目录
本项目由以下四部分组成,本节是第3节:
3、MPI优化
4、OpenMP优化
MPI并行设计
在读取数据时使用串行,其余for循环都采用MPI并行。具体步骤如下:
1、 0进程读取数据文件,生成dataSet数组。
2、通过MPI_Scatterv()函数将dataSet数组分为多个长度不等的数据块,向各进程散射数据块。
3、各进程进行求和,通过MPI_Gather()函数将结果返回0进程累加,从而得出平均值。
4、0进程通过MPI_Bcast()函数将平均值(r)广播到所有进程。
5、各进程计算标准差的部分内容: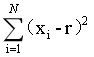 。
。
6、0进程完成剩余的标准差计算得出标准差SD。
7、得到高斯分布的概率密度函数f(x)=[1/ sqrt(2*π*δ²)]*exp(-(x-μ)²/2δ²)
8、获得P(身高=170|女性)、P(身高=170|男性)、P(体重=60|女性)、P(体重=60|男性)等概率。
9、将相应的所有概率相乘,取最大值对应的特征为预测结果。
使用MPI_Scatterv散射大小不同的数据块
介绍MPI_Scatterv函数
本次实验使用MPI_Scatterv散射收发数据块,此方法不仅能解决广播占用内存开销大的问题,还能收发不同大小的数据块。在mpich_MPI_Scatterv可以查到MPI_Scatterv函数如下: int MPI_Scatterv(const void *sendbuf, const int *sendcounts, const int *displs,
MPI_Datatype sendtype, void *recvbuf, int recvcount,
MPI_Datatype recvtype, int root, MPI_Comm comm)
函数内的输入参数:
Sendbuf:数组指针,被散射发送的数组地址。
Sendcounts:整数数组,数组内每一个元素对应每个进程所发送的数据长度。
Displs:整数数组,数组内每一个元素对应每个进程从sendbuf收发数据的起始位置。
Sendtype:MPI数据类型,发送数据的数据类型。
Recvbuf:整数数组,接收分块数据到的数组。
Recvcount:整数,与Sendcounts对应,表示该进程所接受的数据长度。
Recvtype:MPI数据类型,接收数据的数据类型。
Root:整数,发送数据的进程,填散射数据的进程,一般填0。
Comm:通信子,通常填MPI_COMM_WORLD。
MPI_Scatterv参数选择
生成Sendcounts数组
Sendcounts数组是用来保存每个进程所接收的数据长度,数组的长度等于进程数,由于在MPI_Scatterv()传递的是数组指针,数组内每个数的内存地址要连续,可以用直接声明,也可以用malloc()函数来声明数组。
每个进程所分到的数据长度可以是不同的,本项目为了方便后面创建Displs数组,本次做法是让所有进程都接收(dataLen/comm_sz)个数据,最后一个进程再多接收(dataLen%comm_sz)个数据。
代码如下:
int *Sendcounts; //对每个进程分发的数据长度
Sendcounts = (int *) malloc(comm_sz * sizeof(int));//分配内存
for(i=0;i<comm_sz;i++){
if(i==comm_sz-1){
Sendcounts[i]=(int) (dataLen/comm_sz+(dataLen%comm_sz))*EIGEN_NUM;}
else{Sendcounts[i]=(int) (dataLen/comm_sz)*EIGEN_NUM;}
}生成Displs数组
Displs数组是用来保存每个进程所接收数据的内存偏移量,数组的长度等于进程数,由于在MPI_Scatterv()传递的是数组指针,数组内每个数的内存地址要连续,可以用直接声明,也可以用malloc()函数来声明数组。
每个进程所分到的数据是同一个数组的不同不分,第一个进程接收的是dataSet[0] - dataSet[Sendcounts[0]-1]位置的数据,第二个进程接收的是dataSet[Sendcounts[0]] - dataSet[Sendcounts[1]-1]位置的数据。第一个进程接收的初始位置是0,第二个接收的初始位置是Sendcounts[0],第n个数组接收初始的位置是displs[n-1]+Sendcounts[n-1],根据这个规律,我们便可以通过以下代码,来生成内存偏移量数组:
int *displs; //相对于dataSet的内存偏移量
displs = (int *) malloc(comm_sz * sizeof(int)); //分配内存
displs[0]=0;
for(i=1;i<comm_sz;i++)
{
displs[i]=displs[i-1]+Sendcounts[i-1];
//printf("displs[i]=%d",displs[i]);
//printf("分发给进程%d的内存偏移量:%d\n",i,displs[i]);
}MPI函数合作完成并行计算
用MPI_Scatterv()函数将数组分成多个名为receiveBuf的子数组后,各进程for循环计算receiveBuf数组的和,sendSum数组接收进程的计算结果,通过MPI_Gather()函数将所有进程sendSum[特征数]数组返回0进程成为reciveSum[comm_sz*特征数],数组累加除以对应的总数,从而得出平均值(r)。
0进程通过MPI_Bcast()函数将平均值(r)广播到所有进程,各进程计算,通过MPI_Gather()函数将结果返回到0进程,将返回的数据累加后相当于完成串行的
Sigma=,standardDeviation=sqrt(Sigma/sexNum)。
其余步骤与2.2.1类似,不在阐述。至此,完成了所有MPI计算过程。
为了尽可能用到MPI,在后续的数据模型评估也可以用到MPI,也是利用MPI_Scatterv()函数将验证数据集分发给所有进程,各进程求出正确和错误个数,将结果返回给0进程,0进程得出准确率。
MPI并行程序
#include <iostream>
#include <vector>
#include <cstdlib>
#include <time.h>
#include <mpi.h>
#include <cassert>
#include <cstring>
#include <cmath>
#define PI 3.1415926535898
//单条数据的长度
#define MAX_LINE 20
//数据集的长度(从1开始计算)
#define DATA_LEN 11000000
#define EIGEN_NUM 4
//float dataSet[DATA_LEN * EIGEN_NUM]; //数据集
float (*dataSet)=(float(*))malloc(sizeof(float)*DATA_LEN*EIGEN_NUM);
int dataLen;//数据集的行数
double maleNum=0;//男性总数
double femaleNum=0;//女性总数
int main(int argc, char** argv) {
int i=0;
int j=0;
int my_rank; //当前进程id
int comm_sz; //进程的数目
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
double start, end,readTime;
MPI_Barrier(MPI_COMM_WORLD); /* IMPORTANT */
start = MPI_Wtime();
/************************进程0读取文件************************/
if(my_rank==0)
{
char buf[MAX_LINE]; //缓冲区
FILE *fp; //文件指针s
int len; //行字符个数
//读取文件
const char* fileLocation="E:\\test\\addVitalCapacityData.csv";
fp = fopen(fileLocation,"r");
if(fp == NULL)
{
perror("fp == NULL");
exit (1) ;
}
//逐行读取及写入数组
char *token;
const char s[2] = ",";
while(fgets(buf,MAX_LINE,fp) != NULL && i< DATA_LEN)
{
len = strlen(buf);
//删去换行符
buf[len-1] = '\0';
//分割字符串
token = strtok(buf, s);
//继续分割字符串
j = 0;
while( token != NULL )
{
dataSet[i*EIGEN_NUM + j]=atof(token);
token = strtok(NULL, s);
j = j+1;
}
i = i + 1;
}
dataLen=i;
printf("%d行4列的数据读取完毕\n",dataLen);
fclose(fp);
//计算男女个数
for(i=0;i<dataLen;i++){
if(dataSet[i*4]==1){maleNum=maleNum+1;}
if(dataSet[i*4]==2){femaleNum=femaleNum+1;}
}
readTime = MPI_Wtime();
//printf("Read data time = %f", readTime-start);
}
MPI_Bcast(&dataLen,1,MPI_INT,0,MPI_COMM_WORLD);
/************************并行计算************************/
/***********计算高斯分布***********/
/*向个进程散射分发数组*/
int *Sendcounts; //对每个进程分发的数据长度
Sendcounts = (int *) malloc(comm_sz * sizeof(int));//分配内存
for(i=0;i<comm_sz;i++)
{
if(i==comm_sz-1){Sendcounts[i]=(int) (dataLen/comm_sz+(dataLen%comm_sz))*EIGEN_NUM;}
else{Sendcounts[i]=(int) (dataLen/comm_sz)*EIGEN_NUM;}
//printf("进程%d分发到的数据长度:%d\n",i,Sendcounts[i]);
}
int receiveDataNum; //接收的数据长度
receiveDataNum=Sendcounts[my_rank];
int *displs; //相对于dataSet的内存偏移量
displs = (int *) malloc(comm_sz * sizeof(int)); //分配内存
displs[0]=0;
for(i=1;i<comm_sz;i++)
{
displs[i]=displs[i-1]+Sendcounts[i-1];
//printf("displs[i]=%d",displs[i]);
//printf("分发给进程%d的内存偏移量:%d\n",i,displs[i]);
}
//用来保存所接收到的数组
float (*receiveBuf)= (float*) malloc((receiveDataNum) * sizeof(float));
//printf("my_rank=%d,Sendcounts=%d,displs=%d,receiveDataNum=%d \n",my_rank,Sendcounts[my_rank],displs[my_rank],receiveDataNum);
MPI_Scatterv(dataSet,Sendcounts,displs,MPI_FLOAT,receiveBuf,receiveDataNum,MPI_FLOAT,0,MPI_COMM_WORLD);
/****求和****/
char *maenInf[6]={"maleLength","maleWeight","maleVC","femaleLength","femaleWeight","femaleVC"};
//声明求和函数
double getSum(float *data,int datalen,int sex,int column);
//男性身高、体重、肺活量
double maleLength=getSum(receiveBuf,receiveDataNum,1,1);
double maleWeight=getSum(receiveBuf,receiveDataNum,1,2);
double maleVC=getSum(receiveBuf,receiveDataNum,1,3);
//女性身高、体重、肺活量
double femaleLength=getSum(receiveBuf,receiveDataNum,2,1);
double femaleWeight=getSum(receiveBuf,receiveDataNum,2,2);
double femaleVC=getSum(receiveBuf,receiveDataNum,2,3);
//printf("p-maleLength=%f p-maleWeight=%f p-maleVC=%f\n",maleLength,maleWeight,maleVC);
//printf("p-femaleLength=%f p-femaleWeight=%f p-femaleVC=%f\n\n",femaleLength,femaleWeight,femaleVC);
double sendSum[]={maleLength,maleWeight,maleVC,femaleLength,femaleWeight,femaleVC};//每个进程所计算出的和
double *reciveSum=(double*) malloc((6*comm_sz) * sizeof(double)); //传给进程0的数组
/****求平均值****/
double mean[6]={0,0,0,0,0,0};
if(my_rank==0){
MPI_Gather(sendSum,6,MPI_DOUBLE,reciveSum,6,MPI_DOUBLE,0,MPI_COMM_WORLD);
for(i=0;i<comm_sz;i++){
for(j=0;j<6;j++){
mean[j]=mean[j]+reciveSum[i*6+j];
}
}
for(i=0;i<6;i++){
if(i<3){mean[i]=mean[i]/maleNum;}
if(i>=3){mean[i]=mean[i]/femaleNum;}
}
//打印平均值的最终结果
for(i=0;i<6;i++){
//printf("mean-%s=%.16f\n",maenInf[i],mean[i]);
if(i==5){printf("\n");}
}
}
else{
MPI_Gather(sendSum,6,MPI_DOUBLE,reciveSum,6,MPI_DOUBLE,0,MPI_COMM_WORLD);
}
//把平均值广播到所有进程
MPI_Bcast(&mean,6,MPI_DOUBLE,0,MPI_COMM_WORLD);
//打印每个进程获得的平均值
/*for(i=0;i<6;i++)
{
printf("my_rank=%d mean[%d]=%f\n",my_rank,i,mean[i]);
}*/
/****求标准差****/
double sendSigma[6]={0,0,0,0,0,0}; //每个进程上的局部累加
double *reciveSigma=(double*) malloc((6*comm_sz) * sizeof(double)); //传给进程0的数组
//声明求累加函数
double getSigma(float *data,int datalen,double mean,int sex,int column);
i=0;
for(int s=1;s<=2;s++){
for(int j=1;j<=3;j++){
sendSigma[i]=getSigma(receiveBuf,receiveDataNum,mean[i],s,j);
//printf("sendSigma[%d]=%f\n",i,sendSigma[i]);
i=i+1;
}
}
double standardDeviation[6]; //标准差
if(my_rank==0)
{
MPI_Gather(sendSigma,6,MPI_DOUBLE,reciveSigma,6,MPI_DOUBLE,0,MPI_COMM_WORLD);
double Sigma[6]={0,0,0,0,0,0}; //累加
for(i=0;i<comm_sz;i++){
for(j=0;j<6;j++){
Sigma[j]=Sigma[j]+reciveSigma[i*6+j];
}
}
double sexNum;
for(i=0;i<6;i++){
if(i<3)
{sexNum=maleNum;}
if(i>=3)
{sexNum=femaleNum;}
standardDeviation[i]=sqrt(Sigma[i]/sexNum);
//printf("Sigma[%d]=%f maleNum=%f",i,Sigma[i],sexNum);
//printf("第%d个标准差=%f\n",i,standardDeviation[i]);
}
}
else{
MPI_Gather(sendSigma,6,MPI_DOUBLE,reciveSigma,6,MPI_DOUBLE,0,MPI_COMM_WORLD);
}
MPI_Bcast(&standardDeviation,6,MPI_DOUBLE,0,MPI_COMM_WORLD);
//打印每个进程获得的标准差
/*for(i=0;i<6;i++)
{
printf("my_rank=%d standardDeviation[%d]=%f\n",my_rank,i,standardDeviation[i]);
if(i==5){printf("\n");}
}*/
/*********** 朴素贝叶斯 & 准确率测试 ***********/
//数据集有肺活量(VC),准确度判断
float preSexID;
float right=0;
float error=0;
//声明性别ID判断函数
int sexIDResult(float height,float weight,float VC,double *mean,double *standardDeviation);
for(int i=0;i<receiveDataNum/EIGEN_NUM;i++){
preSexID=sexIDResult(receiveBuf[i*EIGEN_NUM+1],receiveBuf[i*EIGEN_NUM+2],receiveBuf[i*EIGEN_NUM+3],mean,standardDeviation);
if(receiveBuf[i*EIGEN_NUM]==preSexID){right=right+1;}
else{
//printf("预测ID:%.0f 实际ID:%.0f \n",preSexID,receiveBuf[i*EIGEN_NUM]);
//printf("性别:%.0f,身高:%.2f,体重:%.2f,肺活量:%.0f \n",receiveBuf[i*EIGEN_NUM],receiveBuf[i*EIGEN_NUM+1],receiveBuf[i*EIGEN_NUM+2],receiveBuf[i*EIGEN_NUM+3]);
error=error+1;}
}
//printf("Right:%f\nError:%f\n",right,error);
float sendRuslt[2]={right,error};
/*for(i=0;i<comm_sz*2;i++)
{
printf("sendRuslt[%d]=%f\n",i,sendRuslt[i]);
}*/
float *reciveRuslt=(float*) malloc((2*comm_sz) * sizeof(float)); //传给进程0的数组
if (my_rank==0)
{
MPI_Gather(sendRuslt,2,MPI_FLOAT,reciveRuslt,2,MPI_FLOAT,0,MPI_COMM_WORLD);
float lastResult[2]={0,0};
float right;
float error;
for(i=0;i<comm_sz;i++){
lastResult[0]=lastResult[0]+reciveRuslt[2*i];
lastResult[1]=lastResult[1]+reciveRuslt[2*i+1];
}
double accuracy = lastResult[0]/(lastResult[0]+lastResult[1]);
printf("Accuracy:%f\n",accuracy);
}
else{
MPI_Gather(sendRuslt,2,MPI_FLOAT,reciveRuslt,2,MPI_FLOAT,0,MPI_COMM_WORLD);
}
MPI_Barrier(MPI_COMM_WORLD); /* IMPORTANT */
end = MPI_Wtime();
MPI_Finalize();
if (my_rank == 0) { /* use time on master node */
printf("Read data time = %f\n", readTime-start);
printf("Calculate time = %f\n",end-readTime);
printf("Run time = %f\n", end-start);
}
}
/*****************函数*****************/
/***********高斯分布函数***********/
//求和
double getSum(float *data,int recDatalen,int sex,int column)
{
double Sum=0;
for(int i=0;i<(recDatalen/EIGEN_NUM);i++)
{
if(data[i*EIGEN_NUM]==sex){
Sum=Sum+data[i*EIGEN_NUM+column];
}
}
return Sum;
}
//求pow((data[i]-mean),2)的累加
double getSigma(float *data,int recDatalen,double mean,int sex,int column){
double Sigma=0;
for(int i=0;i<(recDatalen/EIGEN_NUM);i++){
if(data[i*EIGEN_NUM]==sex){
Sigma=Sigma+pow(data[i*EIGEN_NUM+column]-mean , 2 );
//printf("sex=%d data[i]=%f mean=%f \n",sex,data[i*EIGEN_NUM+column],mean);
}
}
return Sigma;
}
/***********朴素贝叶斯函数***********/
//计算概率p(特征列column = x | 性别)
double getProbability(double x,int column,int sex,double mean,double standardDeviation)
{
double Probability; //计算出的概率
double u = mean;
double p = standardDeviation;
//高数分布概率密度函数 x:预测变量 u:样本平均值 p:标准差
p=pow(p,2);
Probability = (1 / (2*PI*p)) * exp( -pow((x-u),2) / (2*p) );
//printf("p(%s=%lf|性别=%s)=%.16lf\n",basicInfo[column],x,gender,Probability);
return Probability;
}
//返回性别ID结果
int sexIDResult(float height,float weight,float VC,double *mean,double *standardDeviation)
{
double maleP;//男性概率
double femaleP;//女性概率
double a=0.5; //男女比例各50%
maleP = a * getProbability(height,1,1,mean[0],standardDeviation[0]) * getProbability(weight,2,1,mean[1],standardDeviation[1])
* getProbability(VC,3,1,mean[2],standardDeviation[2]);
femaleP = a * getProbability(height,1,2,mean[3],standardDeviation[3]) * getProbability(weight,2,2,mean[4],standardDeviation[4])
* getProbability(VC,3,2,mean[5],standardDeviation[5]);
if(maleP > femaleP){return 1;}
if(maleP < femaleP){return 2;}
if(maleP == femaleP){return 0;}
}结果
本地运行结果如下图所示,计算时间从6.3秒变为2.5秒,这个优化比例是比较明显的:

服务器运行结果如下图所示,计算时间从7.8秒变为3.9秒,这个优化比例是比较明显的:
代码:https://download.csdn.net/download/admiz/16162449
