点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式

论文地址:YOLOCS: Object Detection based on Dense Channel Compression for Feature Spatial Solidification (arxiv.org)
计算机视觉研究院专栏
Column of Computer Vision Institute
通过压缩特征图的空间分辨率,提高了对象检测的准确性和速度。本文的主要贡献在于引入了一种新的特征空间固化方法,能够有效地降低特征图的时空复杂度,提高对象检测的效率和准确性。

01
总 述
在今天分享中,研究者检查了在特征纯化和梯度反向传播过程中信道特征和卷积核之间的关联,重点是网络内的前向和反向传播。因此,研究者提出了一种称为密集通道压缩的特征空间固化方法。根据该方法的核心概念,引入了两个用于骨干网络和头部网络的创新模块:用于特征空间固化结构的密集通道压缩(DCFS)和非对称多级压缩解耦头部(ADH)。当集成到YOLOv5模型中时,这两个模块表现出非凡的性能,从而产生了一个被称为YOLOCS的改进模型。
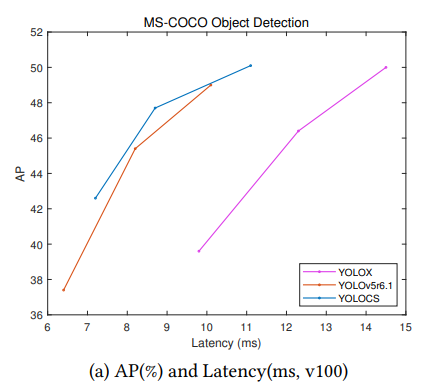
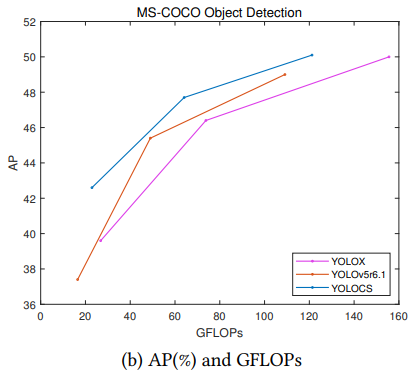
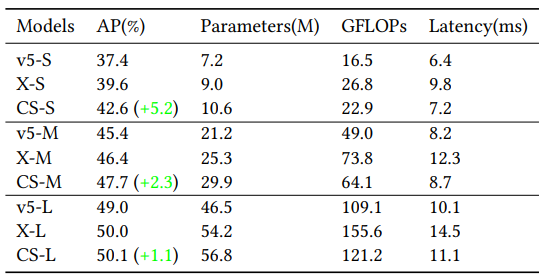
在MSCOCO数据集上评估,大、中、小YOLOCS模型的AP分别为50.1%、47.6%和42.5%。在保持与YOLOv5模型的推理速度显著相似的情况下,大、中、小YOLOCS模型分别以1.1%、2.3%和5.2%的优势超过YOLOv5的AP。
02
背 景
近年来,目标检测技术在计算机视觉领域受到了广泛关注。其中,基于单发多框算法的目标检测技术(Single Shot Multi Box Detector,SSD)和基于卷积神经网络的目标检测技术(Convolutional Neural Networks,CNN)是两种最常用的目标检测技术。然而,由于单发多框算法的精度较低,而基于卷积神经网络的目标检测技术的计算复杂度较高,因此,寻找一种高效且精度较高的目标检测技术成为了当前研究的热点之一。
Dense Channel Compression(DCC)是一种新型的卷积神经网络压缩技术,它通过对卷积神经网络中的特征图进行空间固化,从而实现对网络参数的压缩和加速。然而,DCC技术在目标检测领域的应用尚未得到充分的研究。
因此,提出了一种基于Dense Channel Compression的目标检测技术,命名为YOLOCS(YOLO with Dense Channel Compression)。YOLOCS技术将DCC技术与YOLO(You Only Look Once)算法相结合,实现了对目标检测的高效且精度较高的处理。具体来说,YOLOCS技术通过DCC技术对特征图进行空间固化,从而实现对目标位置的精确定位;同时,YOLOCS技术利用YOLO算法的单发多框算法特点,实现对目标类别分类的快速计算。
03
新框架
Dense Channel Compression for Feature Spatial Solidification Structure (DCFS)
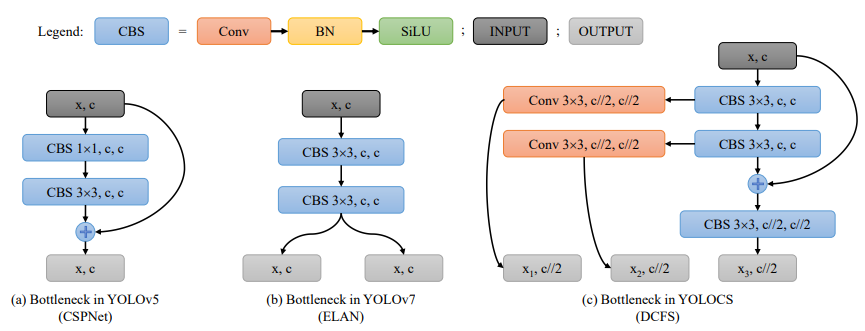
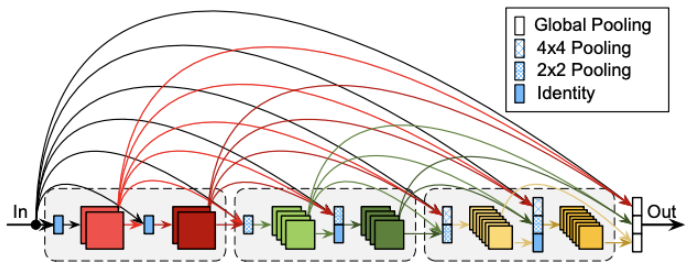
在提出的方法中(上图(c))中,研究者不仅解决了网络宽度和深度之间的平衡问题,还通过3×3卷积压缩了来自不同深度层的特征,在输出和融合特征之前将通道数量减少了一半。这种方法使研究者能够在更大程度上细化来自不同层的特征输出,从而在融合阶段增强特征的多样性和有效性。
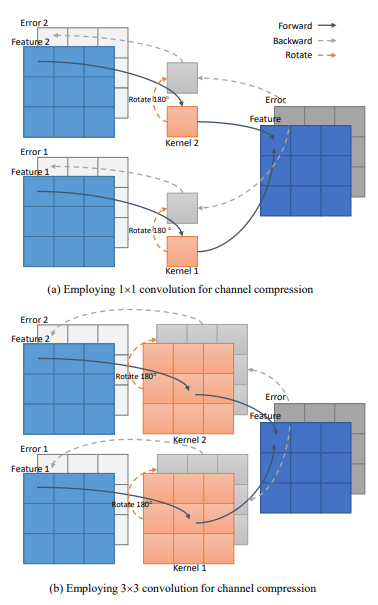
此外,来自每一层的压缩特征都带有更大的卷积核权重(3×3),从而有效地扩展了输出特征的感受野。将这种方法称为特征空间固化的密集通道压缩。用于特征空间固化的密集通道压缩背后的基本原理依赖于利用较大的卷积核来促进通道压缩。该技术具有两个关键优点:首先,它扩展了前向传播过程中特征感知的感受域,从而确保了区域相关的特征细节被纳入,以最大限度地减少整个压缩阶段的特征损失。其次,误差反向传播过程中误差细节的增强允许更准确的权重调整。
为了进一步阐明这两个优点,使用具有两种不同核类型(1×1和3×3)的卷积来压缩两个通道,如下图:
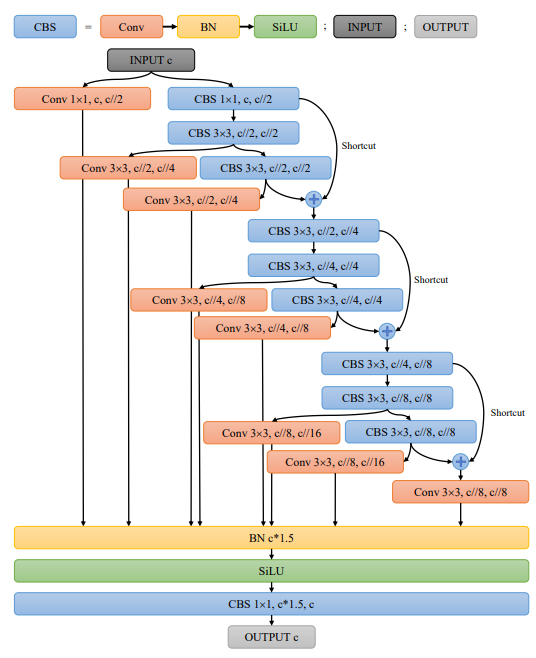
DCFS的网络结构如下图所示。采用三层瓶颈结构,在网络前向传播的过程中逐渐压缩信道。半通道3×3卷积应用于所有分支,然后是批处理归一化(BN)和激活函数层。随后,使用1×1卷积层来压缩输出特征通道,以匹配输入特征通道。
Asymmetric Multi-level Channel Compression Decoupled Head (ADH)
为了解决YOLOX模型中的解耦头问题,研究者进行了一系列的研究和实验。研究结果揭示了解耦头部结构的利用与相关损失函数之间的逻辑相关性。具体而言,对于不同的任务,应根据损失计算的复杂性调整解耦头的结构。此外,当将解耦的头部结构应用于各种任务时,由于最终输出维度的差异,将前一层的特征通道(如下图)直接压缩为任务通道可能会导致显著的特征损失。这反过来又会对模型的整体性能产生不利影响。
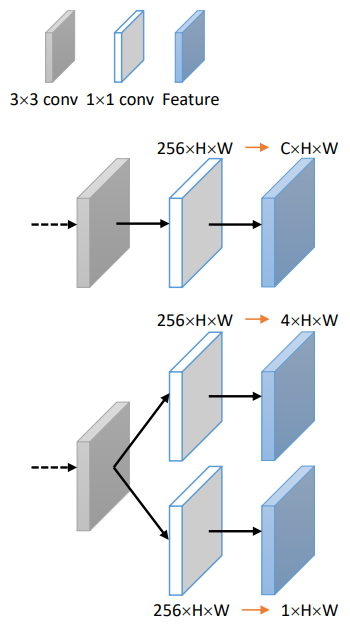
此外,当考虑提出的用于特征空间固化的密集通道压缩方法时,直接减少最终层中的通道数量以匹配输出通道可能会导致前向传播过程中的特征丢失,从而降低网络性能。同时,在反向传播的背景下,这种结构可能会导致次优误差反向传播,阻碍梯度稳定性的实现。为了应对这些挑战,引入了一种新的解耦头,称为非对称多级通道压缩解耦头(如下图(b))。
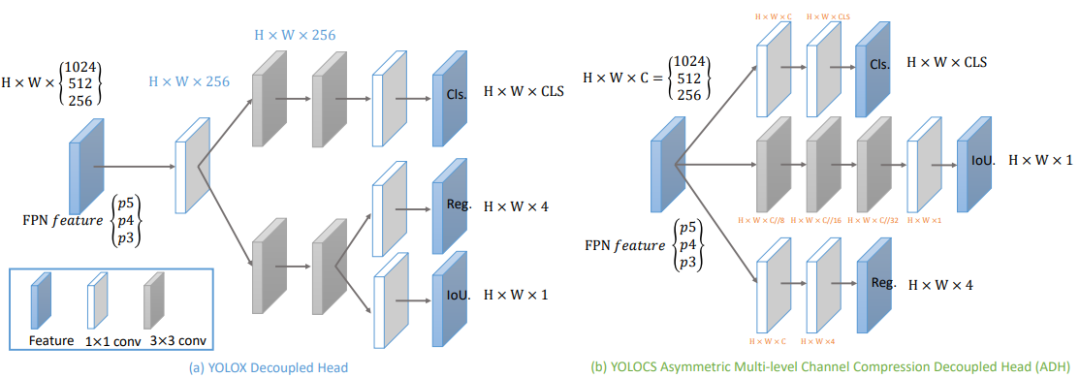
具体而言,研究者深化了专用于目标评分任务的网络路径,并使用3个卷积来扩展该任务的感受野和参数数量。同时,沿着通道维度压缩每个卷积层的特征。该方法不仅有效地减轻了与目标评分任务相关的训练难度,提高了模型性能,而且大大减少了解耦头部模块的参数和GFLOP,从而显著提高了推理速度。此外,使用1卷积层来分离分类和边界框任务。这是因为对于匹配的正样本,与两个任务相关联的损失相对较小,因此避免了过度扩展。这种方法大大降低了解耦头中的参数和GFLOP,最终提高了推理速度。
04
实验可视化
Ablation Experiment on MS-COCO val2017

Comparison of YOLOCS, YOLOX and YOLOv5- r6.1[7] in terms of AP on MS-COCO 2017 test-dev
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割等研究方向。研究院始终分享最新论文算法框架,平台着重”研究“和“实践”。后期会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!




点击“阅读原文”,立即合作咨询