
作者:吕昱峰 来源:知乎
摘要
MindNLP的开发大概也有小一年时间了,整体而言面临着诸多的问题,并且还伴随着LLM带来的一系列冲击和挑战。作为一个依赖昇思MindSpore向上生长的后来者NLP框架,其实也要考虑怎么扩大生态的问题。
还是那句俗话——打不过就加入。不过对于开源世界而言,又何谈加入,你中有我我中有你才是常态,况且在前两天Pytorch2.1+Ascend官宣的这个当口,生态嫁接毫无疑问是最优解。闲话就到这,进入正题。
01
MindNLP的Datasets
MindNLP设计之初是希望尽可能全面利用昇思MindSpore的各个优势特性的,包括函数式融合编程、动态图功能、数据处理引擎等等。这里单独把数据处理引擎拎出来详细说说。
1.1MindSpore数据处理引擎
图1: MindSpore数据引擎Pipeline示意图
如图所示,数据引擎的设计是流水线式(Pipeline)[1]的,这跟Tensorflow的Dataset以及Pytorch的Map-style Datasets很像,主要面向高性能数据处理。
在大家还在卷小模型魔改+小数据集刷榜的时代,数据预处理通常都会做成离线的,这样可以使用Python尽可能灵活地进行处理,并且通常服务器的大内存能够装得下,大家会一次性把所有数据都塞进去,然后开个多进程就处理。结束了再加载成Tensor送到网络里进行训练。但是即便是这样,数据集稍微大一些,可能就要花费数小时甚至数天的时间进行数据集的预处理。
而Pipeline的方式主打几个能力:
1、按需加载
2、异步处理
3、并行
其中1和2可以着重展开来说说。以文本数据为例,如果使用最简单的Python加载预处理逻辑(也就是Pytorch Dataloader)整体执行流程如下:
数据集全量加载至内存 -> 全量遍历并预处理 -> 单条数据打包Batch -> 循环返回每个Batch
而Pipeline的加载方式为
比较形象的描述是:现在有个指针指向数据集文件的开头,我们每次取一个batch size的数据,指针前进batch size,直到取完。
显然,每次只取适量的数据可以大幅缩减内存消耗,并且预处理过程中会产生的中间变量也可以被压缩至很小。此外,这样的方式可以将离线数据预处理转为在线:
取Batch size条数据加载 -> Batch size条数据遍历并预处理 -> 返回一个Batch
图2: 数据处理与网络计算流水线
数据处理流水线不断进行数据处理,并把处理后的数据发送到Device侧的缓存;在一个Step执行结束后,直接从Device的缓存中读取下一个Step的数据。在网络训练的同时数据也在处理,各司其职。
当然这种方式同样是双刃剑,在提升内存利用率和性能的同时,会引入易用性问题。图一中的map即异步处理,在配置每一个数据预处理操作后,并不会直接执行并返回结果,这对需要精细化控制且特殊条件多的数据并不友好,极有可能发生pipeline执行中突然触发异常的情况。
但是,LLM改变了这个情况,所有的Task都变成了Next Token Prediction,所有的数据处理也变成了清洗+Tokenize,且数据量庞大并在业务场景常为流式数据,Pipeline很自然地成为最优解(估计这也是Pytorch开始做pipeline、HuggingFace datasets也是pipeline的主要原因)。
1.2MindNLP数据集支持问题
前面也提到,MindNLP的数据处理是完全使用了昇思MindSpore数据处理引擎的,并且一年内做了20+数据集的支持(对标torchtext)。但是实际使用过程中,显然各类NLP任务所需要的数据集绝不止这些,面对一个开放域很难去不停地做适配。
此外昇思MindSpore的Dataset也引发了一些问题,主要问题在于MindSpore Dataset设计了三类加载器,即:
1、特定数据集加载器:如IMDBDataset、EnWik9Dataset等
2、文本抽象加载器:TextFileDataset
3、用户自定义加载器:GeneratorDataset
如果使用1,则意味着需要不断增加适配;使用2则需要提前对如xml、json等格式进行加载前的预处理,这违背了Pipeline高效率的设计理念,并且仍然面临着需要手动适配的开发量;使用3则意味着图1中的第一步又回到了全量加载,这显然不是我们想要的。但是因为快速支持数据集的需要,我们还是选择了1+3的方式进行支持。
这并不高效,且每次都要单独适配。那么有没有什么一劳永逸的办法?
02
HuggingFace生态嫁接
MindNLP的数据集加载,想要实现的无非两点:
1、无需适配即可支持大量数据集
2、使用高效的Pipeline
既然自己做不到,就借助生态的力量吧。HuggingFace在Transformers仓之外,开发了面向AI训练各个流程的库,其中Datasets经过了数年的积累,支持了大量的数据集,并且由于HuggingFace提供了托管服务,诸多新数据集也直接在Datasets hub上直接发布。使用Datasets将问题1解决了,再来看第二个问题。
其实大部分使用MindSpore Dataset的人基本都是选择两种处理方式:
1、离线预处理为MindRecord,然后使用MindDataset加载
2、数据集加载至内存,然后使用 特定数据集加载器/GeneratorDataset 加载
为了能够做在线预处理,方法1显然是不可取的,那么将HuggingFace Datasets进行嫁接的思路也很简单,我考虑了两个思路下面展开讲一下。
2.1嫁接数据集下载
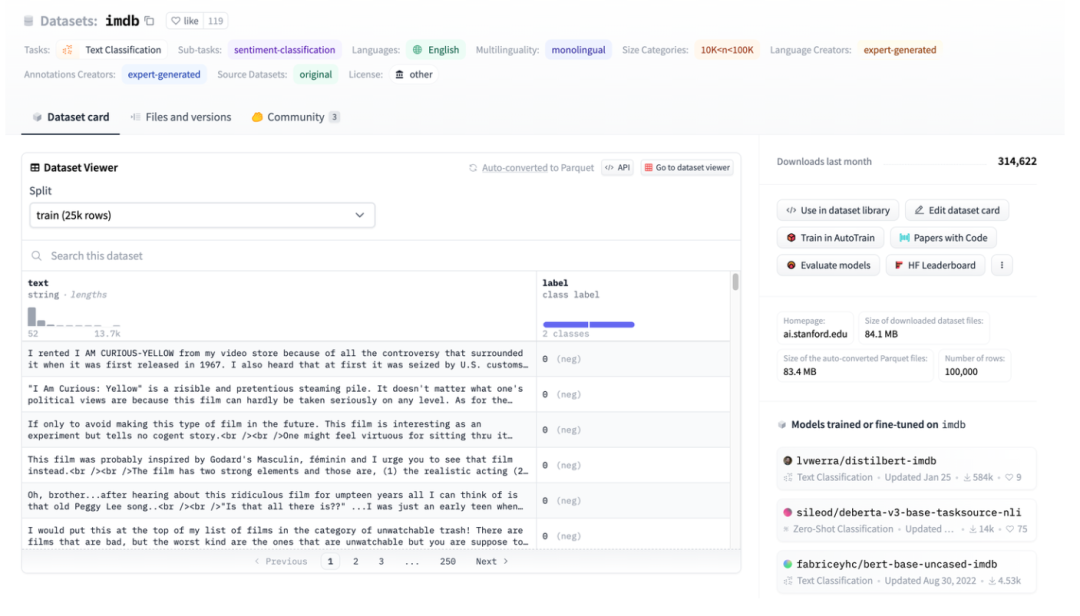 图3: HuggingFace Dataset图示,以IMDB为例
图3: HuggingFace Dataset图示,以IMDB为例
图3是imdb的页面截图,可以看到数据已经被很好地进行了结构化处理了,那么直接使用HuggingFace Datasets进行下载,然后直接使用抽象数据加载器TextFileDataset读取处理好的文件,就可以直接进行使用。
图4: TextFileDataset接口
可以看到TextFileDataset只需要传入文件路径或路径列表就可以加载。但是在实操的时候却遇到了一个问题——HuggingFace Datasets用的是Apache Arrow文件。
图5: HuggingFace Datasets的Arrow格式介绍
Apache Arrow[2]是一种语言无关的、多系统可以zero copy的高性能交换数据的格式标准。这意味着MindSpore的Dataset并不能直接简单读取,虽然也可以使用pyarrow库进行操作,但是这又增加了复杂度,并且回到了加载前需要预处理的状态。但是柳暗花明,Arrow文件的特性反而更适合MindSpore的Dataset。
2.2Arrow格式的优势
在Multiwalker环境中,双足机器人试图扛起它们身上的货物向右走。几个机器人扛起一个大货物,它们需要通力合作,如下图所示。
HuggingFace使用了Apache Arrow格式,具备几个明显的优势:
1、Arrow的标准格式允许零拷贝读取,这实际上消除了所有序列化开销。
2、Arrow是面向列的,因此查询和处理数据片或数据列的速度更快。
3、Arrow将每个数据集都视为内存映射文件,访问大文件部分数据时不必将整个文件加载进来,且多进程可共享内存。内存映射允许在设备内存相对较小的机器上使用大型数据集,加载完整的英文维基百科数据集只需要几MB的RAM。
4、加载数据时可设置streaming参数进行流式加载。
这时回过头再去看MindSpore数据引擎的设计:按需加载、在线处理,和HuggingFace Datasets天作之合。
2.3 MindNLP适配
由于HuggingFace Datasets加载的arrow文件本身就是内存映射文件,所以并不存在需要拷贝至内存这一步,且使用index索引也并不会进行全量加载,因此可以直接将其作为源加载数据直接送入GeneratorDataset使用。
图6: GeneratorDataset接口
GeneratorDataset的构造主要需要source数据以及每一列数据对应的column name,回看一下图3可以看到HuggingFace Datasets已经给所有的column进行了命名。下面是截取的核心代码:
from mindspore.dataset import GeneratorDataset
from datasets import load_dataset as hf_load
......
def load_dataset(...):
ds_ret = hf_load(path,
name=name,
data_dir=data_dir,
data_files=data_files,
split=split,
cache_dir=cache_dir,
features=features,
download_config=download_config,
download_mode=download_mode,
verification_mode=verification_mode,
keep_in_memory=keep_in_memory,
save_infos=save_infos,
revision=revision,
streaming=streaming,
num_proc=num_proc,
storage_options=storage_options,
)
if isinstance(ds_ret, (list, tuple)):
ds_dict = dict(zip(split, ds_ret))
else:
ds_dict = ds_ret
datasets_dict = {}
for key, raw_ds in ds_dict.items():
column_names = list(raw_ds.features.keys())
source = TransferDataset(raw_ds, column_names) if isinstance(raw_ds, Dataset) \
else TransferIterableDataset(raw_ds, column_names)
ms_ds = GeneratorDataset(
source=source,
column_names=column_names,
shuffle=shuffle,
num_parallel_workers=num_proc if num_proc else 1)
datasets_dict[key] = ms_ds
if len(datasets_dict) == 1:
return datasets_dict.popitem()[1]
return datasets_dict
处理的步骤也很简单:
1、使用HuggingFace Datasets的load_dataset加载
2、使用封装的中转类进行封装
3、传入GeneratorDataset
为了易用性的考虑,我们保持load_dataset接口的参数设置和HuggingFace Datasets完全一致,但是返回的是MindSpore数据引擎可处理的类或Dict,这样即可完成昇思MindSpore数据处理能力的无缝衔接。
下面再简单说一下中转类的构造。
HuggingFace Datasets的数据类型包括Dataset和IterableDataset:
There are two types of dataset objects, a Datasetand an IterableDataset. Whichever type of dataset you choose to use or create depends on the size of the dataset. In general, anIterableDatasetis ideal for big datasets (think hundreds of GBs!) due to its lazy behavior and speed advantages, while Datasetis great for everything else. This page will compare the differences between Datasetand anIterableDatasetto help you pick the right dataset object for you.[3]
遍历这两个类型的数据集时返回的是一个dict,这并不能被MindSpore的数据处理引擎支持,因此做了两个中转类,将dict里的数据进行读取,不加入其他额外的操作。针对Dataset,构造一个TransferDataset类并在__getitem__方法中进行读取。
class TransferDataset():
"""TransferDataset for Huggingface Dataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __getitem__(self, index):
return tuple(self.ds[int(index)][name] for name in self.column_names)
def __len__(self):
return self.ds.dataset_size
而针对流式数据IterableDataset,则需要在__iter__方法进行读取,将TransferIterableDataset构造为可迭代对象。
class TransferIterableDataset():
"""TransferIterableDataset for Huggingface IterableDataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __iter__(self):
for data in self.ds:
yield tuple(data[name] for name in self.column_names)
至此,一个工作量不大,又能够完全将HuggingFace Datasets进行嫁接的方案宣告完成。相较于PaddleNLP的嫁接策略更是简单优雅。
03
结论
作为一个开源框架其实有大量的开源资源可以利用,所谓的南北向生态的不断扩展,也未必就是适配,我用用你你用用我,快快乐乐没有烦恼。本次HuggingFace Datasets嫁接到昇思MindSpore实操分享中,将对昇思MindNLP有了更深刻的认知,也有利于拓展昇思MindSpore生态。
参考文献
[1]https://www.mindspore.cn/docs/zh-CN/r2.1/design/data_engine.htm
[3]https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable
90后程序员开发视频搬运软件、不到一年获利超 700 万,结局很刑! 谷歌证实裁员,涉及 Flutter、Dart 和 Python 团队 中国码农的“35岁魔咒” Xshell 8 开启 Beta 公测:支持 RDP 协议、可远程连接 Windows 10/11 MySQL 的第一个长期支持版 8.4 GA 开源日报 | 微软挤兑Chrome;阳痿中年的福报玩具;神秘AI能力太强被疑GPT-4.5;通义千问3个月开源8模型 Arc Browser for Windows 1.0 正式 GA Windows 10 市场份额达 70%,Windows 11 持续下滑 GitHub 发布 AI 原生开发工具 GitHub Copilot Workspace JAVA 下唯一一款搞定 OLTP+OLAP 的强类型查询这就是最好用的 ORM 相见恨晚