技术报告:Efficient and Effective Text Encoding for Chinese LLaMA AND Alpaca
Introduction
首先作者说了最近ChatGPT等模型在AGI领域表现出了很好的性能,但是收到算力、闭源的限制,阻碍了研究。
然后Meta与MIT分别开源了LLaMA、Alpaca,这让研究有了希望。
然后作者说这两个模型是基于英文预料训练的,词表中的中文只有几百个,中文性能不好,然后作者通过扩充词表等方法证明了LLaMA与Alpaca在其他语言可以有提高表现的可能性。
文章主要有以下贡献:
- 为LLaMA、Alpaca的原始词表拓展了中文词表用20000个token。
- 用Lora减少了算力消耗。
- 验证 LLaMA、Alpaca在中文上面的表现。
- 开源了研究与资源。
Chinese LLaMA
LLaMA是一个在1.4T左右token上预训练的模型,但是它的中文能力一塌糊涂(虽然llama支持回退中文字符,但是字节码不能很好的表示中文),为了解决这个问题,作者做了如下改进:
- 为了增强tokenizer使它增强Chinese text,作者用Sentence Piece训练了一个新的中文tokenizer,与原始的词表合并。
- 修改embedding去适配新的词表,新的向量为了不影响以前的token,添加在了以前的embedding matrices末尾。
初步实验展示,在表达更清楚的同时,所需要的token长度几乎少了一倍。

Chinese Alpaca
得到Chinese LLaMA后,采取指令微调的形式去获得Chinese Alpaca,其中属于格式如下:

与原始模型的不同是没有input(我觉得这样更符合中国方式的问答),如果下游数据input中含有数据,通过 \n合并instruction与input,其中\n被视为一个额外的 padding token。
Lora-Fine-tuning
这个阶段与以前并无二致,在LLaMA到Chinese-LLaMA,Alpaca到Chinese Alpaca阶段都是使用的这个技术。
实验
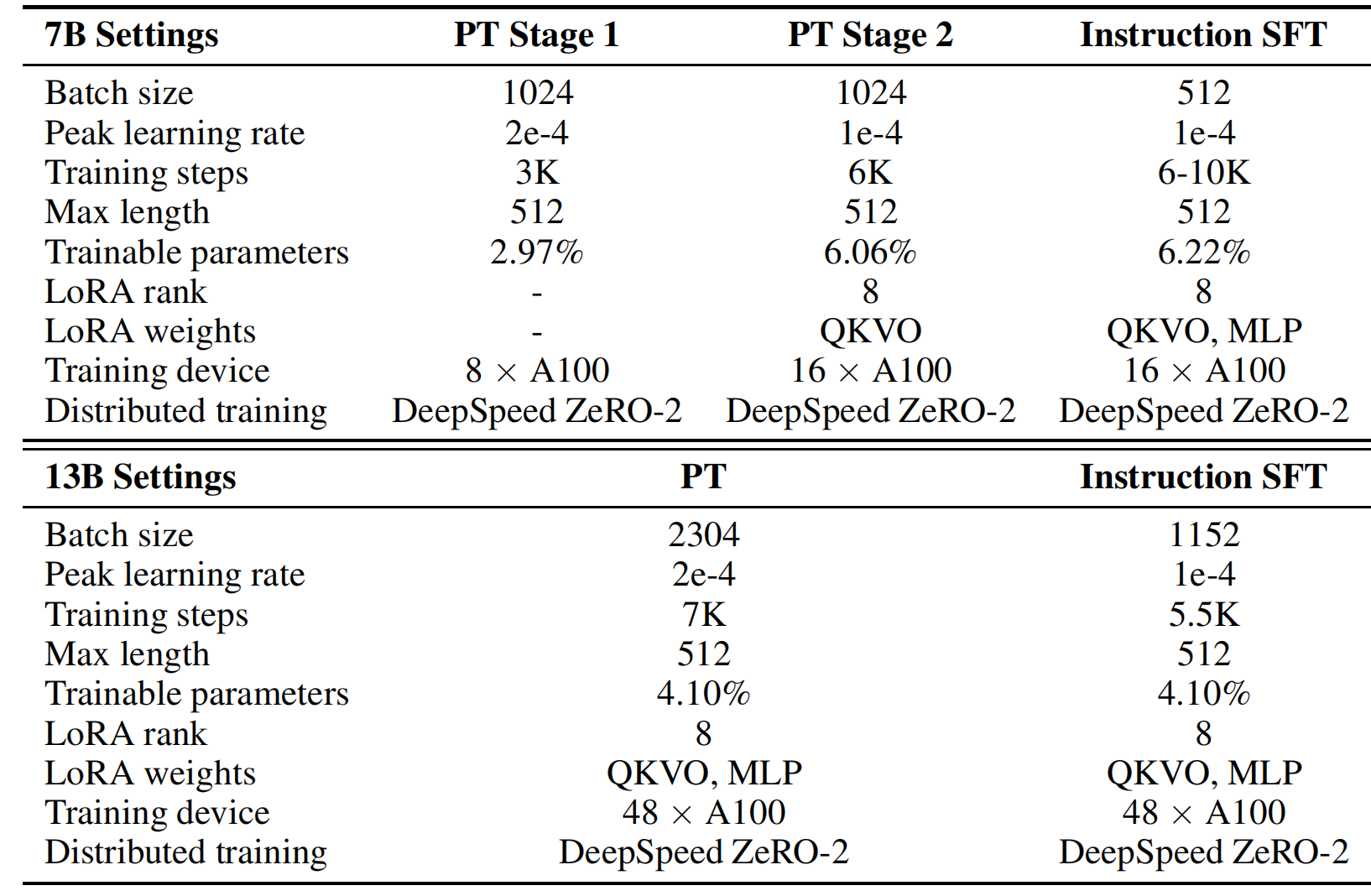
7B
pre- training
阶段1:我们在模型中固定transformer编码器的参数,并仅训练
Embedding,在最小化干扰的同时调整新添加的中文词向量
到原始模型。
阶段2:将LoRA权重(适配器)添加到注意力机制中,并训练ebeddings、LM头和新添加的LoRA参数。
Instruction-Tuning
指令微调在获得预训练模型后,我们还使用LoRA进行高效的微调,增加了可训练参数的数量 。
通过向MLP层添加LoRA适配器。我们使用大约2M数据点,并爬取了SFT数据以调整7B模型。
13B
Pre-Training
预训练13B模型的预训练过程与7B的基本相同模型,除了我们在预训练中跳过阶段1。我们直接把LoRA应用到 训练的注意事项和mlp,同时将嵌入和LM头设置为可训练的。
Instruct-Tuning
指令微调LoRA设置和可训练参数保持不变,训练的阶段。我们为13B模型使用额外的1M爬取的自指导数据点微调,导致13B模型的总数据大小为3M。
超参数: