Deep Hough Voting for 3D Object Detection in Point Clouds
点云中三维目标检测的深度Hough投票法
PS:
pointnet:由于其maxpooling操作得到的全局特征,使分类任务效果很好;
对分割任务,将全局特征和之前学习到的各点云的局部特征进行拼接,再通过mlp得到每个点的分类结果。
Pointnet++:是对之前pointnet的补充升级版,pointnet局部特征提取能力较差,这使得它很难对复杂场景进行分析。
pointnet++借鉴了CNN的多层感受野的思想,先对点云进行采样和区域划分,在各个小区域内用pointnet网络进行特征提取,不断迭代。
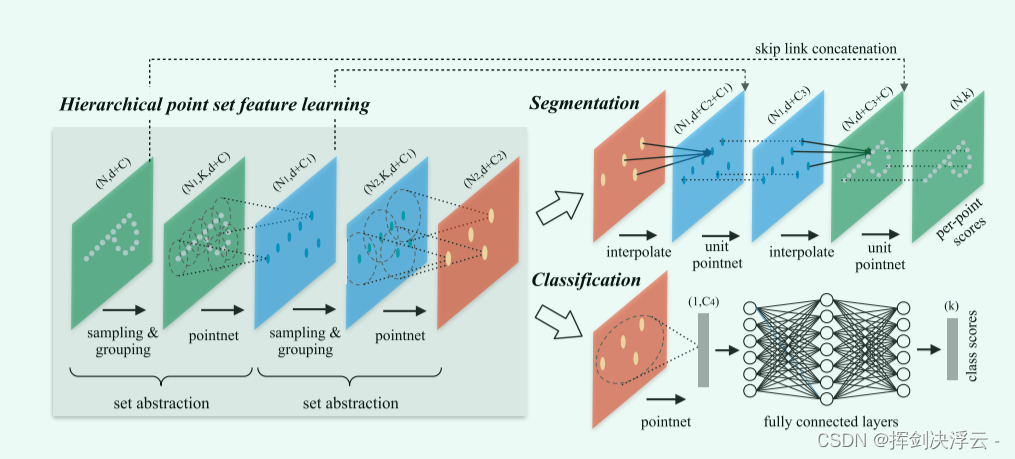
网络结构如下:
1、Sample layer:主要是对输入点进行采样,在这些点中选出若干个中心点,利用的使FPS最远点采样,保证采样点均匀分布在整个点云集上。
2、grouping layer:利用上一层得到的中心点将点集划分成若干个区域。
3、PointNet layer:对这些点用MLP提取特征并最大池化聚合为采样点坐标。
在set abstraction里面,用到了多尺度的特征提取做一个优化,把小的一些特征和大的拼接起来(不同半径),提升泛化能力。
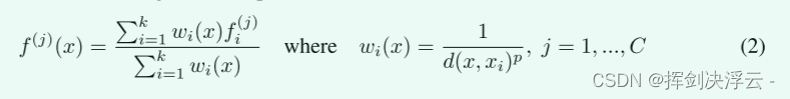
对于分割任务做的优化,我们要做的事是对每个点都做一个语义分割的标签,网络中,我们首先做一个上采样,怎么做的?这是通过做一个插值实现的,采用基于距离的插值和跨级跳跃链接的分层传播策略,在众多插值选择中,我们使用基于 k 个最近邻的反距离加权平均值(如公式 2 ,默认情况下我们使用 p = 2,k = 3)。它会根据邻域中K个点的距离以及点的特征做一个加权平均,插值后是在向全局特征还原,我们还要将这些特征去和之前的局部特征做拼接,然后继续往后做点特征传播,这样重复该过程,直到我们将特征传播到原始点集,再做语义分割任务,效果是会更好的。
VoteNet:
想做什么:
为点云数据构建了一个尽可能通用的 3D 检测结构
提出背景:
3D 对象检测的目标是定位和识别 3D 场景中的对象,更具体地说,在这项工作中,我们的目标是估计定向 3D 边界框以及来自点云的对象的语义类别。
然而,当前的 3D 目标检测方法受 2D 检测器的影响很大,把一些2D 检测框架扩展到 3D,比如将 Faster 或 Mask R-CNN 等 2D 检测框架扩展到 3D,将不规则的点云体素化为规则的 3D 网格并应用 3D CNN 检测器,这无法利用数据中的稀疏性,并且由于昂贵的 3D 卷积而受到高计算成本的影响。
或是将点云数据投影为规则的 2D 鸟瞰图像,然后应用 2D 检测器定位对象。然而,这牺牲了在杂乱的室内环境中可能至关重要的几何细节,图像视觉转换需要额外的计算开销。
本文介绍了一个以点云为中心的 3D 检测框架,该框架直接处理原始数据,并且在架构和对象提议中都不依赖于任何 2D 检测器。我们的检测网络 VoteNet 基于点云 3D 深度学习模型的最新进展,并受到用于对象检测的广义 Hough 投票过程的启发
遇到的问题:
然而,由于数据的稀疏性,直接从场景点预测边界框参数时面临一个主要挑战:一个 3D 物体的质心可能远离任何表面点,因此很难用一个步骤准确地回归。
解决方案:
利用霍夫投票,首先在输入点云上采样若干seed点并vote其所属目标的中心点,这样可以得到很多靠近该目标中心的vote点,然后在vote点上提出bounding box 的建议,很好地解决了目标中心点离表面点很远时不准确的缺陷
网络架构图:
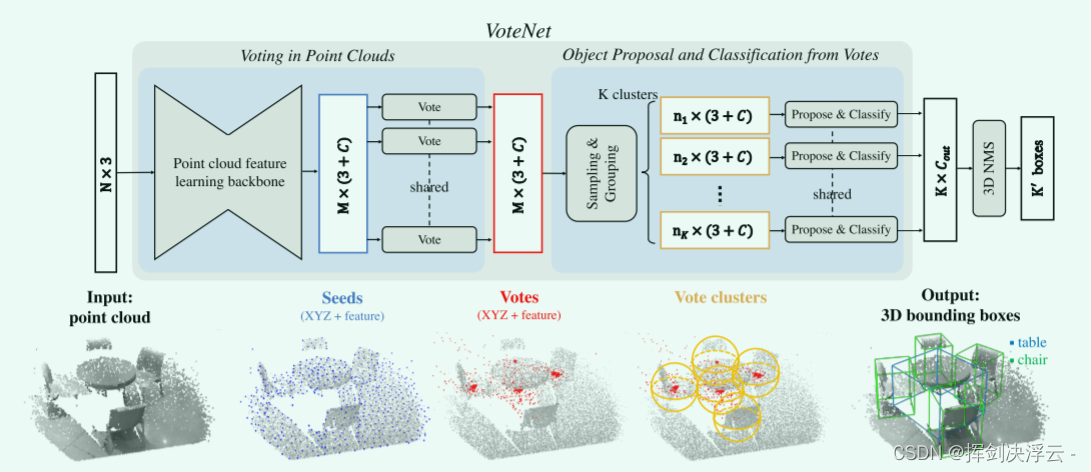
首先,通过pointnet++提取原先场景中点云的一个信息,我们要找出目标物体的bondingbox的话,是要确定一个物体中心点的,由于我们点云是物体表面信息的一个表示,中心一定是额外确定的,我们用霍夫投票机制挑出这些候选点,得到原先不存在于点云数据中的一些中心点的提议(原文叫proposal),有了这些点后,就继续用pointnet++里的sampling和grouping去最远点采样出K个聚类中心,划分出球形空间,利用mlp对这些聚类提取出代表他们的特征向量,然后就是对这些向量预测一个类别标签,包括bondingbox应该框在哪里。
待完善。。。。。。