EPNet:用图像语义增强点特征用于三维物体检测
2020ECCV
代码地址:https://github.com/happinesslz/EPNet
论文地址:https://arxiv.org/pdf/2007.08856.pdf
0、摘要:
本文旨在解决三维检测任务中的两个关键问题,包括多传感器(即LiDAR点云和相机图像),以及定位和分类置信度之间的不一致性。为此,我们提出了一种新的融合模块,在不添加任何图像注释的情况下,以点为单位增强图像语义特征。此外,采用一致性强制损失的方法,明确地鼓励定位和分类置信度的一致性。我们设计了一个端到端可学习的EPNet框架来集成这两个组件。在KITTI和SUN-RGBD数据集上的大量实验证明了EPNet与最先进的方法相比的优越性。代码和模型可在https://github.com/happinesslz/EPNet获得。
然而,由于两个原因,融合激光雷达和相机图像的表示是一项不平凡的任务。一方面,它们具有高度不同的数据特征。另一方面,相机图像对光照、遮挡等敏感(如图1(b)所示),可能引入干扰信息,对三维目标检测任务有害。以往的工作通常是借助图像标注(即二维包围盒)来融合这两个传感器。根据利用传感器的不同方式,我们将以往的工作归纳为两大类,包括1)在不同阶段使用不同传感器的级联方法[27,37,42],2)联合对多传感器输入进行推理的融合方法[17,18]。这些方法虽然有效,但也有一些局限性。级联方法不能利用不同传感器之间的互补性,它们的性能受每个阶段的限制。融合方法[17,18]需要通过透视投影和体素化生成BEV数据,这不可避免地会导致信息丢失。此外,它们只能在体素特征和图像语义特征之间近似地建立相对粗糙的对应关系。我们提出了一个激光雷达引导的图像融合(LI-Fusion)模块来解决上述两个问题。LI-Fusion模块以逐点的方式建立原始点云数据与相机图像的对应关系,自适应估计图像语义特征的重要性。该方法利用有用的图像特征增强点特征,抑制干扰图像特征。与之前的方法相比,该方法具有四个主要优点:1)通过更简单的管道实现激光雷达与相机图像数据的细粒度点对应,无需复杂的BEV数据生成过程;2)保持原始几何结构,不丢失信息;3)解决摄像机图像可能带来的干扰信息问题;4)相对于以往的作品[27,18],不存在图像标注,即2D包围框标注。
除了多传感器融合外,我们还观察了分类置信度和定位置信度之间的不一致问题,定位置信度代表了一个物体是否存在于一个包围框中以及它与地面真实的重叠程度。如图1(c)所示,具有较高分类置信度的包围框反而具有较低的定位置信度。这种不一致性将导致检测性能下降,因为非最大抑制(Non-Maximum Suppression, NMS)过程会自动过滤掉重叠较大但分类置信度较低的框。然而,在三维检测任务中,这个问题很少被讨论。Jiang等人试图通过改进NMS过程来缓解这个问题。它们引入了一个新的分支来预测本地化置信度,并将NMS进程的阈值替换为分类置信度和本地化置信度的乘积。虽然这在一定程度上是有效的,但没有明确的约束来强制这两个信任的一致性。与[9]不同,我们提出了一种一致性强制丢失(CE丢失),以明确地保证这两个信任的一致性。在它的帮助下,具有高分类可信度的盒子被鼓励拥有与地面真相的大量重叠,反之亦然。这种方法有两个优点。首先,我们的解决方案易于实现,无需对检测网络的体系结构进行任何修改。其次,我们的解决方案完全不需要可学习参数和额外的推理时间开销。
我们的主要贡献如下:
1、我们的LI-Fusion模块直接对激光雷达点和相机图像进行处理,在不加图像注释的情况下,以点为方式,利用对应的语义图像特征有效地增强点特征。
2、我们提出了CE损耗,以提高分类和定位置信度之间的一致性,从而获得更准确的检测结果。
3、我们将LI-Fusion模块和CE损耗集成到一个新的框架EPNet中,在两个常用的三维目标检测基准数据集,即KITTI数据集[6]和SUN-RGBD数据集[33]上取得了最先进的结果。
2 相关工作
基于摄像机图像的三维目标检测。最近的三维目标检测方法主要关注相机图像,如单眼图像[23,29,12,15,20]和立体图像[16,35]。Chen et al.[1]利用基于cnn的对象检测器获取2D包围盒,并利用语义、上下文和形状信息推断出相应的3D包围盒。Mousavian等人利用射影几何约束,从物体的二维包围盒估计定位和方向。然而,基于相机图像的方法由于缺乏深度信息,难以生成精确的三维包围框。

基于激光雷达的三维目标检测。近年来提出了许多基于激光雷达的方法[39,24,40]。VoxelNet[43]将点云划分为体素,并使用堆叠的体素特征编码层提取体素特征。第二个[38]引入了稀疏卷积运算,提高了[43]的计算效率。PointPillars[14]将点云转换为伪图像,并消除了耗时的3D卷积操作。PointRCNN[31]是一种开创性的两级检测器,由区域提议网络(RPN)和改进网络组成。RPN网络预测前景点并输出粗边界框,然后由精化网络对粗边界框进行精化。然而,激光雷达数据通常非常稀少,这对精确定位提出了挑战。
基于多传感器的三维物体检测。近年来,相机图像、激光雷达等多传感器的开发取得了很大进展。Qi等人[27]提出了一种F-PointNet级联方法,该方法首先从相机图像生成2D提案,然后根据LiDAR点云生成相应的3D盒子。然而,级联方法需要额外的2D注释,它们的性能受到2D检测器的限制。许多方法试图对摄像机图像和BEV进行联合推理。MV3D[3]和AVOD[11]通过融合每个ROI区域的BEV和相机特征图对检测框进行细化。混淆[18]提出了一种新的连续融合层,实现了BEV与图像特征映射的体素方向对齐。与之前的工作不同,我们的LI-Fusion模块直接对激光雷达数据进行操作,并在激光雷达和相机图像特征之间建立更精细的逐点对应关系。
3 方法
利用多传感器的互补信息对精确的三维目标检测具有重要意义。此外,该方法对于解决定位与分类置信度不一致造成的性能瓶颈也具有重要意义。
在本文中,我们提出了一种新的框架EPNet,从这两个方面来提高三维检测性能。EPNet由一个用于生成提案的两个流RPN和一个用于边界框优化的精细化网络组成,该精细化网络可以端到端训练。双流RPN通过LI-Fusion模块有效地结合了激光雷达点特征和语义图像特征。此外,我们还提供了一致性强制损耗(CE loss)来提高分类和定位置信度之间的一致性。在下文中,我们分别在3.1小节和3.2小节中给出了双蒸汽RPN和精化网络的细节。然后我们在第3.4小节中详细说明CE损耗和总体损耗函数。
3.1双流RPN
我们的双流RPN由一个几何流和一个图像流组成。如图2所示,几何流和图像流分别生成点特征和语义图像特征。我们采用多个LI-Fusion模块,在不同尺度上用相应的语义图像特征增强点特征,从而得到更有区别的特征表示。
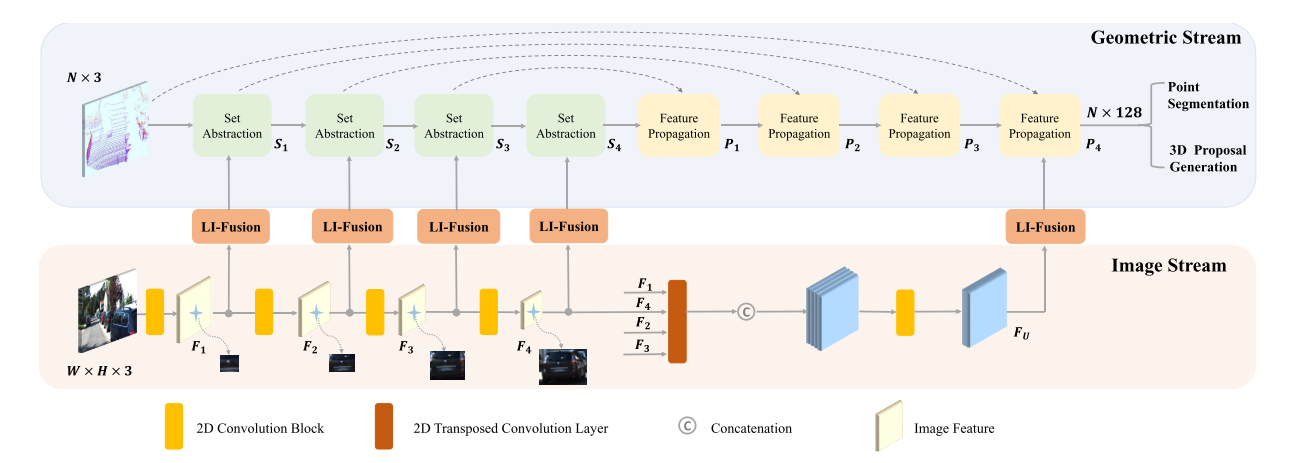
图二。由几何流和图像流组成的双流RPN的体系结构。利用LI-Fusion模块在多尺度上增强激光雷达点特征与相应的语义图像特征。N为LiDAR点数。H和W分别表示输入相机图像的高度和宽度。
图像流。图像流以摄像机图像为输入,通过一组卷积运算提取图像语义信息。我们采用了一个特别简单的结构,由四个轻量级的卷积块组成。每个卷积块由两个3×3卷积层、一个批处理归一化层[8]和一个ReLU激活函数组成。我们用每个block中设置第二个卷积层步长为2,扩大接收域,节省GPU内存。Fi (i=1,2,3,4)表示这四个卷积块的输出。如图2所示,Fi提供了足够的语义图像信息,丰富了不同尺度的LiDAR点特征。我们进一步采用4个不同步长的平行转置卷积层来恢复图像分辨率,得到与原始图像大小相同的特征图。我们将它们串联起来,得到一个更有代表性的特征映射傅里叶,该特征映射包含丰富的语义图像信息,具有不同的接受域。如后面所示,特征图也被用来增强LiDAR点特征,以生成更精确的提议。
几何流。几何流以激光雷达点云为输入,生成三维提议。几何流由四对:集合抽取(SA)[28]层和特征传播(FP)[28]层组成,用于特征提取。为了描述方便,SA层和FP层的输出分别记为Si和Pi (i=1、2、3、4)。如图2所示,我们借助LI-Fusion模块将点特征Si和语义图像特征Fi结合起来。此外,对点特征P4进行多尺度图像特征的进一步丰富,得到一种紧凑且具有判别性的特征表示,然后将该特征表示送入检测头进行前景点分割和三维提案生成。
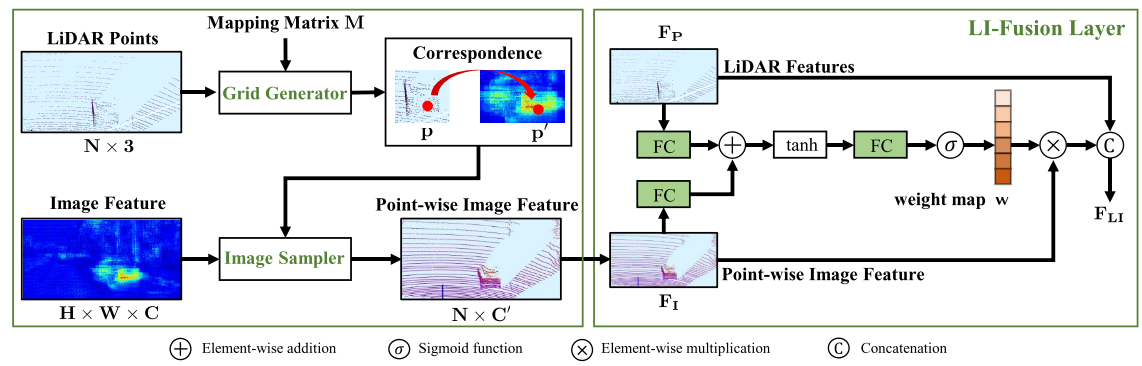
图3。LI-Fusion模块的示意图,包括一个网格生成器,一个图像采样器和一个LI-Fusion层。
LI-Fusion模块。激光雷达引导的图像融合模块由网格生成器、图像采样器和LI-Fusion层组成。如图3所示,LI-Fusion模块包括两部分,即逐点对应生成和激光雷达引导融合。具体来说,我们将LiDAR点投影到相机图像上,将映射矩阵表示为M。网格生成器以LiDAR点云和映射矩阵M为输入,输出不同分辨率下LiDAR点与相机图像的逐点对应关系。具体来说,对于点云中特定的点p(x, y, z),可以得到其在相机图像中对应的位置,可以写成:

其中M的大小为3 × 4。注意,在投影处理公式(1)中,我们将和p转换为齐次坐标下的三维和四维向量。
在建立对应关系后,我们提出使用图像采样器来获取每个点的语义特征表示。具体来说,我们的图像采样器将采样位置和图像特征映射F作为输入,为每个采样位置生成逐点图像特征表示V。考虑到采样位置可能在相邻像素之间,我们采用双线性插值得到连续坐标下的图像特征,可以表示为:
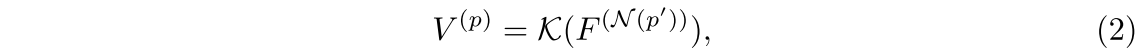
其中V(p)为点p对应的图像特征,K为双线性插值函数,F(N())为采样位置
邻近像素的图像特征。
由于相机图像受到光照、遮挡等诸多因素的挑战,融合激光雷达特征和逐点图像特征是非简单的。在这些情况下,逐点图像特征将引入干扰信息。为了解决这个问题,我们采用了一种激光雷达引导的融合层,利用激光雷达的特征,以逐点的方式自适应地估计图像特征的重要性。如图3所示,我们首先将LiDAR特征FP和逐点特征FI馈送到一个全连接层中,并将它们映射到同一通道中。然后我们将它们相加形成一个紧凑的特征表示,然后通过另一个全连接层压缩成一个单通道的权值图w。我们使用一个sigmoid激活函数将权重映射w归一化到[0,1]的范围内。
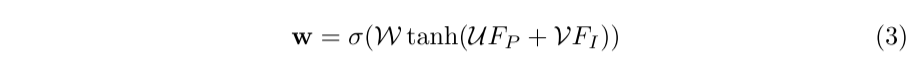
其中W, U, V表示LI-Fusion层中的可学习权矩阵。σ为s型激活函数。
在得到权值映射w后,我们将LiDAR特征FP和语义图像特征FI串联起来,可以表示为:
![]()
(简单概括,融合的特征会产生一个权值,权值影响图像特征最终的比例)
3.2 精细化网络Refinement Network
我们使用NMS过程来保持高质量的建议,并将它们提供给细化网络。对于每个输入建议,我们通过在两流RPN的最后一个SA层上的相应包围框中随机选择512个点来生成其特征描述符。对于那些小于512个点的提议,我们只需用0填充描述符。该精细网络由三层SA层和两个子网组成,分别用于提取紧凑的全局描述符和两个级联1×1卷积层的分类和回归。
3.3 一致性加强损失Consistency Enforcing Loss
普通的3D物体检测器通常会生成比场景中真实物体数量更多的边界框。如何选择高质量的边框是一个很大的挑战。NMS试图根据不满足要求的边界框的分类可信度来过滤它们。在这种情况下,假设分类置信度可以作为边界真理与地面真理之间真实借据的代理,即定位置信度。然而,分类置信度和定位置信度往往不一致,导致性能不佳。
这促使我们引入一致性强制损失,以确保本地化置信度和分类置信度之间的一致性,从而使具有高本地化置信度的盒子具有高分类置信度,反之亦然。一致性加强损失的写法如下: 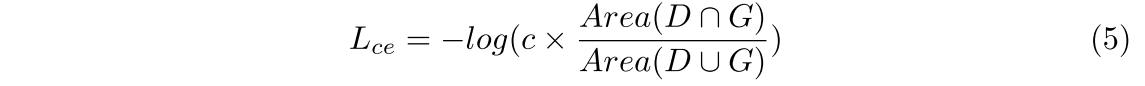
其中D和G表示预测的包围盒和地面真值。c为d的分类置信度。为了优化该损失函数,分类置信度和定位置信度(即IoU)分别为其中D和G表示预测的包围盒和地面真值。c为d的分类置信度。为了优化该损失函数,我们鼓励分类置信度和定位置信度(即IoU)共同尽可能高。因此,重叠较大的盒子将具有较高的分类可能性,并保留在NMS过程中。欠条损失的关系。我们的CE损失与公式中IoU损失[41]相似,但动机和作用完全不同。IoU loss试图通过优化IoU度量来生成更精确的回归,而CE loss旨在确保定位和分类置信度之间的一致性,以帮助NMS过程保持更精确的边界盒。虽然公式简单,但4.3节的定量结果和分析证明了我们的CE损耗在保证一致性和提高3D检测性能方面的有效性。
3.4 整体损失函数Overall Loss Function
利用多任务损失函数对两流RPN和精化网络进行联合优化。总损失可表示为:

式中,Lrpn和Lrcnn表示两流RPN和精化网络的训练目标,两流RPN和精化网络的优化目标相似,包括分类损失、回归损失和CE损失。我们采用焦点损耗[19]作为分类损耗,在α = 0.25和γ = 2.0的条件下平衡正负样本。对于包围框,网络需要回归其中心点(x, y, z)、尺寸(l, h,w)和方向θ。
由于y轴(垂直轴)的范围相对较小,所以我们直接使用平滑的L1损失[7]来计算它对地面真相的偏移量。同样,包围盒的大小(h,w, l)也进行了优化,使L1损失平滑。对于x轴、z轴和方向θ,我们采用基于bin的回归损失[31,27]。对于每个前景点,我们将其邻近区域分割为几个箱子。基于仓的损失首先预测中心点落在哪个仓,然后回归仓内的剩余偏移量ru。损失函数的表达式如下:
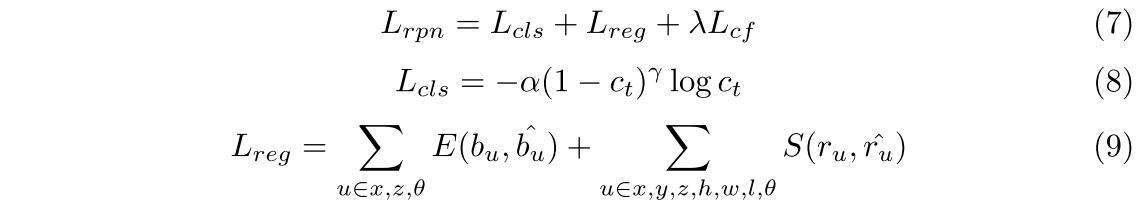
4 实验Experiments
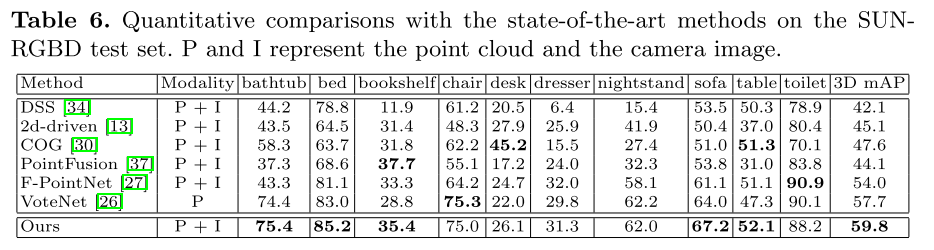
我们利用KITTI数据集[6]和SUN-RGBD数据集[33]对该方法进行了评价。KITTI是一个室外数据集,而SUN-RGBD则是室内场景的数据集。在接下来的4.1小节中,我们首先简要介绍了这些数据集。然后我们在第4.2小节中提供实施细节。对LI-Fusion模块和CE损耗的综合分析在4.3小节中进行了阐述。最后,我们在第4.4小节和第4.5小节分别展示了在KITTI数据集和SUN-RGBD数据集上与最先进的方法的比较。
4.1数据集和评价指标
KITTI数据集是自动驾驶的标准基准数据集,包含7481帧训练帧和7518帧测试帧。遵循与[27,31]相同的数据集分割协议,将7481帧进一步分割为3,712帧用于训练,3,769帧用于验证。在我们的实验中,我们提供了所有三个难度级别的验证和测试集的结果,即简单、中等和困难。根据大小、遮挡和截断情况,对象被划分为不同的难度级别。
SUN-RGBD数据集是三维目标检测的室内基准数据集。该数据集由10,335幅图像和700个标注对象类别组成,其中5,285幅图像用于训练,5,050幅图像用于测试。在之前的工作[37,27]之后,我们在测试集中报告了10个主要对象类别的结果,因为这些类别的对象相对较大。
度量。我们采用平均精度(AP)作为度量标准,遵循KITTI数据集和SUN-RGBD数据集的官方评估协议。最近,KITTI数据集应用了一种新的评估协议[32],该协议使用40个召回位置,而不是以前的11个召回位置。因此,它是一个更公平的评估协议。在这个新的评估方案下,我们比较了我们的方法和最先进的方法。
4.2实现细节
网络设置。双流RPN以激光雷达点云和摄像机图像作为输入。对于每个三维场景,LiDAR点云沿摄像机坐标X(右)轴、Y(下)轴、Z(前)轴的距离分别为[- 40,40]、[- 1,3]、[0,70.4]m。θ的方向在[-π, π]范围内。我们从原始LiDAR点云中对16384个点进行子采样,作为几何流的输入,与PointRCNN[31]相同。图像流以分辨率为1280 × 384的图像作为输入。我们采用四组抽象层对输入的LiDAR点云进行子采样,大小分别为4096、1024、256和64。利用四个特征传播层恢复点云的大小,用于前景分割和三维提案生成。类似地,我们使用四个带有stride 2的卷积块对输入图像进行下采样。此外,我们还采用了四种步幅为2,4,8,16的并行转置卷积来恢复不同尺度下特征地图的分辨率。在NMS过程中,我们根据两个流RPN生成的盒的分类置信度,选择其最顶端的8000个盒。然后,我们以网管阈值0.8过滤冗余框,得到64个正候选框,由细化网络对其进行细化。对于这两个数据集,我们为上面讨论的两流RPN采用了类似的体系结构设计。
训练计划。我们的两流RPN和精化网络是端到端可训练的。在训练阶段,回归损失Lreg和CE损失仅适用于正向提案,即RPN阶段由前景点生成的提案,RCNN阶段与ground truth共享IoU大于0.55的提案。
参数优化。采用自适应矩估计(Adam)[10]对网络进行优化。初始学习率、权值衰减和动量因子分别设置为0.002、0.001和0.9。我们在4个Titan XP gpu上以端到端方式对模型进行大约50个epoch的训练,批处理大小为12。损失函数中的平衡权值λ设置为5。
数据扩充。为了防止过拟合,采用了三种常用的数据增强策略,包括旋转、翻转和缩放变换。首先,我们在[−π/18, π/18]范围内沿垂直轴随机旋转点云。然后,点云沿着前向轴随机翻转。此外,每个ground真值盒都是按照[0.95,1.05]的均匀分布随机缩放的。许多基于lidar的方法从整个数据集中采样地面真实盒子,并将它们放入原始的3D帧中,以模拟后面有拥挤物体的真实场景[43,38]。这种数据增强方法虽然有效,但需要获取道路平面的先验信息,而道路平面的先验信息对于各种真实场景来说是很难获得的。因此,我们没有在我们的框架中利用这种增强机制的适用性和通用性。
4.3消融
我们在KITTI验证数据集上进行了大量的实验,以评估LI-Fusion模块的有效性和CE损耗。
融合架构分析。为了验证LI-Fusion模块的有效性,我们删除了所有LI-Fusion模块。如表1所示,加入LI-Fusion模块后,3D mAP的性能提高了1.73%,证明了其结合点特征和图像语义特征的有效性。我们在表2中进一步比较了两种不同的融合方案。一种替代方法是简单的连接(SC)。我们将几何流的输入修改为原始相机图像和激光雷达点云的组合,而不是它们的特征表示。具体来说,我们将相机图像的RGB通道拼接到激光雷达点云的空间坐标通道上。值得注意的是,SC没有采用图像流。另一种选择是单尺度(SS)融合,它与我们的双流RPN具有类似的结构。不同的是,我们去掉了集合抽象层中的所有LI-Fusion模块,只保留最后一个特征传播层中的LI-Fusion模块(见图2)。如表2所示,SC生成的3D mAP比基线下降0.28%,说明在输入级的简单组合不能提供足够的指导信息。此外,我们的方法优于SS的3D mAP 1.31%。说明了LI-Fusion模块在多尺度下应用的有效性。
学习到的语义图像特征的可视化。需要注意的是,我们在双流RPN的图像流中没有添加明确的监督信息(如二维检测框的注释)。图像流与几何流一起优化,并从两流RPN的末端获取三维盒的监控信息。考虑到相机图像和LiDAR点云的不同数据特征,我们将图像语义特征可视化,以了解图像流学习的内容,如图4所示。虽然没有使用明确的监督,但令人惊讶的是,图像流很好地区分了前景对象和背景,并从相机图像中提取了丰富的语义特征,证明了LI-Fusion模块准确地建立了激光雷达点云和相机图像之间的对应关系,从而可以为点特征提供互补的语义图像信息。值得注意的是,图像流主要集中在前景对象的代表区域,光照较差的区域与邻近区域表现出非常明显的特征,如红色箭头所示。这表明,由于光照条件的变化可能会引入有害的干扰信息,因此有必要自适应估计图像语义特征的重要性。因此,下面我们进一步对语义图像特征的权值图w进行分析。

LI-Fusion层权值图分析。在真实场景中,相机图像通常会受到光照的干扰,出现曝光不足和曝光过度的问题。为了验证权值映射w在缓解不满意的相机图像带来的干扰信息方面的有效性,我们通过改变相机图像的照度来模拟真实环境。对于KITTI数据集中的每一张图像,我们通过变换y = a∗x+b模拟光照变化,其中x和y表示像素的原始和转换后的RGB值。A和b分别表示系数和偏移量。我们随机地放松(回应。将KITTI数据集中的相机图像设置为3(响应。0.3)和b至5。定量结果见表3。为了进行比较,我们删除了图像流,并使用基于仅LiDAR的模型作为基线,得到了83.87%的3D mAP。我们还提供了将RGB坐标和LiDAR坐标在输入级(SC)上简单拼接的结果,导致了性能明显下降1.08%,说明了图像质量差对三维检测任务是有害的。此外,我们的方法没有估计权值图w,也导致了0.69%的下降。然而,在权重图w的指导下,我们的方法比基线提高了0.65%。这意味着引入权值图可以自适应地选择有利的特征,而忽略那些有害的特征。
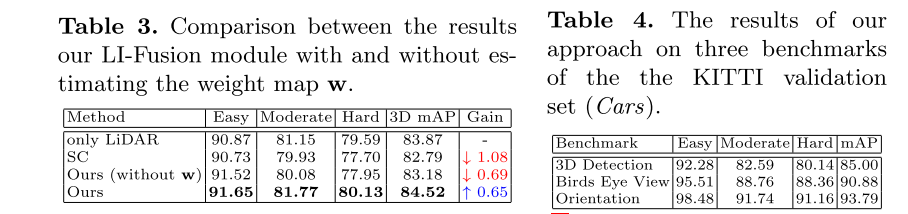
CE损耗分析。如表1所示,添加CE损耗比基线显著提高了3.93%。并与欠条损失进行了定量比较,验证了CE损失在提高三维检测性能方面的优越性。如图5(a)所示,CE丢失导致3D mAP比IoU丢失提高了1.28%,这说明在3D检测任务中保证分类和定位置信度的一致性是有好处的。
为了弄清楚这两个置信区间之间的一致性是如何提高的,我们对CE损失进行了全面的分析。为了描述方便,我们将重叠大于预定义IoU阈值τ的预测框表示为正候选框。此外,我们采用另一个阈值υ来过滤具有较小分类置信度的正候选框。因此,一致性可以用R与保留的正候选框数的比值来评价,可以写成:
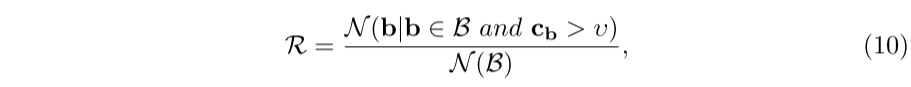
4.4 KITTI实验
表5给出了KITTI测试集上的定量结果。在3D mAP方面,本文方法比基于多传感器的方法F-PointNet[27]、MV3D[3]、AVOD-FPN[11]、PC-CNN[5]、ContFuse[18]和MMF[17]的性能分别提高了10.37%、17.03%、7.71%、6.23%、9.85%和2.55%。需要注意的是,MMF[17]利用多种辅助任务(如2D检测、地面估计和深度完井)来提高3D检测性能,这需要很多额外的注释。这些实验一致表明,我们的方法优于级联方法[27],以及基于roi[3,11,5]和基于体素[18,17]的融合方法。
我们还在表4中提供了KITTI验证分离的定量结果,以便与未来的工作进行比较。此外,我们在补充资料中给出了KITTI验证数据集的定性结果。
5总结
我们提出了一种新的三维物体检测器EPNet,它由一个双流RPN和一个改进网络组成。利用LI-Fusion模块,将激光雷达点云和相机图像等不同的传感器结合在一起,有效地增强了点特征。此外,通过提出的CE损耗来解决分类置信度与定位置信度不一致的问题,明确地保证了定位置信度与分类置信度的一致性。大量的实验已经验证了LI-Fusion模块的有效性和CE损耗。未来,我们将探讨如何利用激光雷达点云的深度信息来增强图像特征表示,以及在二维检测任务中的应用。
自己总结
创新
1、融合方式,融合后的特征自己充当权值影响图像的拼接。整个融合过程也是很清晰的。
2、改进损失函数,使得类别和位置得以平衡
存在疑问
这个结构最终应该是个双头结构,一个是3D网格一个是点云分割,点云分割的结果和结构不知道对应的是哪部分,欢迎探讨~