高斯过程(Gaussian Process)
在机器学习领域里,高斯过程是一种假设训练数据来自无限空间、并且各特征都符合高斯分布的有监督建模方式。高斯过程是一种概率模型,无论是回归或者分类预测都以高斯分布标准差的方式给出预测置信区间估计。
在了解高斯过程前,我们先来简单回顾下高斯分布和置信区间
高斯分布
高斯分布(Gaussian distribution又名正态分布(这个我们应该更熟悉)、正规分布,是一个非常常见的连续概率分布。正态分布在统计学上十分重要,经常用在自然和社会科学来代表一个不明的随机变量。
若随机变量 X X X服从一个位置参数为 μ \mu μ 、尺度参数为 σ \sigma σ的正态分布,记为:
X ∼ N ( μ , σ 2 ) {\displaystyle X\sim N(\mu ,\sigma ^{2})} X∼N(μ,σ2)
则其概率密度函数为
f ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 {\displaystyle f(x)={\frac {1}{\sigma {\sqrt {2\pi }}}}\;e^{-{\frac {\left(x-\mu \right)^{2}}{2\sigma ^{2}}}}\!} f(x)=σ2π1e−2σ2(x−μ)2
正态分布的数学期望值或期望值 μ \mu μ等于位置参数,决定了分布的位置;其方差 σ 2 \sigma^2 σ2的开平方或标准差 σ \sigma σ 等于尺度参数,决定了分布的幅度。
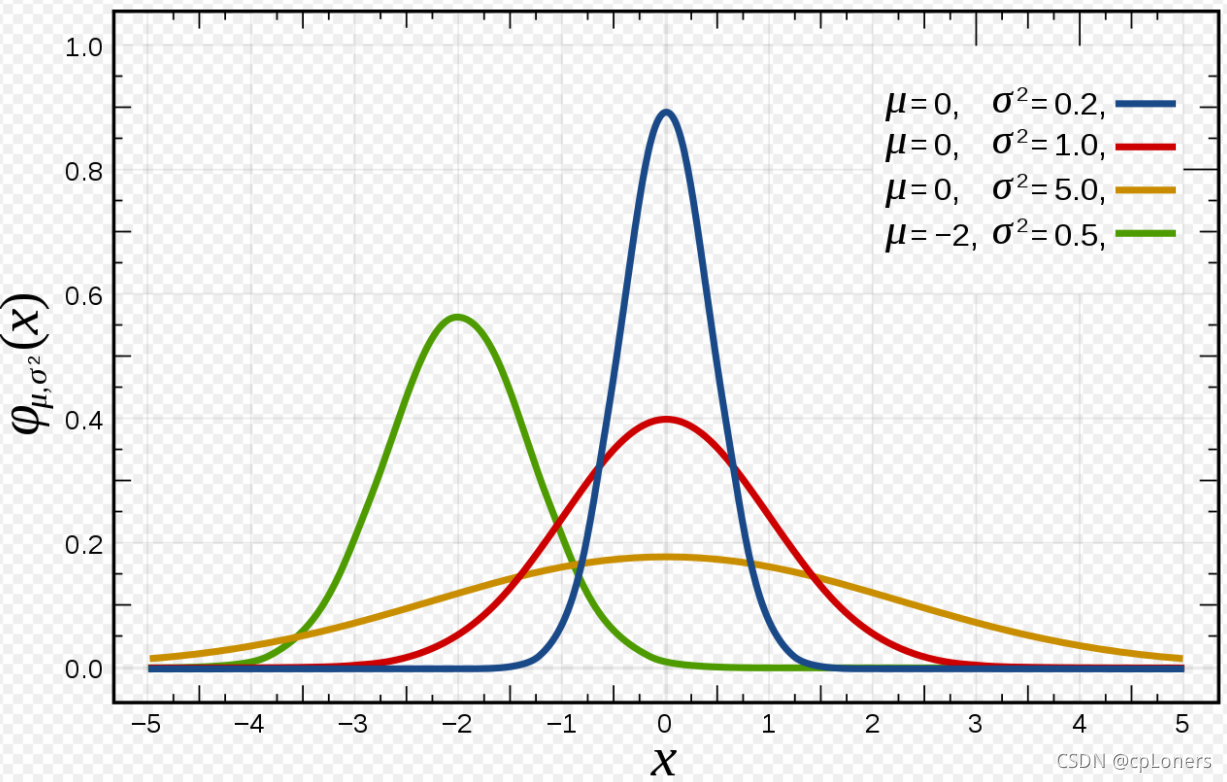
正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线(类似于寺庙里的大钟,因此得名)。我们通常所说的标准正态分布是位置参数 μ = 0 \mu =0 μ=0,尺度参数 σ 2 = 1 \sigma^2 = 1 σ2=1的正态分布(下图中红色曲线就是标准正态分布)。
置信区间
置信区间是指由样本统计量所构造的总体参数的估计区间。在统计学中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。置信区间给出的是被测量参数测量值的可信程度范围,即前面所要求的“一定概率”。置信区间的计算公式:置信区间的计算公式取决于所用到的统计量。置信区间是在预先确定好的显著性水平下计算出来的,显著性水平通常称为α(希腊字母alpha),如前所述,绝大多数情况会将α设为0.05。置信度为(1-α),或者100×(1-α)%。于是,如果α=0.05,那么置信度则是0.95或95%,后一种表示方式更为常用。置信水平表示区间估计的把握程度,置信区间的跨度是置信水平的正函数,即要求的把握程度越大,势必得到一个较宽的置信区间,这就相应降低了估计的准确程度。
随机过程
了解完置信区间和高斯分布后,下面我们来了解下高斯过程,高斯过程它来源于数学中的随机过程(Stochastic Process)理论。随机过程是研究一组无限个随机变量内在规律的学科,下面我们举个例子来说明“无限个随机变量”与机器学习建模的关系。
假设需要训练一个预测某城市在任意时间居民用电量的模型。简化期间,在该模型中可以用当前温度、年内天数(即一年中的第几天)、当天时间作为数据特征,将居民总用电量作为目标标签数值。用有监督学习的思维,首先需要收集历史用电数据,比如在 2018年的每天中午 12:00 收集并记录数据,这样得到了一组包含 N=365 条数据的训练数据。但显然居民用电在一天内的不同时间段是有变化的,如果仅仅中午的采样数据不能精确建模,那么可以改为每天采样两次。如果仍不能满足需求,可以增加到每小时采样、每分钟采样……可以发现,随着精度要求的增加采样的训练数据是可以无限增加的。图如果把每次采样的目标值用电量y都看成一个随机变量,那么单条采样就是一个随机分布事件的结果,N条数据就是多个随机分布采样的结果,而整个被学习空间就是由无数个随机变量构成的随机过程了。
那为什么我们要把实实在在采样得到的 Y 值看成随机变量呢?这涉及两个方面:一是所有数据的产生本身就是随机的,试想自己每天开空调或灯光是否都有随性成分?另一方面,数据的采集是有噪声存在的,这部分在通信领域也叫白噪声,在统计学中叫系统误差。对于这样的场景,无论如何不可能给出一个精确值的预测,即使给出后碰巧符合也只能说明运气不错。更合理的预测方式应该是一个置信区间预测,比如 705±30 的概率达到 95%。
高斯分布的特点
如果把每个随机变量都用高斯分布进行建模,那么整个随机过程就是一个高斯过程。高斯过程能成为随机过程最广泛的应用之一就是因为高斯分布本身的诸多优良特性。下面我们总结下高斯分布的特点。
| 特点 | 原因 |
|---|---|
| 可标准化 | 一个高斯分布可由均值μ和标准差σ唯一确定,用符号~N(μ,o)表示。并且任意高斯分布可以转化为用μ=0和σ=1的标准正态分布表达 |
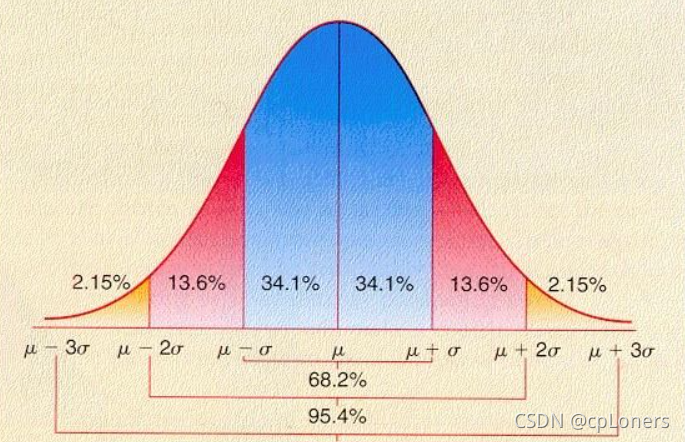
| 方便统计 | 高斯分布中约 69.27%的样本落在(μ-σ,μ+σ)之间,约 95%的样本落在(μ-2σ,μ+2σ)之间,约 99%的样本落在(μ-3σ,μ+3o)之间 |
| 多元高斯分布(Multivariate Gaussian) | n 元高斯分布描述 n 个随机变量的联合概率分布,由均值向量(μ, μ 2 \mu_2 μ2… μ n \mu_n μn)和协方差短阵工唯一确定。其中上是一个 nXn 的矩阵,每个矩阵元素描述 n 个随机变量两两之间的协方差。 |
| 和与差 | 设有任意两个独立的高斯分布 U 和 V,那么它们的和 U+V 一定是高斯分布,它们的差 U-V 也一定是高斯分布 |
| 部分与整体 | 多元高斯分布的条件分布仍然是多元高斯分布,也可理解为多元高斯分布的子集也是多元高斯分布 |
核函数
根据上面的知识已经知道可以将高斯过程看成无限维的多元高斯分布,那么机器学习的训练过程目标就是学习该无限维高斯分布的子集——也是一个多元高斯分布的参数:均值向量<μ, μ 2 \mu_2 μ2… μ n \mu_n μn>和协方差矩阵上。协方差矩阵工中的元素用于表征两两样本之间的协方差,这个“描述两两样本之间关系”的概念似曾相识。对,就是 SVM 中用于计算高维空间两两样本向量内积的核函数。此处核方法也应用在了协方差矩阵上,使得多元高斯分布也具有了表征高维空间样本之间关系的能力,也就是具备了表征非线性数据的能力。此时的协方差矩阵可以表示为:
Σ = K x x = [ k ( x 1 , x 2 ) . . . k ( x 1 , x n ) : . . . : k ( x n , x 1 ) . . . k ( x n , x n ) ] \Sigma = Kxx = \begin{bmatrix}k(x_1, x_2) & ...&k(x_1, x_n) \\ : & ...&:\\k(x_n,x_1)&...&k(x_n,x_n)\\ \end{bmatrix} Σ=Kxx=⎣⎡k(x1,x2):k(xn,x1).........k(x1,xn):k(xn,xn)⎦⎤
其中符号Kxx表示样本数据特征集 X 的核函数矩阵,用 k()表示所选取的核函数, x 1 , x 2 . . . x n x_1,x_2...x_n x1,x2...xn等是单个样本特征向量。和 SVM 一样,此处的核函数也需要开发者指定其形式。常用的仍然有径向基核、多项式核、线性核等。在训练过程中可以定义算法自动寻找核的最佳超参数。
白噪声处理
在建模中已经知道随机过程需要考虑采样数据存在噪声的情况。用高斯分布的观点来看,就是在计算训练数据协方差矩阵 Kxx 的对角元素上增加噪声分量。因此协方差矩阵变为如下形式:
Σ = K x x = [ k ( x 1 , x 2 ) … k ( x 1 , x n ) ⋮ ⋱ ⋮ k ( x n , x 1 ) … k ( x n , x n ) ] + α ( 1 … 0 ⋮ ⋮ 0 … 1 ) \Sigma = Kxx = \begin{bmatrix}k(x_1, x_2) & \dots&k(x_1, x_n) \\ \vdots& \ddots&\vdots\\k(x_n,x_1)&\dots&k(x_n,x_n)\\ \end{bmatrix}+\alpha\begin{pmatrix} 1&\dots&0\\ \vdots&&\vdots\\ 0&\dots&1\\ \end{pmatrix} Σ=Kxx=⎣⎢⎡k(x1,x2)⋮k(xn,x1)…⋱…k(x1,xn)⋮k(xn,xn)⎦⎥⎤+α⎝⎜⎛1⋮0……0⋮1⎠⎟⎞
其中α 是模型训练者需要定义的噪声估计参数,该值越大模型抗噪声能力越强,但容易产生拟合不足。
实战
下面实战用的是一个非线性函数y = x*sin(x)-x生成带噪声的训练样本,然后用高斯过程模型来模拟这个函数,并比较模型预测结果和真实目标值。
import numpy as np
from matplotlib import pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF
from sklearn.gaussian_process.kernels import ConstantKernel as C, Product
# 原函数
def f(X):
return X * np.sin(X) - X
X = np.linspace(0, 10, 20) # 20个训练样本数据特征值
y = f(X) + np.random.normal(0, 0.5, X.shape[0]) # 样本目标值,并带有噪声
x = np.linspace(0, 10, 200) # 测试样本特征值
# 定义两个核函数,并取它们的积
kernel = Product(C(0.1), RBF(10, (1e-2, 1e2))) # RBF:径向基核,把特征向量提升到无限维以解决非线性问题
# 初始化模型:传入核函数对象,优化次数,噪声超参数
gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=3, alpha=0.3)
gp.fit(X.reshape(-1, 1), y)
y_pred, sigma = gp.predict(x.reshape(-1, 1), return_std=True)
fig = plt.figure()
plt.plot(x, f(x), 'r:', label=u'$f(x) = x\,\sin(x)-x$')
plt.plot(X, y, 'r.', markersize=10, label=u'Observations')
plt.plot(x, y_pred, 'b-', label=u'Prediction')
plt.fill(np.concatenate([x, x[::-1]]), np.concatenate([y_pred - 2*sigma, (y_pred + 2*sigma)[::-1]]),
alpha=.3, fc='b', label='95%confidece') # 填充置信区间
plt.legend(loc='lower left')
plt.show()

上图中的实心原点是训练数据,并且在整个区间均匀分布了 200 个测试样本:虚线是函数的真实值,实线是测试样本预测值,带条是预测值的±2o范围。可以发现整体上测试样本的真实值虚线与预测值实线基本重合,只在左上角区域有较大偏差,但都在 95%的置信区间内。
高斯过程与大多数机器学习模型不同的是,由于高斯过程在预测过程中仍然需要用到原始训练数据,因此导致该方法通常在高维特征和超多训练样本的场景下显得运算效率低。但也正是因此,它才能提供它们所不具备的基于概率分布的预测。
高斯过程特有初始化参数总结:
| 参数 | 解释 |
|---|---|
| kernel | 核函数对象,即sklearn.gaussian_process.kernels中类的实例 |
| alpha | 为了考虑样本噪声在协方差矩阵对角量的增加,可以是一个数值(应用在所以对角元素上),也可以是一个向量(分别应用在每个对角元素上) |
| optimizer | 可以是一个函数,用于在训练过程中优化核函数的超参数 |
| n_restarts_optimizer | optimizer被调用的次数,默认为1 |