刚刚做完线性分类器的作业,趁热打铁做下总结。
-
摘要
模式识别的目的是要在特征空间中设法找到两类(或多类)之间的分界面。基于样本直接设计分类器需要确定三个基本要素:一是分类器即判别函数的类型,也就是从什么样的判别函数(函数集)中去求解;二是分类器设计的目标或准则,在确定了设计准则后,分类器设计就是根据样本从事先决定的函数集中选择在该准则下最优的函数,通常就是确定函数类中的某些待定参数;三是在前两个要素明确后,如何设计算法利用样本数据搜索到最优的函数参数(即选择函数集中的函数)。
这次作业主要是做了四个线性分类器的算法,分别是Fisher判别、感知器算法、MSE算法以及SVM算法。我用的是octave软件,语法上和matlab基本是差不多的,但是它是开源的,占用内存也小,使用起来比matlab方便。
-
算法的原理
关于这部分,书上都有详细的介绍,不再叙述。我上课的书本是张学工编著的模式识别第三版 。个人感觉这几个算法的原理还是不太好理解的,很多公式和推导,我也是花费了很长时间才理解的,推荐几个中国慕课网上的公开课,没搞懂算法原理的可以参考看下。算法原理还是要搞懂的,不然后面设计算法写代码会有困难。下面是公开课的链接:
https://www.icourse163.org/course/QDU-1206493804?outvandor=zw_mooc_pclszykctj_
https://www.icourse163.org/course/WHUT-1205885803?outvandor=zw_mooc_pclszykctj_
https://www.icourse163.org/course/FZU-1206674825?outvandor=zw_mooc_pclszykctj_
-
数据集
应老师的要求,所以我的数据集来自UCI:https://archive.ics.uci.edu/ml/index.php,这个网站上的数据集分类很清楚,找数据集的时候就很方便,每个数据集也都有详细的说明。找数据集的时候要自己分辨是两类的还是多类的数据集,由于我老师要求两个多类的数据集,两个两类的数据集,所以我在找数据集上花费了一定的时间,因为找到适合做实验的数据集不是很容易,因为大部分的数据集都是线性不可分的,这样有的分类器算法就不是能很好的处理。
最经典的一个数据集是鸢尾花,我也采用了这个数据集,他是三类的数据集,其中两类是可以线性可分的,但是第三类和其他类不能线性可分,我只采用了其中的线性可分的两类作为我算法的测试,整体做下来还是这个数据集在算法上实验上的结果最完美。另外一个较好的数据集就是"banknote authentication Date Set",这是一个两类的数据集,有五个属性,这个数据集主要是判别钞票的真假的。


-
实验结果






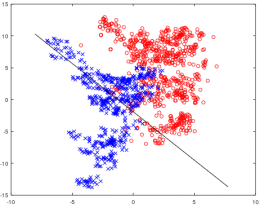

上面的图片只是在部分数据集上跑出来的结果,有的数据集由于是线性不可分的,所以跑出来的结果不太理想,甚至感知器算法直接卡在中途,不出结果,当然这也和我写的算法有关,由于本人能力有限,只能暂时写出来处理线性可分的算法。
Fisher代码
clc
clear
[x1,y1,x2,x3,class] = textread('C:\Users\jxn\Desktop\banknote.txt', '%f%f%f%f%f', 'delimiter', ',');%读取数据集
a=zeros(size(class,1),1);
%a(strcmp(class, 'n')) = 1;
%a(strcmp(class, 'w')) = -1;
k=0;
m=0;
for i=1:size(class,1)
if class(i)==0
k=k+1;
w1(:,k)=[x1(i),y1(i)];
elseif class(i)==1
m=m+1;
w2(:,m)=[x1(i),y1(i)];
end
end
m1=mean(w1,2);%求w1每行的平均值
m2=mean(w2,2);%求w2每行的平均值
s1=zeros(2,2);%生成一个2行2列的零矩阵
s2=zeros(2,2);
for i=1:size(w1,2)
s10=(w1(:,i)-m1)*(w1(:,i)-m1)';
s1=s1+s10;
end
for i=1:size(w2,2)
s20=(w2(:,i)-m2)*(w2(:,i)-m2)';
s2=s2+s20;
end
sw=s1+s2;
w_new=transpose(inv(sw)*(m1-m2));%最佳投影方向的转置
m1_new=w_new*m1;
m2_new=w_new*m2;
pw1=0.6;%已知先验概率的情况下
pw2=0.4;
w0=(m1_new+m2_new)/2-log(pw1/pw2)/(50+50-2);%求分类阈值
h1=plot(w1(1,:),w1(2,:),'ro'),hold on%画出w1类的所有点
h2=plot(w2(1,:),w2(2,:),'bx'),hold on%画出w2类的所有点
h3=plot([0,10000*w_new(1)],[0,10000*w_new(2)]),hold on%画出最佳投影方向
title('Fisher')MSE代码
clc
clear
[x1,y1,x2,x3,class] = textread('C:\Users\jxn\Desktop\banknote.txt', '%f%f%f%f%f', 'delimiter', ',');
a=zeros(size(class,1),1);
k=0;
m=0;
for i=1:size(class,1)
if class(i)==0
k=k+1;
w1(:,k)=[x1(i),y1(i)];
elseif class(i)==1
m=m+1;
w2(:,m)=[x1(i),y1(i)];
end
end
ww1=[ones(1,size(w1,2));w1];
ww2=[ones(1,size(w2,2));w2];
w12=[ww1 ww2];
y1=-ones(1,size(w1,2));
y2=ones(1,size(w2,2));
y12=[y1 y2];
R=w12*w12';%求出自相关矩阵
E=y12*w12';%求出期望输出和输入特征向量的互相关
w=E*inv(R);%求权向量估计值
xmin=min(min(w1(1,:)),min(w2(1,:)));
xmax=max(max(w1(1,:)),max(w2(1,:)));
xindex=xmin-1:(xmax-xmin)/100:xmax+1;
yindex=-w(2)*xindex/w(3)-w(1)/w(3);
plot(xindex,yindex,'-k'),hold on
plot(w1(1,:),w1(2,:),'ro'),hold on%画出w1类的所有点
plot(w2(1,:),w2(2,:),'bx'),hold on%画出w2类的所有点
title('MSE');感知器代码
clc
clear
[x1,y1,x2,x3,class] = textread('C:\Users\jxn\Desktop\banknote.txt', '%f%f%f%f%f', 'delimiter', ',');
a=zeros(size(class,1),1);
k=0;
m=0;
for i=1:size(class,1)
if class(i)==0
k=k+1;
w1(:,k)=[x1(i),y1(i)];
elseif class(i)==1
m=m+1;
w2(:,m)=[x1(i),y1(i)];
end
end
ww1=[ones(1,size(w1,2));w1];
ww2=[ones(1,size(w2,2));w2];
w12=[ww1 -ww2];
k=0
a=[1;1;1]
y=zeros(1,size(w12,2))
while any(y<=0)
sum=zeros(3,1);
for i=1:size(y,2)
y(i)=a'*w12(:,i);
if y(i)<=0
sum=sum+w12(:,i);
end
end
if any(sum)~=0
a=a+sum;
k=k+1;
end
end
plot(w1(1,:),w1(2,:),'+r')
hold on
plot(w2(1,:),w2(2,:),'bs')
hold on
xmin=min(min(w1(1,:)),min(w2(1,:)))
xmax=max(max(w1(1,:)),max(w2(1,:)))
xindex=xmin-1:(xmax-xmin)/100:xmax+1;
yindex=-a(2)*xindex/a(3)-a(1)/a(3);
plot(xindex,yindex,'-k')
hold on
title('Perceptron')SVM代码
function test_svm()
clc
clear
[x1,y1,x2,x3,class] = textread('C:\Users\jxn\Desktop\banknote.txt', '%f%f%f%f%f', 'delimiter', ',');
a=zeros(size(class,1),1);
k=0;
m=0;
for i=1:size(class,1)
if class(i)==0
k=k+1;
w1(:,k)=[x1(i),y1(i)];
elseif class(i)==1
m=m+1;
w2(:,m)=[x1(i),y1(i)];
end
end
X = [w1 w2];
Y = [ones(size(w1,2),1) ; -ones(size(w2,2),1)];
plot(w1(1,:),w1(2,:),'ro');
hold on;
plot(w2(1,:),w2(2,:),'bx');
u = svm(X,Y)
xmin=min(min(w1(1,:)),min(w2(1,:)))
xmax=max(max(w1(1,:)),max(w2(1,:)))
xindex=xmin-1:(xmax-xmin)/100:xmax+1;
yindex=-u(2)*xindex/u(3)-u(1)/u(3);
plot(xindex,yindex,'-k')
%title(SVM);
%x = [-u(1)/u(2) , 0];
%y = [0, -u(1)/u(3)];
%plot(x,y);
end
function u = svm( X,Y )
[K,N] = size(X);
%display(K);
%display(N);
u0= rand(K+1,1); % u= [b ; w];
A = - repmat(Y,1,K+1).*[ones(N,1) X'];
b = -ones(N,1);
H = eye(K);
H = [zeros(1,K);H];
H = [zeros(K+1,1) H];
p = zeros(K+1,1);
lb = -100*ones(K+1,1);
rb = 100*ones(K+1,1);
options = optimset; % Options是用来控制算法的选项参数的向量
options.LargeScale = 'off';
options.Display = 'off';
options.Algorithm = 'active-set';
[u,val] = quadprog(H,p,A,b,[],[],lb,rb,u0,options)
end-
体会
本次实验在octave上执行算法,其基本语法和matllab相似,由于对matlab语言并不熟悉,所以在编写代码的过程中遇到了很多的困难。不像之前写代码那样,因为是熟悉的语言,出现语法错误的时候就能很轻松的解决,由于对matlab语法不熟悉,所以在碰到语法错误的时候,往往需要花费很长的时间才能解决,这也是我此次实验的一大困难点。
虽热对各个分类器算法理解了,但是在编写代码时还是会碰到问题,有很多点无法将算法中的思路转化为代码中的思路。但是就是在这个过程中,让我更加深入的理解了各个分类器的算法,对他们有了更加深入的认识。
处理两类样本和处理多类样本,虽然大体思路是一样的,但是在修改代码的时候,也是碰到了困难,不过最终还是解决了。
通过此次实验,加深了对模式识别这门课的理解,加深了对线性分类器的理解以及前面所学知识的理解,这也将对后面课程的学习有所帮助。所以虽然实验的过程中碰到很多困难,但是现在看来一切都是值得的。