目的
用势函数的概念来确定判别函数和划分类别界面。
基本思想
假设要划分属于两种类别ω1和ω2的模式样本,这些样本可看成是分布在n维模式空间中的点xk。 把属于ω1的点比拟为某种能源点,在点上,电位达到峰值。 随着与该点距离的增大,电位分布迅速减小,即把样本xk附近空间x点上的电位分布,看成是一个势函数K(x, xk)。 对于属于ω1的样本集群,其附近空间会形成一个“高地”,这些样本点所处的位置就是“山头”。 同理,用电位的几何分布来看待属于ω2的模式样本,在其附近空间就形成“凹地”。 只要在两类电位分布之间选择合适的等高线,就可以认为是模式分类的判别函数。
3.9.1 判别函数的产生
模式分类的判别函数可由分布在模式空间中的许多样本向量{xk, k=1,2,…且  }的势函数产生。 任意一个样本所产生的势函数以K(x, xk)表征,则判别函数d(x)可由势函数序列K(x, x1), K(x, x2),…来构成,序列中的这些势函数相应于在训练过程中输入机器的训练模式样本x1,x2,…。 在训练状态,模式样本逐个输入分类器,分类器就连续计算相应的势函数,在第k步迭代时的积累位势决定于在该步前所有的单独势函数的累加。 以K(x)表示积累位势函数,若加入的训练样本xk+1是错误分类,则积累函数需要修改,若是正确分类,则不变。
}的势函数产生。 任意一个样本所产生的势函数以K(x, xk)表征,则判别函数d(x)可由势函数序列K(x, x1), K(x, x2),…来构成,序列中的这些势函数相应于在训练过程中输入机器的训练模式样本x1,x2,…。 在训练状态,模式样本逐个输入分类器,分类器就连续计算相应的势函数,在第k步迭代时的积累位势决定于在该步前所有的单独势函数的累加。 以K(x)表示积累位势函数,若加入的训练样本xk+1是错误分类,则积累函数需要修改,若是正确分类,则不变。
从势函数可以看出,积累位势起着判别函数的作用 当xk+1属于ω1时,Kk(xk+1)>0;当xk+1属于ω2时,Kk(xk+1)<0,则积累位势不做任何修改就可用作判别函数。 由于一个模式样本的错误分类可造成积累位势在训练时的变化,因此势函数算法提供了确定ω1和ω2两类判别函数的迭代过程。 判别函数表达式 取d(x)=K(x),则有:dk+1(x)= dk(x)+rk+1K(x, xk+1 )
3.9.2 势函数的选择
选择势函数的条件:一般来说,若两个n维向量x和xk的函数K(x, xk)同时满足下列三个条件,则可作为势函数。 K(x, xk)= K(xk, x),并且当且仅当x=xk时达到最大值; 当向量x与xk的距离趋于无穷时,K(x, xk)趋于零; K(x, xk)是光滑函数,且是x与xk之间距离的单调下降函数。

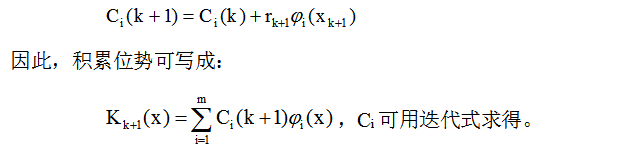


势函数法
实例1:用第一类势函数的算法进行分类


(1) 选择合适的正交函数集{}
选择Hermite多项式,其正交域为(-∞, +∞),其一维形式是
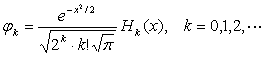

其正交性:

其中,Hk(x)前面的乘式为正交归一化因子,为计算简便可省略。因此,Hermite多项式前面几项的表达式为
H0(x)=1, H1(x)=2x, H2(x)=4x2-2,
H3(x)=8x3-12x, H4(x)=16x4-48x2+12
(2) 建立二维的正交函数集
二维的正交函数集可由任意一对一维的正交函数组成,这里取四项最低阶的二维的正交函数
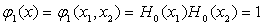
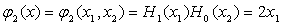
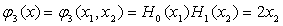

(3) 生成势函数
按第一类势函数定义,得到势函数
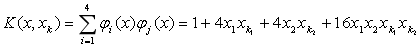
其中,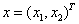
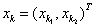
(4) 通过训练样本逐步计算累积位势K(x)
给定训练样本:ω1类为x①=(1 0)T, x②=(0 -1)T
ω2类为x③=(-1 0)T, x④=(0 1)T
累积位势K(x)的迭代算法如下
第一步:取x①=(1 0)T∈ω1,故
K1(x)=K(x, x①)=1+4x1·1+4x2·0+16x1x2·1·0=1+4x1
第二步:取x②=(0 -1)T∈ω1,故K1(x②)=1+4·0=1
因K1(x②)>0且x②∈ω1,故K2(x)=K1(x)=1+4x1
第三步:取x③=(-1 0)T∈ω2,故K2(x③)=1+4·(-1)=-3
因K2(x③)<0且x③∈ω2,故K3(x)=K2(x)=1+4x1
第四步:取x④=(0 1)T∈ω2,故K3(x④)=1+4·0=1
因K3(x④)>0且x④∈ω2,
故K4(x)=K3(x)-K(x,x④)=1+4x1-(1+4x2)=4x1-4x2
将全部训练样本重复迭代一次,得
第五步:取x⑤=x①=(1 0)T∈ω1,K4(x⑤)=4
故K5(x)=K4(x)=4x1-4x2
第六步:取x⑥=x②=(0 -1)T∈ω1,K5(x⑥)=4
故K6(x)=K5(x)=4x1-4x2
第七步:取x⑦=x③=(-1 0)T∈ω2,K6(x⑦)=-4
故K7(x)=K6(x)=4x1-4x2
第八步:取x⑧=x④=(0 1)T∈ω2,K7(x⑧)=-4
故K8(x)=K7(x)=4x1-4x2
以上对全部训练样本都能正确分类,因此算法收敛于判别函数
d(x)=4x1-4x2
实例2:用第二类势函数的算法进行分类
选择指数型势函数,取α=1,在二维情况下势函数为
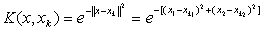
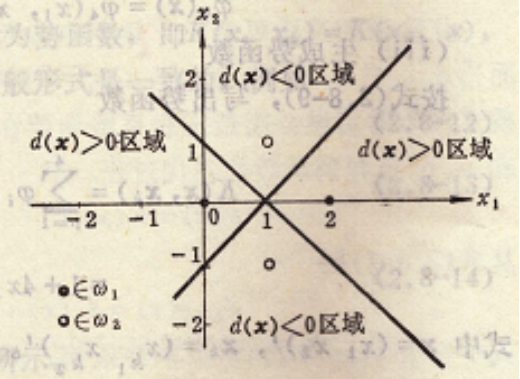
这里:ω1类为x①=(0 0)T, x②=(2 0)T
ω2类为x③=(1 1)T, x④=(1 -1)T
可以看出,这两类模式是线性不可分的。算法步骤如下:
第一步:取x①=(0 0)T∈ω1,则
K1(x)=K(x,x①)=
第二步:取x②=(2 0)T∈ω1
因K1(x②)=e-(4+0)=e-4>0,
故K2(x)=K1(x)=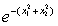
第三步:取x③=(1 1)T∈ω2
因K2(x③)=e-(1+1)=e-2>0,
故K3(x)=K2(x)-K(x,x③)=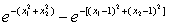
第四步:取x④=(1 -1)T∈ω2
因K3(x④) =e-(1+1)-e-(0+4)=e-2-e-4>0,
故K4(x)=K3(x)-K(x,x④)
=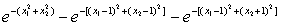
需对全部训练样本重复迭代一次
第五步:取x⑤=x①=(0 0)T∈ω1,K4(x⑤)=e0-e-2-e-2=1-2e-2>0
故K5(x)=K4(x)
第六步:取x⑥=x②=(2 0)T∈ω1,K5(x⑥)=e-4-e-2-e-2=e-4-2e-2<0
故K6(x)=K5(x)+K(x,x⑥)
=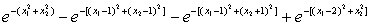
第七步:取x⑦=x③=(1 1)T∈ω2,K6(x⑦)=e-2-e0-e-4+e-2=2e-2-e-4-1<0
故K7(x)=K6(x)
第八步:取x⑧=x④=(1 -1)T∈ω2,K7(x⑧)=e-2-e-4-e0+e-2=2e-2-e-4-1<0
故K8(x)=K7(x)
第九步:取x⑨=x①=(0 0)T∈ω1,K8(x⑨)=e0-e-2-e-2+e-4=1+e-4-2e-2>0
故K9(x)=K8(x)
第十步:取x⑩=x②=(2 0)T∈ω1,K9(x⑩)=e-4-e-2-e-2+e0=1+e-4-2e-2>0
故K10(x)=K9(x)
经过上述迭代,全部模式都已正确分类,因此算法收敛于判别函数
讨论
用第二类势函数,当训练样本维数和数目都较高时,需要计算和存储的指数项较多。 正因为势函数由许多新项组成,因此有很强的分类能力。

