1 简介
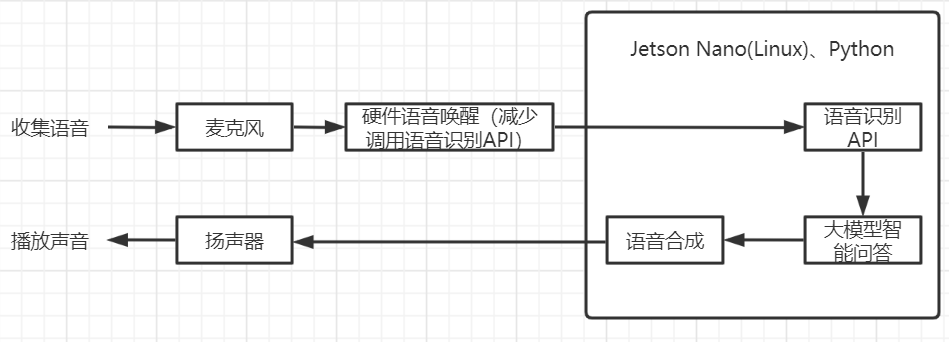
如上图,主要采用jetson上编写python代码实现,支持离线语音唤醒、在线语音识别、大模型智能文档、在线语音合成。
所需硬件如下:
- jetson nano:linux
- 科大讯飞麦克风硬件:AIUI R818麦克阵列开发套件+6麦阵列,支持离线语音唤醒
- USB免驱声卡+喇叭
所需软件如下:
- 科大讯飞在线语音识别API
- 科大讯飞在线语音合成API
- 语言大模型API
视频示例:
自己制作智能语音机器人,识别鸭脖和老鼠头_哔哩哔哩_bilibili
2 jetson 安装pycharm
安装pycharm主要是为了方便直接在jetson上进行python开发。
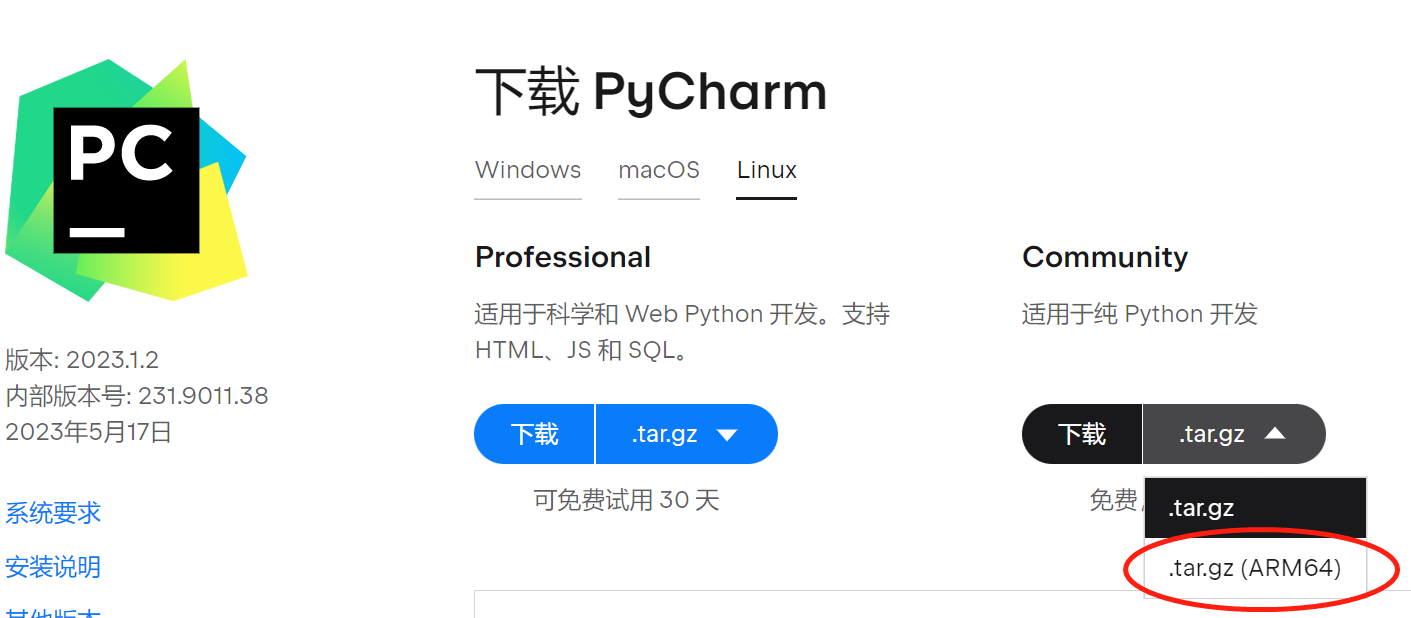
1.下载地址下载PyCharm:JetBrains为专业开发者提供的Python IDE
选择arm64版本。
2. 解压进入bin目录。在终端输入sh pycharm.sh进行安装。

3.创建桌面图标
在主桌面打开终端,输入编辑命令
sudo gedit /usr/share/applications/Pycharm.desktop
这里使用了管理员权限,要输入管理员密码
随后会弹出一个文本框,输入以下命令
[Desktop Entry]
Type=Application
Name=Pycharm
GenericName=Pycharm3
Comment=Pycharm3:The Python IDE
Exec=sh /home/xxx/pycharm.sh
Icon=home/xxx/pycharm.png
Terminal=pycharm
Categories=Pycharm;上面给出的代码里的xxx为pycharm.sh和pycharm.png的位置。就是第2部解压后的路径。
文本编辑好后点击保存,之后就可以在应用管理里找到pycharm的应用图标,并可以运行了。
4. 新建工程,可以选择jetson自带的python。
参考:jetson安装pycharm和visual studio code_龙先生__的博客-CSDN博客
3 离线语音唤醒
采用科大讯飞AIUI R818麦克阵列和6麦组合,支持离线语音识别。
科大讯飞AIUI R818麦克阵列开发套件
AIUI R818麦克阵列开发套件是一款基于多麦克风阵列的完整前端声学软硬件一体化解决方案。采用4核
高性能边缘计算处理器,内部集成科大讯飞语音算法,利用麦克风阵列的空域滤波特性,通过唤醒人的
角度定位,形成定向拾音波束,并对波束以外的噪声进行抑制,提升远场拾音质量。同时针对人机交互
一体终端,集成高性能回声消除算法,降低语音、语义识别难度,开发者可快速集成使产品具备多麦音
频采集、唤醒、降噪和回声消除等功能。

6麦阵列

硬件连线
如下图,主要连接UAC接口、串口、40排线这3个就行。

配置自己的唤醒词
需要登录科大讯飞控制台定制自己的唤醒词,文档参见R818 AIUI降噪板开发套件 - AIUI文档中心 - 站点标题。
- 在网站AIUI开放平台,设置唤醒词
- 取下载资源中的 res.bin
- 通过adb 命令adb push res.bin /oem/build/vtn/res.bin
- adb shell 进入adb 控制台
- 输入sync 同步
- 输入 reboot 重启
代码
将上面硬件连接到jetson后,需要在jetson实现如下代码,实现python代码里接收到麦克风语音唤醒信号。
1.安装串口函数库,终端执行下面的命令(如果使用的是官方镜像,应该是已经安装好了):
sudo pip3 install pyserial2. 麦克风唤醒代码
import serial
import json
import time
import os
from std_msgs.msg import String, Float32, Int32, Bool
woshuo = b'\xa5\x01\x01\x04\x00\x00\x00\xa5\x00\x00\x00\xb0'
queren = b'\xA5\x01\xff\x04\x00\x00\x00\xA5\x00\x00\x00\xB2'
len_r = 0
data_list = []
buf = []
buf_flag = 0
first=0
def deal(data_list):
global first
str1 = str(data_list)
f_data = str1.find('{')
l_data = str1.rfind('}')
str1 = str1[f_data:l_data+1]
str1 = str1.replace("\\","")
str1 = str1.replace("', b'","")
str1 = str1.replace('"{',"{")
str1 = str1.replace('}"',"}")
json_str = json.loads(str1)
print("json_str: ", json_str)
if 'code' in json_str and first == 0:
sss = json_str['content']
print(json_str['content'])
first = 1
else:
angle = json_str['content']['info']['ivw']['angle']
print("angle: ", angle)
return angle
#麦克风连接的usb端口
#timeout这是终止时间,用以终止串口操作。程序就会持续读取timeout秒的时长来读取数据
ser=serial.Serial("/dev/ttyUSB0", 115200, 8,'N',1,timeout = 5)
print("Open the serial")
try:
while True:
#serial.read_all()读取一个timeout周期内的全部数据(常用方法)
#平时串口通信中,最好使用read_all()方法,并选定合适的timeout
rcv = ser.read_all()
len_r = len(rcv)
if rcv == woshuo:
ser.write(queren)
elif(len_r > 1) :
buf.append(rcv)
buf_flag = 1
elif len_r < 1 and buf_flag==1:
buf_flag = 0
data_list = buf
buf = []
angle_msg = deal(data_list)
time.sleep(0.5)
ser.close()
except Exception as e:
print("---Error---:",e)4 在线语音识别ASR
在上面语音唤醒基础上,增加调用科大讯飞在线API接口实现语音识别。主要采用语音听写流式API demo python3语言。websocket接口。
详见:语音听写(流式版)WebAPI 文档 | 讯飞开放平台文档中心
# -*- coding:utf-8 -*-
#
# author: iflytek
#
# 本demo测试时运行的环境为:Windows + Python3.7
# 本demo测试成功运行时所安装的第三方库及其版本如下,您可自行逐一或者复制到一个新的txt文件利用pip一次性安装:
# cffi==1.12.3
# gevent==1.4.0
# greenlet==0.4.15
# pycparser==2.19
# six==1.12.0
# websocket==0.2.1
# websocket-client==0.56.0
#
# 语音听写流式 WebAPI 接口调用示例 接口文档(必看):https://doc.xfyun.cn/rest_api/语音听写(流式版).html
# webapi 听写服务参考帖子(必看):http://bbs.xfyun.cn/forum.php?mod=viewthread&tid=38947&extra=
# 语音听写流式WebAPI 服务,热词使用方式:登陆开放平台https://www.xfyun.cn/后,找到控制台--我的应用---语音听写(流式)---服务管理--个性化热词,
# 设置热词
# 注意:热词只能在识别的时候会增加热词的识别权重,需要注意的是增加相应词条的识别率,但并不是绝对的,具体效果以您测试为准。
# 语音听写流式WebAPI 服务,方言试用方法:登陆开放平台https://www.xfyun.cn/后,找到控制台--我的应用---语音听写(流式)---服务管理--识别语种列表
# 可添加语种或方言,添加后会显示该方言的参数值
# 错误码链接:https://www.xfyun.cn/document/error-code (code返回错误码时必看)
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
import websocket
import datetime
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, AudioFile):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.AudioFile = AudioFile
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
# 业务参数(business),更多个性化参数可在官网查看
self.BusinessArgs = {"domain": "iat", "language": "zh_cn", "accent": "mandarin", "vinfo":1,"vad_eos":10000}
# 生成url
def create_url(self):
url = 'wss://ws-api.xfyun.cn/v2/iat'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/iat " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
# print("date: ",date)
# print("v: ",v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
# print('websocket url :', url)
return url
# 收到websocket消息的处理
def on_message(ws, message):
try:
code = json.loads(message)["code"]
sid = json.loads(message)["sid"]
if code != 0:
errMsg = json.loads(message)["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
data = json.loads(message)["data"]["result"]["ws"]
# print(json.loads(message))
result = ""
for i in data:
for w in i["cw"]:
result += w["w"]
print("sid:%s call success!,data is:%s" % (sid, json.dumps(data, ensure_ascii=False)))
except Exception as e:
print("receive msg,but parse exception:", e)
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws,a,b):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws):
def run(*args):
frameSize = 8000 # 每一帧的音频大小
intervel = 0.04 # 发送音频间隔(单位:s)
status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧
with open(wsParam.AudioFile, "rb") as fp:
while True:
buf = fp.read(frameSize)
# 文件结束
if not buf:
status = STATUS_LAST_FRAME
# 第一帧处理
# 发送第一帧音频,带business 参数
# appid 必须带上,只需第一帧发送
if status == STATUS_FIRST_FRAME:
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": {"status": 0, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
d = json.dumps(d)
ws.send(d)
status = STATUS_CONTINUE_FRAME
# 中间帧处理
elif status == STATUS_CONTINUE_FRAME:
d = {"data": {"status": 1, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
# 最后一帧处理
elif status == STATUS_LAST_FRAME:
d = {"data": {"status": 2, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
time.sleep(1)
break
# 模拟音频采样间隔
time.sleep(intervel)
ws.close()
thread.start_new_thread(run, ())
if __name__ == "__main__":
# 测试时候在此处正确填写相关信息即可运行
time1 = datetime.now()
wsParam = Ws_Param(APPID='xxxxx', APISecret='xxxxx',
APIKey='xxxxx',
AudioFile=r'xxxxx')
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
time2 = datetime.now()
print(time2-time1)
5 对接大模型进行智能对话
百度大模型调用链如下:

代码
import numpy as np
import requests
import json
#获取授权token
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=xxx&client_secret=xxx"
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
d = response.json()
#调用模型
url = 'https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions?access_token={'+d['access_token']+'}'
payload = "{\"messages\":[{\"role\":\"user\",\"content\":\"什么是大模型\"}]}"
payload=payload.encode('utf-8')
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
d = response.json() #以字典格式获取json数据
print(d['result'])6 在线语音合成
采用科大讯飞接口,流水语音合成,websocket接口。
参见:语音合成(流式版)WebAPI 文档 | 讯飞开放平台文档中心
# -*- coding:utf-8 -*-
#
# author: iflytek
#
# 本demo测试时运行的环境为:Windows + Python3.7
# 本demo测试成功运行时所安装的第三方库及其版本如下:
# cffi==1.12.3
# gevent==1.4.0
# greenlet==0.4.15
# pycparser==2.19
# six==1.12.0
# websocket==0.2.1
# websocket-client==0.56.0
# 合成小语种需要传输小语种文本、使用小语种发音人vcn、tte=unicode以及修改文本编码方式
# 错误码链接:https://www.xfyun.cn/document/error-code (code返回错误码时必看)
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
import websocket
import datetime
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
import os
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, Text):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.Text = Text
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
# 业务参数(business),更多个性化参数可在官网查看
self.BusinessArgs = {"aue": "raw", "auf": "audio/L16;rate=16000", "vcn": "xiaoyan", "tte": "utf8"}
self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-8')), "UTF8")}
#使用小语种须使用以下方式,此处的unicode指的是 utf16小端的编码方式,即"UTF-16LE"”
#self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-16')), "UTF8")}
# 生成url
def create_url(self):
url = 'wss://tts-api.xfyun.cn/v2/tts'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/tts " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
# print("date: ",date)
# print("v: ",v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
# print('websocket url :', url)
return url
def on_message(ws, message):
try:
message =json.loads(message)
code = message["code"]
sid = message["sid"]
audio = message["data"]["audio"]
audio = base64.b64decode(audio)
status = message["data"]["status"]
print(message)
if status == 2:
print("ws is closed")
ws.close()
if code != 0:
errMsg = message["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
with open('./demo.pcm', 'ab') as f:
f.write(audio)
except Exception as e:
print("receive msg,but parse exception:", e)
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws):
def run(*args):
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": wsParam.Data,
}
d = json.dumps(d)
print("------>开始发送文本数据")
ws.send(d)
if os.path.exists('./demo.pcm'):
os.remove('./demo.pcm')
thread.start_new_thread(run, ())
if __name__ == "__main__":
# 测试时候在此处正确填写相关信息即可运行
wsParam = Ws_Param(APPID=' ', APISecret=' ',
APIKey=' ',
Text="这是一个语音合成示例")
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
7 播放声音
7.1 播放wav
linux命令:aplay -D plughw:0,0 xxx.wav
plughw后面的0,0指的是声卡id和设备id(card0,device0),这个根据自己的设备决定
7.2 播放pcm
aplay -t raw -c 1 -f S16_LE -r 16000 test2.pcm
-t: type raw表示是PCM
-c: channel 1
-f S16_LE: Signed 16bit-width Little-Endian
-r: sample rate 16000
PCM是最raw的音频数据,没有任何头信息。WAV文件就是PCM+头信息,头信息就是上述的声道数,sample rate这些。所以WAV文件可以直接播放,而PCM需要手动指定这些信息之后才能播放。
参考:https://www.cnblogs.com/super119/archive/2011/01/03/1924431.html