根据《科创板日报》的独家消息,蚂蚁集团技术研发团队正在自研语言和多模态大模型——内部命名为“贞仪”,该项目获得了蚂蚁集团管理层高度重视,已启动数月。
多模态大模型指的是将文本、图像、视频、音频等多模态信息联合起来进行训练的模型。此前,OpenAI 联合创始人伊尔亚・苏茨克维 (Ilya Sutskever) 曾表示,“人工智能的长期目标是构建多模态神经网络,即 AI 能够学习不同模态之间的概念,从而更好地理解世界。”
值得一提的是,6 月 19 日,由清华大学计算机系教授、人工智能研究院副院长朱军带领的新团队完成了近亿级天使轮融资,由蚂蚁集团领投。这是自去年 11 月 ChatGPT 发布至今,蚂蚁集团投资的第一个 AIGC 项目。
目前业内比较知名的多模态大模型有 VisualGLM-6B 和 ImageBind。VisualGLM-6B 由清华大学知识工程和数据挖掘小组发布,是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共 78 亿参数。
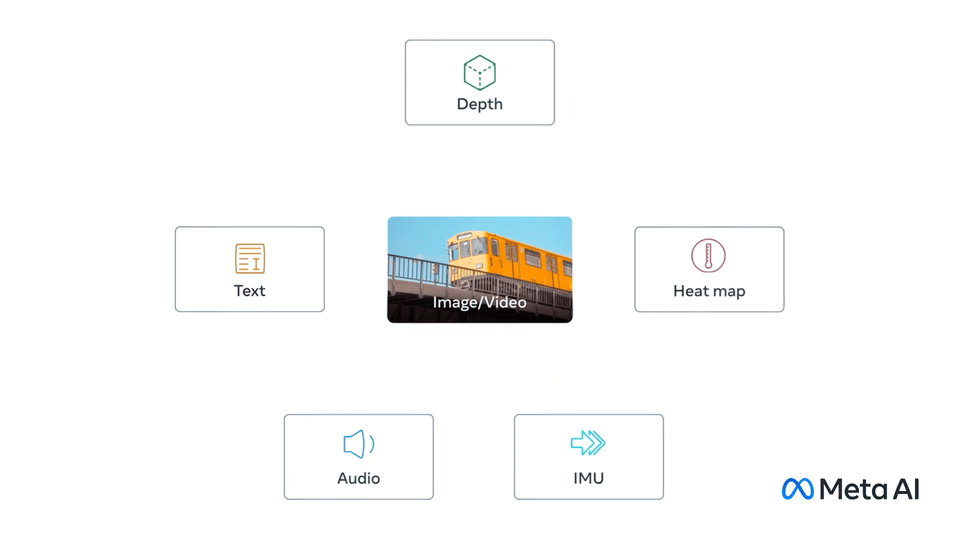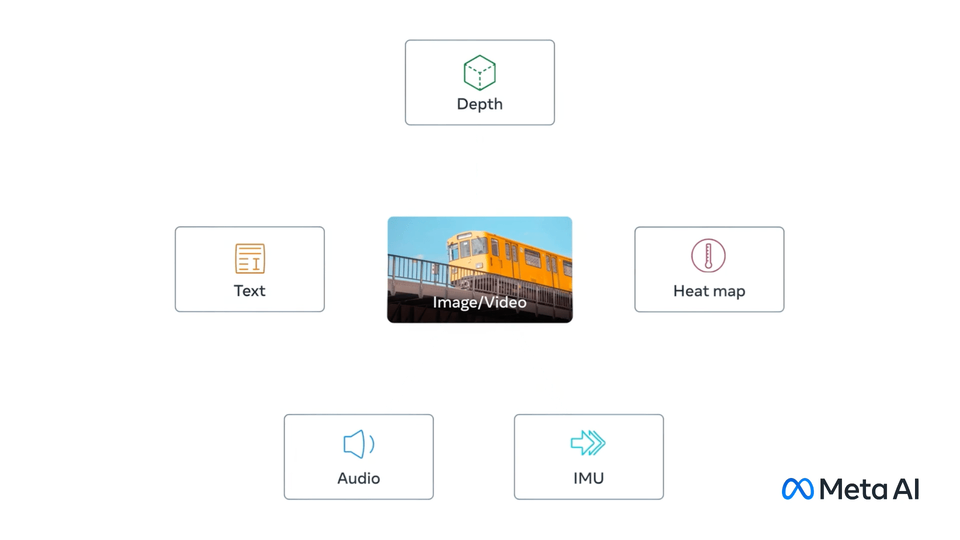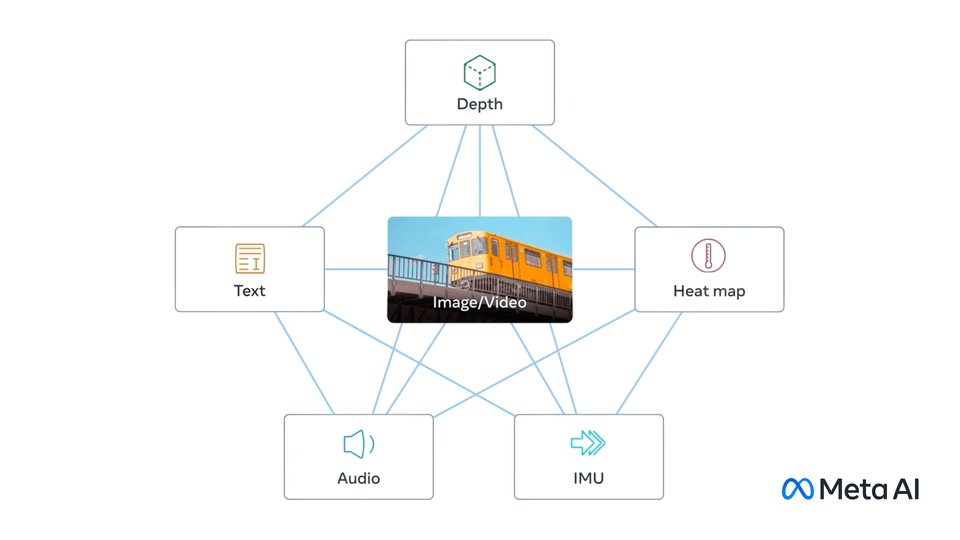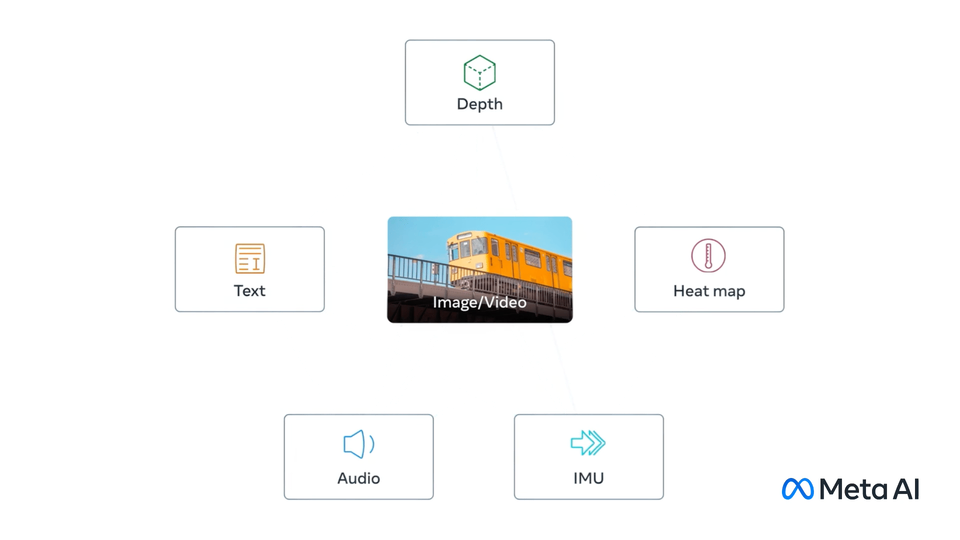
ImageBind 是 Meta 开源的多模态 AI 模型,它通过将文本、图像 / 视频和音频、视觉、温度还有运动数据流串联在一起,形成一个单一的 embedding space,让机器能从多维度来理解世界,也能创造沉浸式的多感官体验。