《机器学习公式推导与代码实现》学习笔记,记录一下自己的学习过程,详细的内容请大家购买作者的书籍查阅。
决策树
决策树(decision tree)基于特征对数据实例按照条件不断进行划分,最终达到分类或回归的目的。
本章作者主要介绍如何将决策树用于分类模型。
决策树模型预测的过程既可以看作一组if-then条件的集合,也可以视为定义在特征空间与类空间中的条件概率分布。
决策树模型的核心概念包括特征选择方法、决策树构造过程、决策树剪枝。常见的特征选择方法包括信息增益、信息增益比和基尼指数(Gini index),对应的三种常见的决策树算法为ID3、C4.5和CART。
可以从两种视角来理解决策树模型,第一种是将决策树看作一组if-then规则的集合,为决策树的根节点到叶子结点的每一条路径都构建一条规则,路径中的内部结点特征代表规则条件,而叶子结点表示这条规则的结论。一棵决策树所有的if-then规则都互斥且完备。if-then规则本质上是一组分类规则,决策树学习的目标就是基于数据归纳出这样一组规则。
第二种是从条件概率分布的角度来理解决策树。假设将特征空间划分为互不相交的区域,且每个区域定义的类的概率分布就构成了一个条件概率分布。决策树所表示的条件概率分布是由各个区域给定类的条件概率分布组成的。假设X为特征的随机变量,Y为类的随机变量,相应的条件概率分布表示为P(Y|X),当叶子结点上的条件概率分布偏向某一类时,那么属于该类的概率就比较大。
我们的学习目标是找到一棵能够最大可能正确分类的决策树,但是为了保证泛化性,我们需要这棵决策树不能过于正确,在正则化参数的同时最小化经验误差。
决策树学习的目标就是最小化这个损失函数:
L a ( T ) = ∑ t = 1 ∣ T ∣ N t H t ( T ) + α ∣ T ∣ L_{a}\left ( T \right ) = \sum_{t=1}^{\left | T \right | } N_{t}H_{t}\left ( T \right ) +\alpha\left | T \right | La(T)=t=1∑∣T∣NtHt(T)+α∣T∣
H(t)是叶子结点上的经验熵(empirical entropy),a≥0为正则化参数,t为树T的叶子结点,每个叶子节点有Nt个样本。
1 特征选择
为了构建一棵分类性能良好的决策树,我们需要从训练集中不断选取具有分类能力的特征。如果用一个特征对数据集进行分类的效果与随机选取的分类效果并无差异,我们可以认为该特征对数据集的分类能力是低下的;反之如果一个特征能够使得分类后的分支结点尽可能属于同一类别,即该结点有着较高的纯度(purity),那么该特征对数据集而言就具备较强的分类能力。
在决策树中,我们有三种方式来选取最优特征,包括信息增益、信息增益比和基尼指数。
1.1 信息熵(information entropy)
在信息论和概率统计中,熵是一种描述随机变量不确定性的度量方式,也可以用来描述样本集合的纯度,信息熵越低,样本不确定性越小,相应的纯度就越高。
假设当前样本数据集D中第k个类所占比例为Pk(k=1,2…Y),那么该样本数据集的熵可定义为:
E ( D ) = − ∑ k = 1 Y p k log p k E\left ( D \right )= -\sum_{k=1}^{Y}p_{k}\log_{}{p_{k}} E(D)=−k=1∑Ypklogpk
## 信息熵计算定义
from math import log
import pandas as pd
# 信息熵计算函数
def entropy(ele): # ele 包含类别取值的列表
probs = [ele.count(i) / len(ele) for i in set(ele)] # 计算列表中取值的概率分布
return -sum([prob * log(prob, 2) for prob in probs]) # 计算信息熵
# 试运行
df = pd.read_csv('./golf_data.csv')
entropy(df['play'].to_list())
0.9402859586706309
1.2 信息增益
假设离散随机变量(X,Y)的联合概率分布为:
P(X=xi, Y=yi)= pij(i=1,2,…m,j=1,2,…n)
条件熵E(Y|X)表示在已知随机变量X的条件下Y的不确定度量,E(Y|X)可定义为在给定X的条件下Y的条件概率分布的熵对X的数学期望。条件熵可以表示为:
E ( Y ∣ X ) = ∑ i = 1 m p i E ( Y ∣ X = x i ) E\left ( Y \mid X \right )=\sum_{i=1}^{m}p_{i}E\left ( Y\mid X=x_{i} \right ) E(Y∣X)=i=1∑mpiE(Y∣X=xi)
在利用实际数据进行计算时,熵和条件熵中的概率计算都是基于极大似然估计得到,对应的熵和条件熵也叫做经验熵和经验条件熵。
信息增益(information gain) 定义为由于得到特征X的信息而使得类Y的信息不确定性减少的程度,即信息增益是一种描述目标类别确定性增加的量,特征的信息增益越大,目标类别的确定性越大。假设训练集D的经验熵为E(D),给定特征A的条件下D的经验条件熵为E(D|A),那么信息增益可定义为经验熵E(D)与经验条件熵E(D|A)之差:
g ( D , A ) = E ( D ) − E ( D ∣ A ) g\left ( D,A \right ) =E\left ( D \right )-E\left ( D\mid A \right ) g(D,A)=E(D)−E(D∣A)
构建决策树算法时可以使用信息增益进行特征选择。给定训练集D和特征A,经验熵E(D)可以表示为对数据集D进行分类的不确定性,经验条件熵E(D|A)则表示在给定特征A之后对数据集D进行分类的不确定性,二者的差即为两个不确定性之间的差,也就是信息增益。具体到数据集D中,每个特征一般会有不同的信息增益,信息增益越大,代表对应的特征分类能力越强。ID3基于信息增益进行特征选择。
# 划分数据集
def df_split(df, col): # 数据,特征
unique_col_val = df[col].unique() # 获取依据特征的不同取值
res_dict = {
elem: pd.DataFrame for elem in unique_col_val}
for key in res_dict.keys():
res_dict[key] = df[:][df[col] == key]
return res_dict
res_dict = df_split(df, 'outlook')
res_dict

# 信息增益计算
def info_gain(df, col):
res_dict = df_split(df, col)
entropy_D = entropy(df['play'].to_list()) # 计算数据集的经验熵
entropy_DA = 0 # 天气特征的经验条件熵
for key in res_dict.keys():
entropy_DA += len(res_dict[key]) / len(df) * entropy(res_dict[key]['play'].tolist()) # p * 经验条件熵
return entropy_D - entropy_DA # 天气特征的信息增熵
# 增益越大,代表对应的特征分类能力越强
print(f"humility:{
info_gain(df, 'humility')}")
print(f"outlook:{
info_gain(df, 'outlook')}")
print(f"windy:{
info_gain(df, 'windy')}")
print(f"temp:{
info_gain(df, 'temp')}")
humility:0.15183550136234136
outlook:0.2467498197744391
windy:0.04812703040826927
temp:0.029222565658954647
1.3 信息增益比
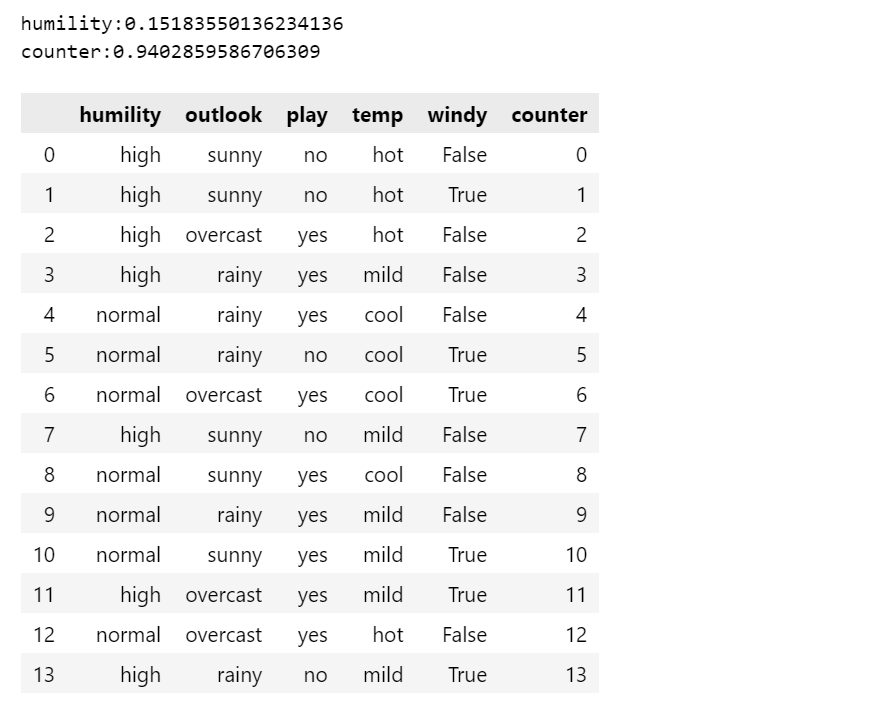
信息增益是一种非常好的特征选择方法,但也存在一些问题:当某个特征分类取值较多时,该特征的信息增益计算结果就会较大,比如为数据集加一个“编号”特征,从第一条记录到最后一条记录,总共14个不同的取值,该特征会产生14个决策树分支,每个分支仅包含一个样本,每个结点的信息纯度都比较高,最后计算得到的信息增益也将远大于其他特征。但是,根据实际情况,我们知道“编号”这样的特征很难起到分类作用,这样构建出来的决策树是无效的,所以,基于信息增益选择特征时,会偏向取值较大的特征。
print(f"humility:{
info_gain(df, 'humility')}")
# 为数据集加一个“编号”特征
df['counter'] = range(len(df))
print(f"counter:{
info_gain(df, 'counter')}")
df
使用信息增益比对上述问题进行校正。特征A对数据集D的信息增益比可以定义为信息增益g(D,A)与数据集D关于特征A取值的熵 EA(D)的比值:n表示A的取值个数
g R ( D , A ) = g ( D , A ) E A ( D ) g_{R}\left ( D, A \right )=\frac{g\left ( D, A \right ) }{E_{A}\left ( D \right )} gR(D,A)=EA(D)g(D,A)
E A ( D ) = − ∑ i = 1 n ∣ D i ∣ D log 2 ∣ D i ∣ D E_{A} \left ( D \right )=-\sum_{i=1}^{n}\frac{\left | D_{i} \right | }{D}\log_{2}\frac{\left | D_{i} \right |}{D} EA(D)=−i=1∑nD∣Di∣log2D∣Di∣
# 信息增益比计算
def information_gain_ratio(df, col):
g = info_gain(df, col)
entropy_EAD = entropy(df[col].to_list())
return g / entropy_EAD
# 试运行
print(f"outlook:{
information_gain_ratio(df, 'outlook')}")
print(f"counter:{
information_gain_ratio(df, 'counter')}")
outlook:0.15642756242117517
counter:0.2469656698468429
除了信息增益和信息增益比外,基尼指数(Gini index)也是一种较好的特征选择方法。基尼指数是针对概率分布而言的。假设样本有K个类,样本属于第k类的概率为pk,则该样本类别概率分布的基尼指数可定义为:
G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini\left ( p \right )=\sum_{k=1}^{K}p_{k}\left ( 1-p_{k} \right )=1-\sum_{k=1}^{K}p_{k}^{2} Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
对于给定训练集D,Ck是属于第k类样本的集合,则该训练集的基尼指数可定义为:
G i n i ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 Gini\left ( D \right )=1-\sum_{k=1}^{K}\left ( \frac{\left | C_{k} \right | }{\left | D \right | } \right ) ^{2} Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
如果训练集D根据特征A某一取值a划分为D1和D2两个部分,那么在特征A这个条件下,训练集D的基尼指数可定义为:
G i n i ( D , A ) = D 1 D G i n i ( D 1 ) + D 2 D G i n i ( D 2 ) Gini\left ( D,A \right )=\frac{D_{1}}{D}Gini\left ( D_{1} \right )+\frac{D_{2}}{D}Gini\left (D_{2} \right) Gini(D,A)=DD1Gini(D1)+DD2Gini(D2)
与信息熵定义类似,训练集D的基尼指数表示该集合的不确定性,Gini(D,A)表示训练集D经过A=a划分后的不确定性。对于分类任务而言,我们希望训练集的不确定性越小越好,对应的特征对训练样本的分类能力越强。CART算法是基于基尼指数进行特征选择的。
# 计算基尼指数
import numpy as np
def calculate_gini(y): # y 包含类别取值的列表
# 将数组转化为列表
y = y.tolist()
probs = [y.count(i)/len(y) for i in np.unique(y)]
gini = sum([p*(1-p) for p in probs])
return gini
# 划分数据集并计算基尼指数
def gini_da(df, col, key): # g根据天气特征取值为晴与非晴划分为两个子集
col_val = [key, 'other']
new_dict = {
elem: pd.DataFrame for elem in col_val} # 创建划分结果的数据框字典
new_dict[key] = df[:][df[col] == key]
new_dict['other'] = df[:][df[col] != key]
gini_DA = 0
for key in new_dict.keys():
gini_DA += len(new_dict[key]) / len(df) * calculate_gini(new_dict[key]['play'])
return gini_DA
# 计算天气特征条件下数据集的基尼指数
print(f"sunny:{
gini_da(df, 'outlook','sunny')}")
print(f"rainy:{
gini_da(df, 'outlook','rainy')}")
print(f"overcast:{
gini_da(df, 'outlook','overcast')}")
sunny:0.3936507936507937
rainy:0.4571428571428572
overcast:0.35714285714285715
2 决策树模型
基于信息增益、信息增益比和基尼系数三种特征选择方法,分别有ID3、C4.5和CART三种经典的决策树算法。这三种算法在构造分类决策树时方法基本一致,都是通过特征选择方法递归地选择最优特征进行构造。其中ID3和C4.5算法只有决策树的生成,不包括决策树剪枝部分,所以这两种算法有时候容易过拟合。CART算法除用于分类外,还可以用于回归,并且该算法是包括决策树剪枝的。
2.1 ID3
ID3算法的全称为Iterative Dichotomiser 3(3代迭代二叉树),其核心是基于信息增益递归地选择最优特征构造决策树。
具体方法如下:首先预设一个决策树根结点,然后对所有特征计算信息增益,选择一个信息增益最大的特征作为最优特征,根据该特征的不同取值建立子结点,接着对每个子结点递归地调用上述方法,直到信息增益很小或没有特征可选时,即可构建最终的ID3决策树。
# ID3算法的核心步骤-选择最优特征
def choose_best_feature(df, label):
'''
思想:根据训练集和标签选择信息增益最大的特征作为最优特征
输入:
df:待划分的训练数据
label:训练标签
输出:
max_value:最大信息增益值
best_feature:最优特征
max_splited:根据最优特征划分后的数据字典
'''
entropy_D = entropy(df[label].tolist()) # 计算训练标签的信息熵
cols = [col for col in df.columns if col not in [label]] # 特征集
max_value, best_feature, max_splited = -999, None, None # 初始化最大信息增益、最优特征和划分后的数据集
for col in cols: # 遍历特征并根据特征取值进行划分
splited_set = df_split(df, col)
entropy_DA = 0 # 初始化经验条件熵
for subset_col, subset in splited_set.items():
entropy_DA += len(subset) / len(df) * entropy(subset[label].tolist()) # 计算当前特征的经验条件熵
info_gain = entropy_D - entropy_DA # 计算当前特征的特征增益
if info_gain > max_value: # 获取最大信息增熵,并保存对应的特征和划分结果
max_value, best_feature = info_gain, col
max_splited = splited_set
return max_value, best_feature, max_splited
# 试运行
df = df.drop(labels='counter', axis=1)
choose_best_feature(df, 'play')

# 封装构建ID3决策树的算法类
class ID3Tree: # ID3算法类
class TreeNode: # 定义树结点
def __init__(self, name): # 定义
self.name = name
self.connections = dict()
def connect(self, label, node):
self.connections[label] = node
def __init__(self, df, label):
self.columns = df.columns
self.df = df
self.label = label
self.root = self.TreeNode('Root')
def construct_tree(self): # 构建树的调用
self.construct(self.root, '', self.df, self.columns)
def construct(self, parent_node, parent_label, sub_df, columns): # 决策树构建方法
max_value, best_feature, max_splited = choose_best_feature(sub_df[columns], self.label) # 选择最优特征
if not best_feature: # 如果选不到最优特征,则构造单结点树
node = self.TreeNode(sub_df[self.label].iloc[0])
parent_node.connect(parent_label, node)
return
# 根据最优特征以及子结点构建树
node = self.TreeNode(best_feature)
parent_node.connect(parent_label, node)
new_columns = [col for col in columns if col != best_feature] # 以A-Ag为新的特征集
# 递归的构造决策树
for splited_value, splited_data in max_splited.items():
self.construct(node, splited_value, splited_data, new_columns)
# 打印树
def print_tree(self, node, tabs):
print(tabs + node.name)
for connection, child_node in node.connections.items():
print(tabs + "\t" + "(" + str(connection) + ")")
self.print_tree(child_node, tabs + "\t\t")
# 构建id3决策树
id3_tree = ID3Tree(df, 'play')
id3_tree.construct_tree()
id3_tree.print_tree(id3_tree.root, '')

…
2.2 CART
CART算法的全称为classification and regression tree(分类与回归树),CART可以理解为在给定随机变量X的条件下输出随机变量Y的条件概率分布的学习算法。CART生成的决策树都是二叉决策树,内部节点取值为“是”和“否”,这种结点划分方法等价于递归地二分每个特征,将特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,即前述预测条件概率分布。
CART算法也可以用来构建回归树。回归树对应特征空间的一个划分以及在该划分单元上的输出值。假设特征空间有M个划分单元R1,R2,…RM,且每个划分单元都有一个输出权重cm,那么回归树模型可以表示为:
f ( x ) = ∑ m = 1 M c m I ( x ∈ R m ) f\left ( x \right )=\sum_{m=1}^{M}c_{m}I\left ( x\in R_{m} \right ) f(x)=m=1∑McmI(x∈Rm)
和线性回归一样,回归树模型训练的目的同样是最小化均方损失,以期望求得最优输出权重cm_hat。具体而言,我们用平方误差最小方法求解每个单元上的最优权重,最优输出权重可以通过每个单元上所有输入实例对应的输出值的均值来确定:
c m ^ = a v e r a g e ( y i ∣ x i ∈ R m ) \hat{c_{m}}=average\left ( y_{i} \mid x_{i}\in R_{m}\right ) cm^=average(yi∣xi∈Rm)
假设回归树选取第j个特征x(j)及其对应的某个取值s,将其作为划分特征和划分点,同时定义两个区域:
R 1 ( j , s ) = { x ∣ x ( j ) ≤ s } ; R 2 ( j , s ) = { x ∣ x ( j ) > s } R_{1}\left ( j,s \right )=\left \{ x\mid x^{(j)}\le s \right \}; R_{2}\left ( j,s \right )=\left \{ x\mid x^{(j)}> s \right \} R1(j,s)={
x∣x(j)≤s};R2(j,s)={
x∣x(j)>s}
然后求解,可得到输入特征j和最优划分点s。
m i n j s [ m i n c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + m i n c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 ] min_{js}\left [ min_{c_{1}\sum_{x_{i}\in R_{1}(j,s)}^{}}(y_{i}-c_{1})^{2}+min_{c_{2}\sum_{x_{i}\in R_{2}(j,s)}^{}}(y_{i}-c_{2})^{2}\right ] minjs[minc1∑xi∈R1(j,s)(yi−c1)2+minc2∑xi∈R2(j,s)(yi−c2)2]
# 定义树结点
class TreeNode:
def __init__(self, feature_i=None, threshold=None, leaf_value=None, left_branch=None, right_branch=None):
self.feature_i = feature_i # 特征索引
self.threshold = threshold # 特征划分阈值
self.leaf_value = leaf_value # 叶子节点取值
self.left_branch = left_branch # 左子树
self.right_branch = right_branch # 右子树
# 定义二叉特征分裂函数
def feature_split(X, feature_i, threshold):
split_func = None
if isinstance(threshold, int) or isinstance(threshold, float):
split_func = lambda sample: sample[feature_i] >= threshold
else:
split_func = lambda sample: sample[feature_i] == threshold
X_left = np.array([sample for sample in X if split_func(sample)])
X_right = np.array([sample for sample in X if not split_func(sample)])
return np.array([X_left, X_right])
# 定义二叉决策树
class BinaryDecisionTree:
def __init__(self, min_samples_split=3, min_gini_impurity=999, max_depth=float('inf'), loss=None): # 决策树初始参数
self.root = None # 根结点
self.min_samples_split = min_samples_split # 节点最小分裂样本数
self.mini_gini_impurity = min_gini_impurity # 节点初始化基尼不纯度
self.max_depth = max_depth # 树最大深度
self.impurity_calculation = None # 基尼不纯度计算函数
self._leaf_value_calculation = None # 叶子节点值预测函数
self.loss = loss # 损失函数
def fit(self, X, y, loss=None): # 决策树拟合函数
self.root = self._build_tree(X, y) # 递归构建决策树
self.loss=None
def _build_tree(self, X, y, current_depth=0): # 决策树构建函数
init_gini_impurity = 999 # 初始化最小基尼不纯度
best_criteria = None # 初始化最佳特征索引和阈值
best_sets = None # 初始化数据子集
Xy = np.concatenate((X, y), axis=1) # 合并输入和标签
n_samples, n_features = X.shape # 获取样本数和特征数
# 设定决策树构建条件
if n_samples >= self.min_samples_split and current_depth <= self.max_depth: # 训练样本数量大于节点最小分裂样本数且当前树深度小于最大深度
for feature_i in range(n_features):
unique_values = np.unique(X[:, feature_i]) # 获取第i个特征的唯一取值
for threshold in unique_values: # 遍历取值并寻找最佳特征分裂阈值
Xy1, Xy2 = feature_split(Xy, feature_i, threshold) # 特征节点二叉分裂
if len(Xy1) > 0 and len(Xy2) > 0: # 如果分裂后的子集大小都不为0
y1, y2 = Xy1[:, n_features:], Xy2[:, n_features:] # 获取两个子集的标签值
impurity = self.impurity_calculation(y, y1, y2) # 计算基尼不纯度
if impurity < init_gini_impurity:
init_gini_impurity = impurity # 获取最小基尼不纯度
best_criteria = {
"feature_i": feature_i, "threshold": threshold} # 最佳特征索引和分裂阈值
best_sets = {
"leftX": Xy1[:, :n_features],
"lefty": Xy1[:, n_features:],
"rightX": Xy2[:, :n_features],
"righty": Xy2[:, n_features:]
}
if init_gini_impurity < self.mini_gini_impurity: # 如果计算的最小不纯度小于设定的最小不纯度
# 分别构建左右子树
left_branch = self._build_tree(best_sets["leftX"], best_sets["lefty"], current_depth + 1)
right_branch = self._build_tree(best_sets["rightX"], best_sets["righty"], current_depth + 1)
return TreeNode(feature_i=best_criteria["feature_i"], threshold=best_criteria["threshold"], left_branch=left_branch, right_branch=right_branch)
# 计算叶子计算取值
leaf_value = self._leaf_value_calculation(y)
return TreeNode(leaf_value=leaf_value)
def predict_value(self, x, tree=None): # 定义二叉树值预测函数
if tree is None:
tree = self.root
if tree.leaf_value is not None: # 如果叶子节点已有值,则直接返回已有值
return tree.leaf_value
feature_value = x[tree.feature_i] # 选择特征并获取特征值
# 判断落入左子树还是右子树
branch = tree.right_branch
if isinstance(feature_value, int) or isinstance(feature_value, float):
if feature_value >= tree.threshold:
branch = tree.left_branch
elif feature_value == tree.threshold:
branch = tree.left_branch
return self.predict_value(x, branch) # 测试子集
def predict(self, X): # 数据集预测函数
y_pred = [self.predict_value(sample) for sample in X]
return y_pred
# CART分类树
class ClassificationTree(BinaryDecisionTree): # 分类树
def _calculate_gini_impurity(self, y, y1, y2): # 定义基尼不纯度计算过程
p = len(y1) / len(y)
gini_impurity = p * calculate_gini(y1) + (1-p) * calculate_gini(y2)
return gini_impurity
def _majority_vote(self, y): # 多数投票
most_common = None
max_count = 0
for label in np.unique(y):
# 统计多数
count = len(y[y == label])
if count > max_count:
most_common = label
max_count = count
return most_common
def fit(self, X, y): # 分类树拟合
self.impurity_calculation = self._calculate_gini_impurity
self._leaf_value_calculation = self._majority_vote
super(ClassificationTree, self).fit(X, y)
# 测试CART分类树
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = datasets.load_iris() # 鸢尾花数据集
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y.reshape(-1,1), test_size=0.3)
clf = ClassificationTree()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
0.9777777777777777
# CART回归树
class RegressionTree(BinaryDecisionTree): # 回归树
def _calculate_variance_reduction(self, y, y1, y2):
var_tot = np.var(y, axis=0)
var_y1 = np.var(y1, axis=0)
var_y2 = np.var(y2, axis=0)
frac_1 = len(y1) / len(y)
frac_2 = len(y2) / len(y)
variance_reduction = var_tot - (frac_1 * var_y1 + frac_2 * var_y2) # 计算方差减少量
return 1/sum(variance_reduction) # 方差减少量越大越好,所以取倒数
def _mean_of_y(self, y): # 节点值取平均
value = np.mean(y, axis=0)
return value if len(value) > 1 else value[0]
def fit(self, X, y):
self.impurity_calculation = self._calculate_variance_reduction
self._leaf_value_calculation = self._mean_of_y
super(RegressionTree, self).fit(X, y)
# 测试CART回归树
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_boston
X, y = load_boston(return_X_y=True)
y = y.reshape(-1, 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = RegressionTree()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
Mean Squared Error: 18.304654605263156
一个完整的决策树算法,除决策树生成算法外,还包括决策树剪枝算法。决策树生成算法递归地产生决策树,生成的决策树大而全,但很容易过拟合。决策树剪枝(pruning)则是对已生成的决策树进行简化的过程,通过对已生成的决策树剪掉一些子树或者叶子结点,并将其根节点或父节点作为新的叶子结点,从而达到简化决策树的目的。
决策树剪枝一般包括两种方法:预剪枝(pre-pruning),后剪枝(psot-pruning)。所谓预剪枝就是在决策树生成过程中提前停止树的增长的一种剪枝算法。其主要思想是在决策树结点分裂之前,计算当前结点划分能否提升模型泛化能力,如果不能,则决策树在该结点停止生长。预剪枝提前停止树生长,一定程度上存在欠拟合的风险。
在实际应用中,我们还是以后剪枝方法为主。后剪枝主要是通过极小化决策树整体损失函数来实现。前面提到决策树最小化如下函数:
L a ( T ) = ∑ t = 1 ∣ T ∣ N t H t ( T ) + α ∣ T ∣ L_{a}\left ( T \right ) = \sum_{t=1}^{\left | T \right | } N_{t}H_{t}\left ( T \right ) +\alpha\left | T \right | La(T)=t=1∑∣T∣NtHt(T)+α∣T∣
其中第一项的经验熵可以表示为:
H t ( T ) = − ∑ k N t k N t l o g N t k N t H_{t}(T)=-\sum_{k}^{}\frac{N_{tk}}{N_{t}}log\frac{N_{tk}}{N_{t}} Ht(T)=−k∑NtNtklogNtNtk
L(T)的第一项可以表示为:
L a ( T ) = ∑ t = 1 ∣ T ∣ N t H t ( T ) = − ∑ t = 1 ∣ T ∣ ∑ k = 1 K N t k l o g N t k N t L_{a}\left ( T \right ) = \sum_{t=1}^{\left | T \right | } N_{t}H_{t}\left ( T \right )=-\sum_{t=1}^{\left | T \right |}\sum_{k=1}^{K} N_{tk}log\frac{N_{tk}}{N_{t}} La(T)=t=1∑∣T∣NtHt(T)=−t=1∑∣T∣k=1∑KNtklogNtNtk
改写决策树优化函数为
L a ( T ) = L ( T ) + α ∣ T ∣ L_{a} (T)=L(T)+\alpha\left | T \right | La(T)=L(T)+α∣T∣
L(T)是模型的经验误差项,|T|是决策树复杂度,α是正则化参数。
决策树后剪枝就是在复杂度α确定的情况下,选择损失函数Lα(T)最小的决策树模型。给定生成算法得到的决策树T和正则化参数α,决策树后剪枝算法描述如下:
(1).计算每个树结点的经验熵Ht(T)。
(2).递归地自底向上回缩,假设一组叶子结点回缩到父结点前后的树分别为Tbefore和Tafter,其对应的损失函数分别为Lα(Tbefore)和Lα(Tafter),如果Lα(Tafter)≤Lα(Tbefore),则进行剪枝,将父结点变为新的叶子结点。
(3).重复(2),直到得到损失函数最小的子树Tα。
CART后剪枝通过计算子树的损失函数来实现剪枝并得到一个子树序列,然后通过交叉验证的方法从子树序列中选取最优子树。
2.3 基于sklearn实现分类树和回归树
# 基于sklearn实现分类树
from sklearn.tree import DecisionTreeClassifier
data = datasets.load_iris() # 鸢尾花数据集
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y.reshape(-1,1), test_size=0.3)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
0.9333333333333333
# 基于sklearn实现回归树
from sklearn.tree import DecisionTreeRegressor
X, y = load_boston(return_X_y=True)
y = y.reshape(-1, 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
reg = DecisionTreeRegressor()
reg.fit(X_train, y_train)
y_pred = reg.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
Mean Squared Error: 14.449605263157896