt
简要介绍
Segment Anything Model (SAM)模型包含三个组件,如图1所示:图像编码器,提示编码器和掩码解码器。
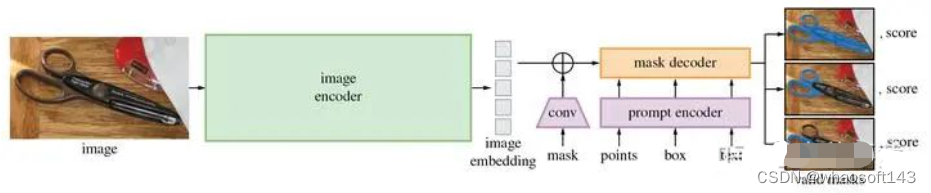 图1:分割一切模型(SAM)概述。重量级图像编码器输出图像嵌入,然后可以通过各种输入提示有效地查询,以平摊的实时速度产生对象掩码。对于对应于多个对象的模糊提示,SAM可以输出多个有效的掩码和相关的置信度分数。
图1:分割一切模型(SAM)概述。重量级图像编码器输出图像嵌入,然后可以通过各种输入提示有效地查询,以平摊的实时速度产生对象掩码。对于对应于多个对象的模糊提示,SAM可以输出多个有效的掩码和相关的置信度分数。
Image encoder图像编码器。受到可扩展性和强大的预训练方法的启发,使用了一个MAE预训练的Vision Transformer(ViT),最小化地适应处理高分辨率输入。图像编码器每个图像运行一次,并且可以在提示模型之前应用。
Prompt encoder提示编码器。考虑两组提示:稀疏(点,框,文本)和密集(掩码)。通过位置编码来表示点和框,这些编码与每种提示类型的学习嵌入相加,并且使用CLIP的现成文本编码器来表示自由文本。密集提示(即掩码)使用卷积嵌入,并与图像嵌入元素相加。
Mask decoder掩码解码器。掩码解码器通过有效地将image embedding图像嵌入,prompt embeddings提示嵌入和输出token映射到掩码来实现。这种设计采用了一个修改的Transformer解码器块,后跟一个动态掩码预测头。修改的解码器块使用提示自注意力和交叉注意力两个方向(提示到图像嵌入和反之亦然)来更新所有嵌入。在运行两个块之后,我们对图像嵌入进行上采样,并且MLP将输出令牌映射到动态线性分类器,然后在每个图像位置计算掩码前景概率。
模型转换流程
既然要提升效率,实现模型加速,那么具体应该怎么做呢?目前常用的深度学习模型加速的方法是:将pytorch/tensorflow等表示的模型转化为TensorRT表示的模型。TensorRT是NVIDIA公司出的能加速模型推理的框架,其实就是让你训练的模型在测试阶段的速度加快,比如你的模型测试一张图片的速度是50ms,那么用tensorRT加速的话,可能只需要10ms。有关TensorRT更详细的介绍,本文不做赘述,可自行参考官网。我将实现深度学习模型加速整体分成了两部分:
-
模型转换部分。实现 Pytorch/Tensorflow Model -> TensorRT Model 的转换。
-
模型推断(Inference)部分。利用 TensorRT Model 进行模型的 Inference。
如何由 Pytorch Model 得到对应的 TensorRT Model 呢?一般有两种方式:
-
借助 「torch2trt(https://github.com/NVIDIA-AI-IOT/torch2trt)」 进行转换;
-
「Pytorch -> onnx -> TensorRT」。这条路是使用最广泛的,首先将 Pytorch 模型转换为 ONNX 表示的模型;再将 ONNX 表示的模型转换为 TensorRT 表示的模型。这个方法也是本文重点介绍的方法。
Pytorch模型转ONNX模型
Pytorch -> ONNX 的转换比较简单,借助于 Pytorch 内置的API即可。
torch.onnx.export(model,
x,
"./ckpts/onnx_models/{}.onnx".format(model_name),
input_names=input_names,
output_names=output_names,
opset_version=16)
这里需要强调的一点是参数 「opset_version」 :由于onnx官方还在不断更新,目前只有一部分的pytorch算子能够进行转换,还有相当一部分算子是无法转换的。所以,我们在进行转换的时候,尽量选择最新版本的opset_version,来确保更多的算子能够被转换。目前ONNX官方(https://github.com/onnx/onnx/blob/main/docs/Operators.md)支持的算子及对应的版本。
ONNX模型转TensorRT模型
在进行 ONNX -> TensorRT 的转换之前,强烈建议使用onnx-simplifier(https://github.com/daquexian/onnx-simplifier)工具对转换过的ONNX模型进行简化,否则有可能在接下来的转换中报错。onnx-simplifier是一个对ONNX模型进行简化的工具,我们前面转换得到的ONNX模型其实是非常冗余的,有一些操作(比如IF判断)是不需要的,而这些冗余的部分在接下来的ONNX->TensorRT模型的转换中很可能会引起不必要的错误,同时也会增大模型的内存;因此,对其进行简化是很有必要的。
下面我们需要将ONNX模型转为TensorRT模型,首先需要再NVIDIA官网下载TensorRT-8.6.1.6工具包,解压在Ubuntu系统的用户根目录之下,设置好环境变量之后就可以使用到「官方工具trtexec」进行模型转换。该工具已经在之前下载的TensorRT文件夹中。
# 在python环境中安装TensorRT包
pip install ~/TensorRT-8.6.1.6/python/tensorrt-8.6.1-cp38-none-linux_x86_64.whl
# 设置环境变量
export PATH=$HOME/TensorRT-8.6.1.6/targets/x86_64-linux-gnu/bin:$PATH
export TENSORRT_DIR=$HOME/TensorRT-8.6.1.6:$TENSORRT_DIR
export LD_LIBRARY_PATH=$HOME/TensorRT-8.6.1.6/lib:$LD_LIBRARY_PATH
#输入命令
./trtexec --onnx=pytorch.onnx --saveEngine=pytorch.engine --workspace=4096
如果不报错的话,我们会得到一个名为pytorch.engine的模型,这就是转换得到的TensorRT模型。至此,模型转换部分全部结束。
模型转换
大致介绍完SAM模型的三个组件,接下来便是进入正题进行模型的转换工作,因为image embedding模型主要通过VIT进行特征提取,且该步骤仅进行一次,所以把该模块的模型单独进行转换,而将Prompt encoder和Mask decoder两个模型合并在一起进行模型转换。
Image embedding模型转为onnx
python scripts/onnx2trt.py --img_pt2onnx --sam_checkpoint weights/sam_vit_h_4b8939.pth --model_type default
Image embedding模块onnx模型转为TensorRT模型
trtexec --onnx=embedding_onnx/sam_default_embedding.onnx --workspace=4096 --saveEngine=weights/sam_default_embedding.engine
至此,我们得到了image embedding模块的TensorRT模型,该模块的模型输入和输出均为固定尺寸,因此转换过程基本没有太大问题。且该模型的功能是获得图像的特征,花费时间较长但只需要对图像提取一次,后续输入点或者框的提示时不需要重复提取,根据此特性可以很好的设计前后端的部署。
Prompt_Mask模块的Pytorch模型转换为ONNX模型
我们在上面讲过,Prompt编码和mask解码模型在embedding上进行操作,前期提取好一次image的embedding之后,只需要根据自己的意愿更换输入提示点和框的坐标即可,该部分的模型转换官方提供了一个脚本,只需要运行脚本即可获得onnx模型。
# clone官方代码
git clone https://github.com/facebookresearch/segment-anything
注意: 源代码中mask解码之后是一个低尺寸的mask,需要根据输入图的原始size进行恢复,但是这个原始size如果作为onnx转换时输入的节点,那么在TensorRT模型的转换时也需要输入该参数,并且固定一个长宽参数值,然而用户输入的图像尺寸是无法事先知道的,因此需要将该参数单独拎出来,也就是将低维度mask的后处理单独处理,不作为模型的一部分,因此需要稍微修改一下源代码:
# 修改"segment_anything/utils/onnx.py"中的"forward"函数为如下:
def forward(
self,
image_embeddings: torch.Tensor,
point_coords: torch.Tensor,
point_labels: torch.Tensor,
mask_input: torch.Tensor,
has_mask_input: torch.Tensor
# orig_im_size: torch.Tensor,
):
sparse_embedding = self._embed_points(point_coords, point_labels)
dense_embedding = self._embed_masks(mask_input, has_mask_input)
masks, scores = self.model.mask_decoder.predict_masks(
image_embeddings=image_embeddings,
image_pe=self.model.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embedding,
dense_prompt_embeddings=dense_embedding,
)
if self.use_stability_score:
scores = calculate_stability_score(
masks, self.model.mask_threshold, self.stability_score_offset
)
if self.return_single_mask:
masks, scores = self.select_masks(masks, scores, point_coords.shape[1])
return masks, scores
# upscaled_masks = self.mask_postprocessing(masks, orig_im_size)
# if self.return_extra_metrics:
# stability_scores = calculate_stability_score(
# upscaled_masks, self.model.mask_threshold, self.stability_score_offset
# )
# areas = (upscaled_masks > self.model.mask_threshold).sum(-1).sum(-1)
# return upscaled_masks, scores, stability_scores, areas, masks
# return upscaled_masks, scores, masks
模型修改好以上函数之后,接下来将sam_vit_h_4b8939.pth模型中的prompt编码和mask解码部分转为onnx模型。 whaosoft aiot http://143ai.com
# 下载default模型在库下的weights文件夹,并进行onnx模型的转换
python scripts/onnx2trt.py --prompt_masks_pt2onnx
注意: 在该模型转换过程中,opset version需要根据你的onnx版本进行匹配,否则在TensorRT模型转换环节会报错,这是一个很大的坑。
Prompt_Mask模块的ONNX模型转换为TensorRT模型
该环节因为输入中包含提示点和改点的正负性数量是可变的,也就是输入尺寸是动态的,所以在转换过程中需要设置多尺寸参数,具体如下:
trtexec --onnx=weights/sam_default_prompt_mask.onnx --workspace=4096 --shapes=image_embeddings:1x256x64x64,point_coords:1x1x2,point_labels:1x1,mask_input:1x1x256x256,has_mask_input:1 --minShapes=image_embeddings:1x256x64x64,point_coords:1x1x2,point_labels:1x1,mask_input:1x1x256x256,has_mask_input:1 --optShapes=image_embeddings:1x256x64x64,point_coords:1x10x2,point_labels:1x10,mask_input:1x1x256x256,has_mask_input:1 --maxShapes=image_embeddings:1x256x64x64,point_coords:1x20x2,point_labels:1x20,mask_input:1x1x256x256,has_mask_input:1 --saveEngine=weights/sam_default_prompt_mask.engine
完成以上流程之后,我们得到了两个TensorRT的加速engine文件,接下来就可以进行模型的推理任务,我们提供了该推理脚本:
python sam_trt_inference.py