学更好的别人,
做更好的自己。
——《微卡智享》

本文长度为1739字,预计阅读5分钟
前言
做为pyTorch的刚入门者,需要自己再做Demo进行练习,所以这个入门是一个系列,从pyTorch开始的训练,保存模型,后续再用C++ OpenCV DNN进行推理,再移植到Andorid中直接实现手写数学识别,算是个整套流程的小项目实战。今天是第一篇,写一个最简单的全连接Minist数据集pyTorch的训练。

实现效果
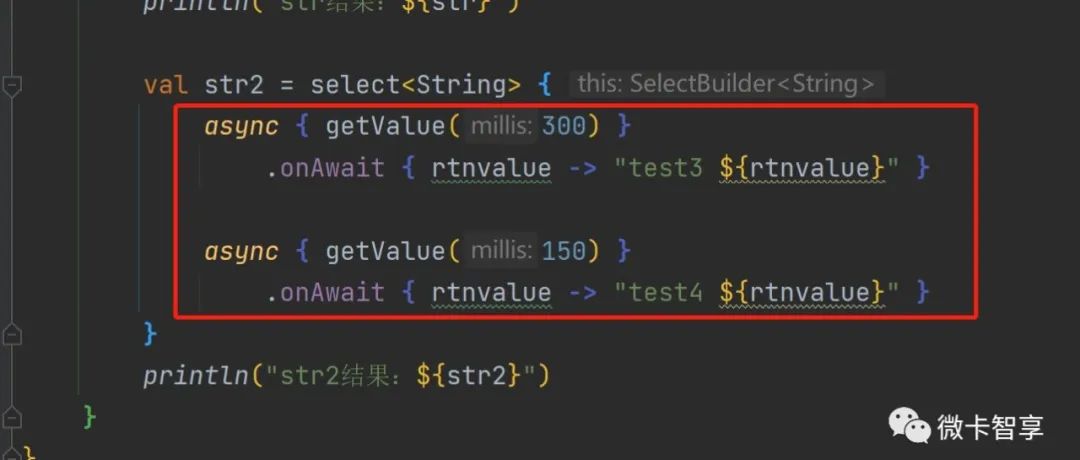
代码实现

微卡智享
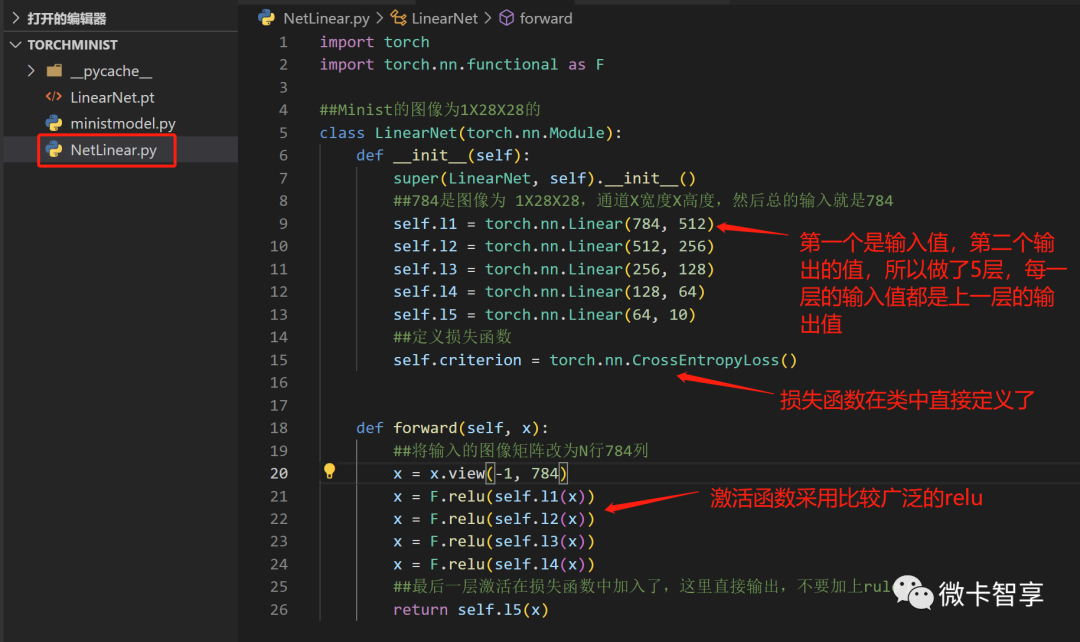
全连接网络模型
import torch
import torch.nn.functional as F
##Minist的图像为1X28X28的
class LinearNet(torch.nn.Module):
def __init__(self):
super(LinearNet, self).__init__()
##784是图像为 1X28X28,通道X宽度X高度,然后总的输入就是784
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
##定义损失函数
self.criterion = torch.nn.CrossEntropyLoss()
def forward(self, x):
##将输入的图像矩阵改为N行784列
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
##最后一层激活在损失函数中加入了,这里直接输出,不要加上rule了
return self.l5(x)全连接网络模型也是非常简单,从Init初始化函数中可以看到,就是五层的Linear,每一层的输入值都是上一层的输出值,因为Minist数据集中的图像者阳1*28*28的,所以第一层的输入就是 1X28X28 = 784,此处在创建LinearNet类中,把损失函数已经定义好了,在外面可以直接调用。整个类也非常简单。
训练模型
训练模型的文件这个算是本篇的重点,因为后面再用别的网络模型训练时,都是用这个文件进行训练的,我们根据设置的模型名称不同,来加载不同的训练模型。所以就创建了一个ministmodel.py的文件来编写
01
导入相关文件及基础参数
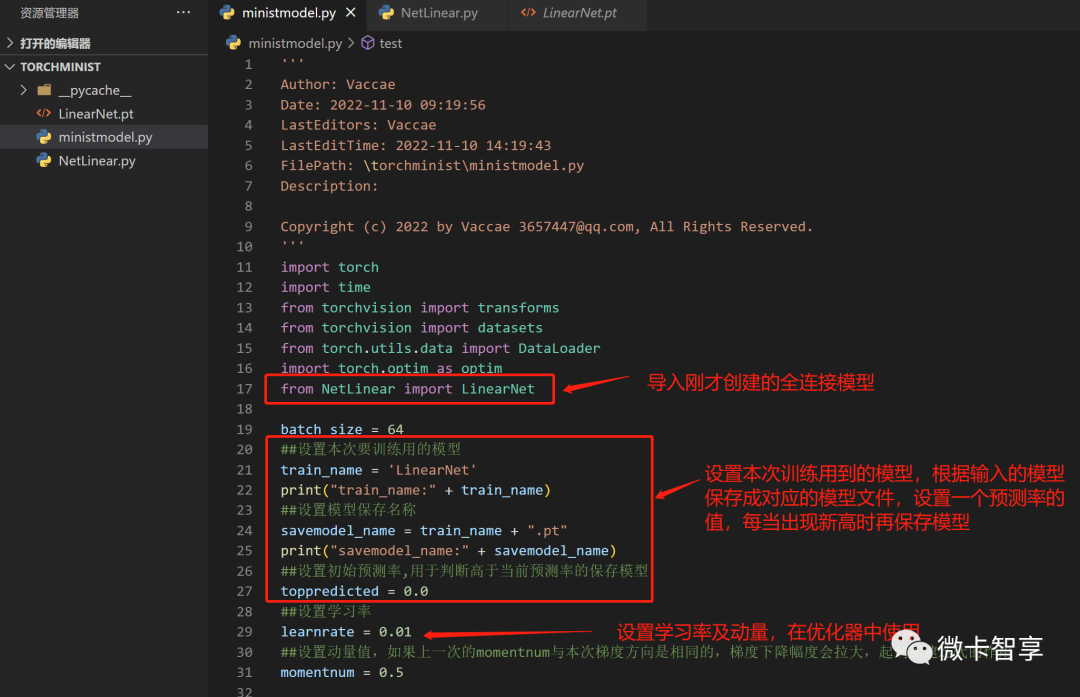
上图中可以看出,这里我们导入了上面已经创建的LinearNet的模型,然后设置了几个参数,主要是设定本次训练采用哪种模型,这样做就是每次换训练模型,训练这块的代码可以复用了,不需要Ctrl + C和Ctrl + V。
02
加载Minist数据集
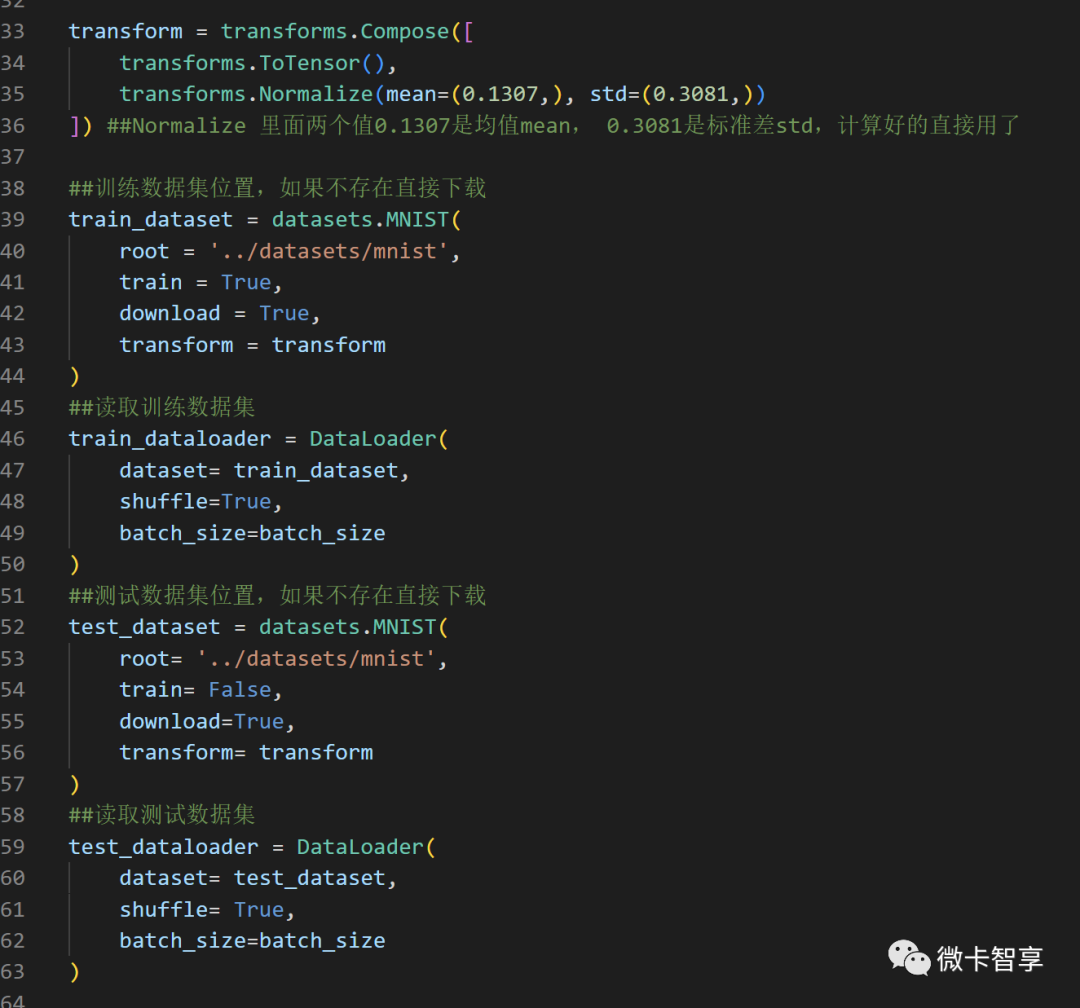
最上面的transfrom中均值和标准差,因为网上好多已经都提前算好了,所以这里直接就输入,调用训练集和测试集,通过torchvision实现,设置目录后,如果当前目录中不存在,则自动下载。
03
加载模型
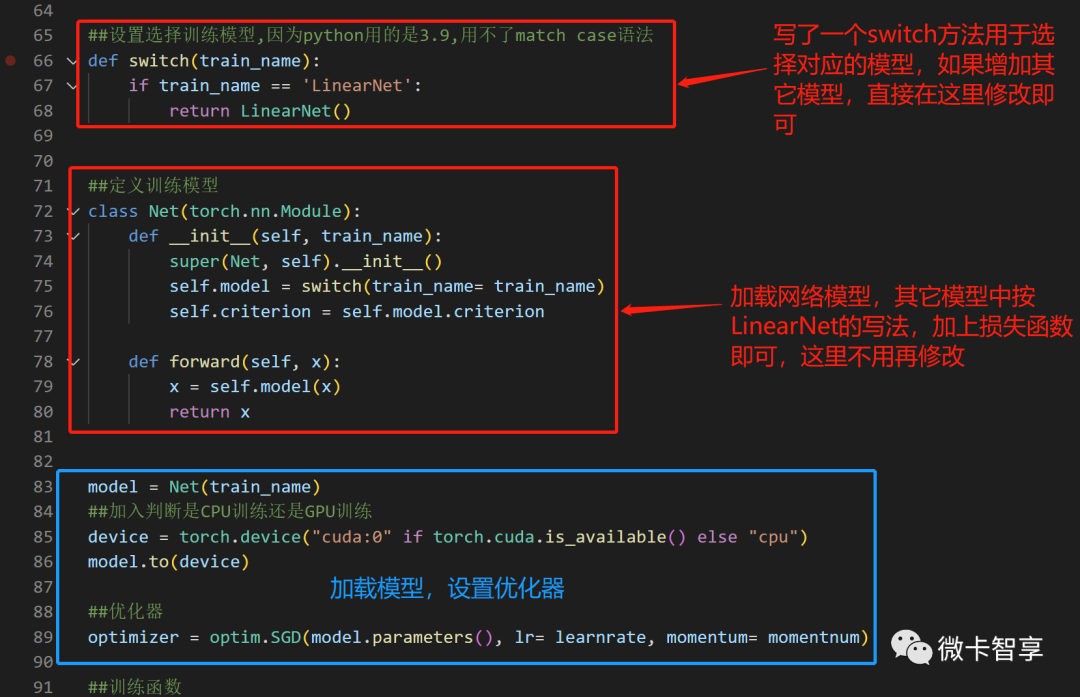
加入了一个switch的函数,用于处理当前加载的模型,如果增加新的模型,直接根据输入的返回新的模型即可,因为我这用的是python 3.9版本,没有switch的方法实现,只能自己写if else了,在python 3.10后有了match case的语法。
蓝框中的加载模型,根据前面定义的train_name直接选择对应模型,设置优化器也是通过前面定义的学习率和动量,接下来就可以开始训练了。
04
训练并保存模型
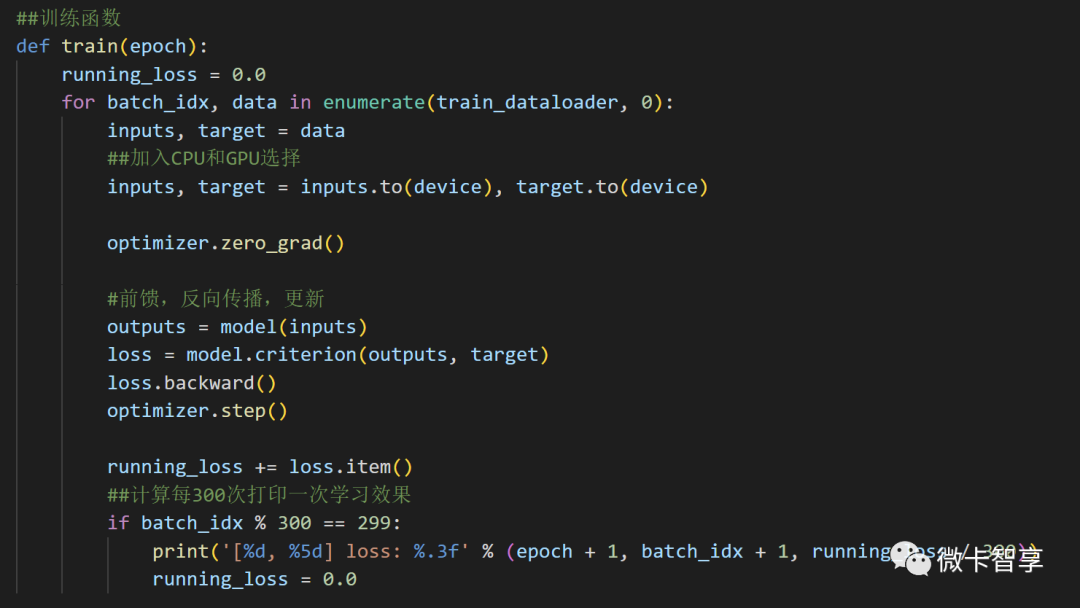
训练函数
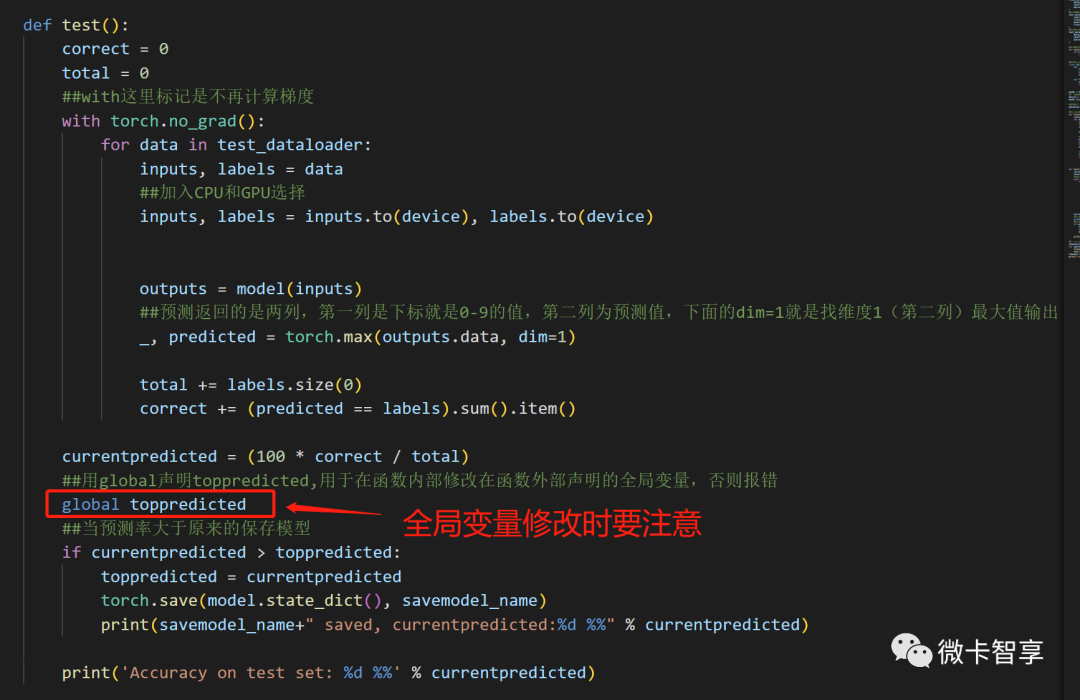
测试函数
测试函数要注意我们最开始定义的toppredicted这个变量,当时说过,判断预测率高于现在的我们就更新预测率,最保存当前的模型,用global声明toppredicted,用于在函数内部修改在函数外部声明的全局变量,否则会报错。
保存的模型文件
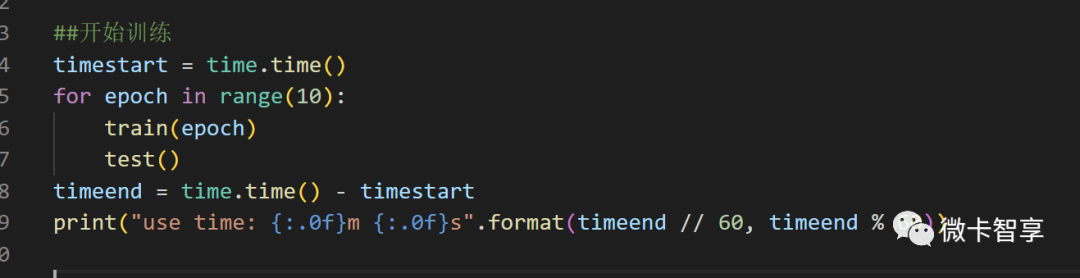
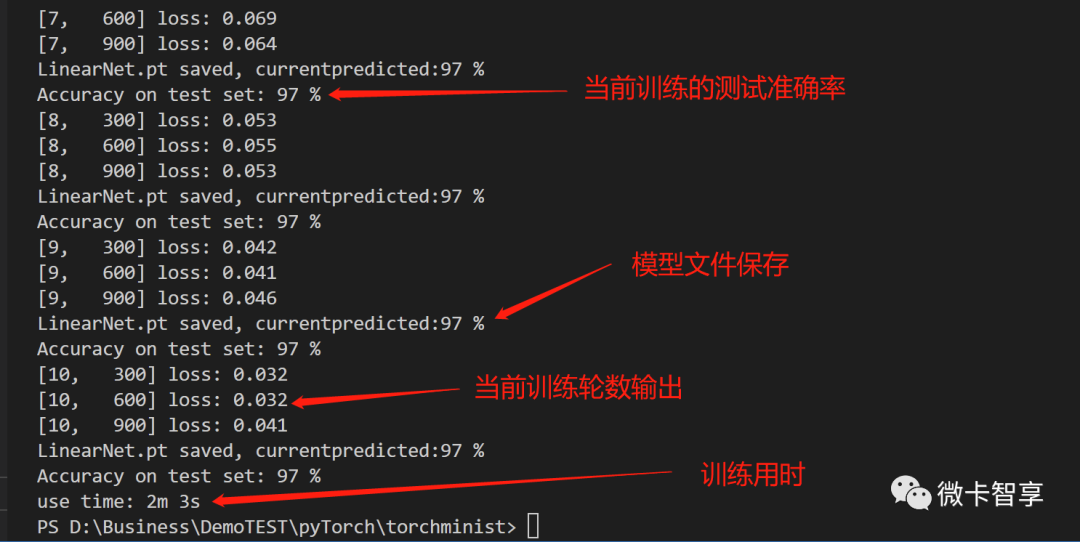
开始训练
最后就是开始训练了,一共设置了10轮训练,当训练完成后打印出总共训练的用时。完整的代码如下:
import torch
import time
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
from NetLinear import LinearNet
batch_size = 64
##设置本次要训练用的模型
train_name = 'LinearNet'
print("train_name:" + train_name)
##设置模型保存名称
savemodel_name = train_name + ".pt"
print("savemodel_name:" + savemodel_name)
##设置初始预测率,用于判断高于当前预测率的保存模型
toppredicted = 0.0
##设置学习率
learnrate = 0.01
##设置动量值,如果上一次的momentnum与本次梯度方向是相同的,梯度下降幅度会拉大,起到加速迭代的作用
momentnum = 0.5
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.1307,), std=(0.3081,))
]) ##Normalize 里面两个值0.1307是均值mean, 0.3081是标准差std,计算好的直接用了
##训练数据集位置,如果不存在直接下载
train_dataset = datasets.MNIST(
root = '../datasets/mnist',
train = True,
download = True,
transform = transform
)
##读取训练数据集
train_dataloader = DataLoader(
dataset= train_dataset,
shuffle=True,
batch_size=batch_size
)
##测试数据集位置,如果不存在直接下载
test_dataset = datasets.MNIST(
root= '../datasets/mnist',
train= False,
download=True,
transform= transform
)
##读取测试数据集
test_dataloader = DataLoader(
dataset= test_dataset,
shuffle= True,
batch_size=batch_size
)
##设置选择训练模型,因为python用的是3.9,用不了match case语法
def switch(train_name):
if train_name == 'LinearNet':
return LinearNet()
##定义训练模型
class Net(torch.nn.Module):
def __init__(self, train_name):
super(Net, self).__init__()
self.model = switch(train_name= train_name)
self.criterion = self.model.criterion
def forward(self, x):
x = self.model(x)
return x
model = Net(train_name)
##加入判断是CPU训练还是GPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
##优化器
optimizer = optim.SGD(model.parameters(), lr= learnrate, momentum= momentnum)
##训练函数
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_dataloader, 0):
inputs, target = data
##加入CPU和GPU选择
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
#前馈,反向传播,更新
outputs = model(inputs)
loss = model.criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
##计算每300次打印一次学习效果
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
##with这里标记是不再计算梯度
with torch.no_grad():
for data in test_dataloader:
inputs, labels = data
##加入CPU和GPU选择
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
##预测返回的是两列,第一列是下标就是0-9的值,第二列为预测值,下面的dim=1就是找维度1(第二列)最大值输出
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
currentpredicted = (100 * correct / total)
##用global声明toppredicted,用于在函数内部修改在函数外部声明的全局变量,否则报错
global toppredicted
##当预测率大于原来的保存模型
if currentpredicted > toppredicted:
toppredicted = currentpredicted
torch.save(model.state_dict(), savemodel_name)
print(savemodel_name+" saved, currentpredicted:%d %%" % currentpredicted)
print('Accuracy on test set: %d %%' % currentpredicted)
##开始训练
timestart = time.time()
for epoch in range(10):
train(epoch)
test()
timeend = time.time() - timestart
print("use time: {:.0f}m {:.0f}s".format(timeend // 60, timeend % 60))完

往期精彩回顾

超简单的pyTorch训练->onnx模型->C++ OpenCV DNN推理(附源码地址)