实验目的
根据算符优先分析法,对表达式进行语法分析,使其能够判断一个表达式是否正确。通过算符优先分析方法的实现,加深对自下而上语法分析方法的理解。
实验内容
1、输入文法。可以是如下算术表达式的文法(你可以根据需要适当改变):
E→E+T|E-T|T
T→T*F|T/F|F
F→(E)|i
2、对给定表达式进行分析,输出表达式正确与否的判断。
程序输入/输出示例:
输入:1+2;
输出:正确
输入:(1+2)/3+4-(5+6/7);
输出:正确
输入:((1-2)/3+4
输出:错误
输入:1+2-3+(*4/5)
输出:错误
实验过程
(1)读取文法,数据预处理
从文件中读取文法、终结符和非终结符。本部分处理与实验二中读取文法的方法一致。
def data_input(): # 读取文法
with open("input2.txt", 'r+', encoding="utf-8") as f:
temp = f.readlines()
for i in temp:
line = str(i.strip("\n"))
formules.append(line)
if line[0] not in non_ter:
non_ter.append(line[0])
grammarElement.setdefault(line[0], line[5:])
else:
grammarElement[line[0]] += "|" + line[5:]
for i in temp:
line = str(i.strip("\n")).replace(" -> ", "")
for j in line:
if j not in non_ter and j not in terSymblo:
terSymblo.append(j)
if 'ε' in terSymblo: terSymblo.remove('ε')
(2)求firstVT集:
def get_fistVT(formule):
x = formule[0]
ind = non_ter.index(x)
index = []
i = 5
if formule[i] in terSymblo and formule[i] not in firstVT[x]: # 首位为终结符 P->a...
firstVT[x] += formule[i]
elif formule[i] in non_ter: # 首位为非终结符
for f in firstVT[formule[i]]:
if f not in firstVT[x]:
firstVT[x] += f
if i + 1 < len(formule):
if formule[i + 1] in terSymblo and formule[i + 1] not in firstVT[x]: # P->Q..
firstVT[x] += formule[i + 1]
(3)求lastVT集
def get_lastVT(formule):
x = formule[0]
i = len(formule) - 1
if formule[i] in terSymblo and formule[i] not in lastVT[x]:
lastVT[x] += formule[i]
elif formule[i] in non_ter:
for f in lastVT[formule[i]]:
if f not in lastVT[x]:
lastVT[x] += f
if formule[i - 1] in terSymblo and formule[i - 1] not in lastVT[x]:
lastVT[x] += formule[i - 1]
(4)算符优先分析表
同样使用二维字典进行存储,先编写二维字典的更新函数
def addtodict2(thedict, key_a, key_b, val): # 设置二维字典的函数
if key_a in thedict.keys():
thedict[key_a].update({
key_b: val})
else:
thedict.update({
key_a: {
key_b: val}})
之后求算符优先分析表
def analy(formule): #算符优先分析表
start = 5
end = len(formule) - 2
if start == end: return
for i in range(start, end):
if formule[i] in terSymblo and formule[i + 1] in terSymblo:
addtodict2(data, formule[i], formule[i + 1], "=")
if formule[i] in terSymblo and formule[i + 1] in non_ter and formule[i + 2] in terSymblo:
addtodict2(data, formule[i], formule[i + 2], "=")
if formule[i] in terSymblo and formule[i + 1] in non_ter:
for j in firstVT[formule[i + 1]]:
addtodict2(data, formule[i], j, "<")
if formule[i] in non_ter and formule[i + 1] in terSymblo:
for j in lastVT[formule[i]]:
addtodict2(data, j, formule[i + 1], ">")
if formule[i + 1] in terSymblo and formule[i + 2] in non_ter:
for j in firstVT[formule[i + 2]]:
addtodict2(data, formule[i + 1], j, "<")
if formule[i + 1] in non_ter and formule[i + 2] in terSymblo:
for j in lastVT[formule[i + 1]]:
addtodict2(data, j, formule[i + 2], ">")
(5)算符优先算法分析过程
首先是过程中要用到的过程函数
def reverseString(string):
return string[::-1]
初始化两个栈
def initStack(string):
# 分析栈,入栈#
analysisStack = "#"
# 当前输入串入栈,即string逆序入栈
currentStack = reverseString(string)
# 调用分析函数
toAnalyze(analysisStack, currentStack)
寻找分析栈最顶终结符元素,返回该元素及其下标
def findVTele(string):
ele = '\0'
ele_index = 0
for i in range(len(string)):
if (string[i] in terSymblo):
ele = string[i]
ele_index = i
return ele, ele_index
```
然后才是具体分析过程
根据栈中内容进行分析
```python
def toAnalyze(analysisStack, currentStack):
global analyzeResult
global analyzeStep
analyzeStep += 1
analysisStack_top, analysisStack_index = findVTele(analysisStack) # 分析栈最顶终结符元素及下标
currentStack_top = currentStack[-1] # 当前输入串栈顶
relation = data[analysisStack_top][currentStack_top]
if relation == '<':
print(" {:^5} {:^15} {:^9} {:^15} {:^12} ".format(analyzeStep, analysisStack, relation,
reverseString(currentStack), '移进'))
analysisStack += currentStack_top
currentStack = currentStack[:-1]
toAnalyze(analysisStack, currentStack)
elif relation == '>':
print(" {:^5} {:^15} {:^9} {:^15} {:^12} ".format(analyzeStep, analysisStack, relation,
reverseString(currentStack), '归约'))
currenChar = analysisStack_top
temp_string = ""
for i in range(len(analysisStack) - 1, -1, -1):
if (analysisStack[i] >= 'A' and analysisStack[i] <= 'Z'):
temp_string = analysisStack[i] + temp_string
continue
elif (data[analysisStack[i]][currenChar] == '<'):
break;
temp_string = analysisStack[i] + temp_string
currenChar = analysisStack[i]
if (temp_string in sentencePattern):
analysisStack = analysisStack[0:i + 1]
analysisStack += 'N'
toAnalyze(analysisStack, currentStack)
else:
print("归约出错!待归约串为:", temp_string, "--->产生式右部无此句型!")
analyzeResult = False
return
elif (relation == '='):
if (analysisStack_top == '#' and currentStack_top == '#'):
print(" {:^5} {:^15} {:^9} {:^15} {:^12} ".format(analyzeStep, analysisStack, relation,
reverseString(currentStack), '完成'))
analyzeResult = True
return
else:
print(" {:^5} {:^15} {:^9} {:^15} {:^12} ".format(analyzeStep, analysisStack, relation,
reverseString(currentStack), '移进'))
analysisStack += currentStack_top
currentStack = currentStack[:-1]
toAnalyze(analysisStack, currentStack)
elif (relation == None):
print(" {:^5} {:^15} {:^9} {:^15} {:^12} ".format(analyzeStep, analysisStack, 'None',
reverseString(currentStack), '报错'))
analyzeResult = False
return
(6)之后是主程序,控制个程序的运行,以及分析过程的输出
data_input()
data = dict()
for i in non_ter:
firstVT.setdefault(i, "")
lastVT.setdefault(i, "")
for i in terSymblo:
for j in terSymblo:
addtodict2(data, i, j, '')
#print(data)
sym = non_ter + terSymblo
for n in range(10):
for i in formules:
get_fistVT(i)
get_lastVT(i)
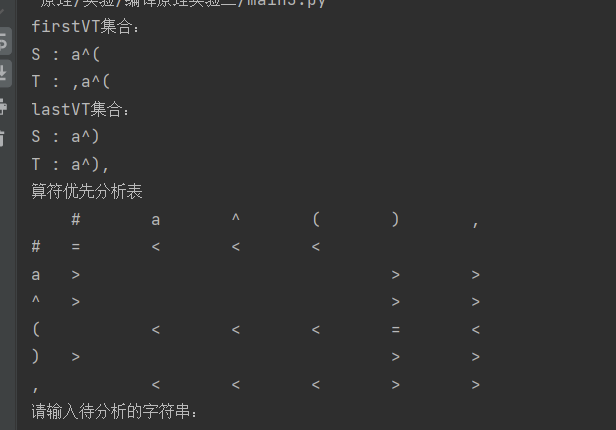
print("firstVT集合:")
for i in non_ter:
print(i+" : "+firstVT[i])
print("lastVT集合:")
for i in non_ter:
print(i+" : "+lastVT[i])
temp2 = Start +" -> #" +Start+"#"
formules.append(temp2)
for i in formules:
analy(i)
print("算符优先分析表")
for i in terSymblo:
print("\t" + i.ljust(4), end="")
print()
for i in terSymblo:
print(i.ljust(4), end="")
for j in terSymblo:
if j in data[i]:
print(data[i][j].ljust(8), end="")
else:
print("\t\t", end="")
print()
sentencePattern = ["N+N", "N*N", "N/N", "(N)", "i","N^N","N,N","a"]
analyzeResult = False
analyzeStep = 0
print("请输入待分析的字符串:")
string = input()
string = string.replace(" ", "")
string+="#"
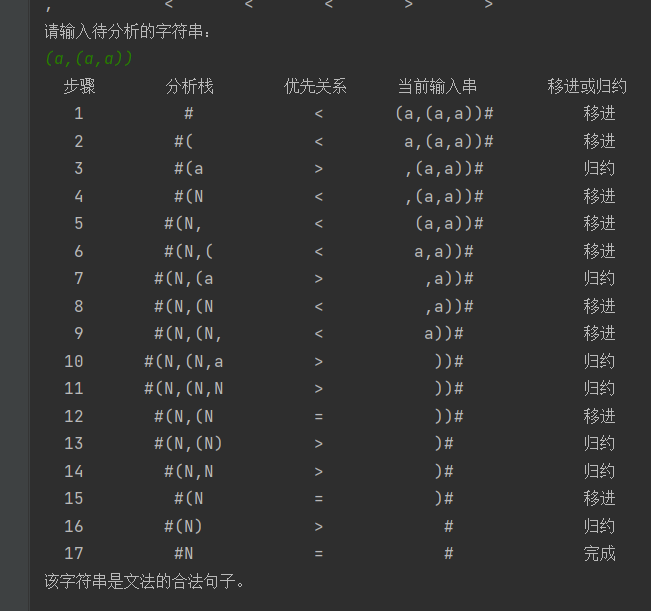
print(" {:^4} {:^13} {:^6} {:^12} {:^10} ".format('步骤', '分析栈', '优先关系', '当前输入串', '移进或归约'))
initStack(string)
if (analyzeResult):
print("该字符串是文法的合法句子。\n")
else:
print("该字符串不是文法的合法句子。\n")
总程序
import re
grammarElement = {
}
terSymblo = ['#']
non_ter = []
Start = 'S'
allSymbol = [] # 所有符号
firstVT = {
} # FIRSTVT集
lastVT = {
} # lastVT集
formules = []
def data_input(): # 读取文法
with open("input2.txt", 'r+', encoding="utf-8") as f:
temp = f.readlines()
for i in temp:
line = str(i.strip("\n"))
formules.append(line)
if line[0] not in non_ter:
non_ter.append(line[0])
grammarElement.setdefault(line[0], line[5:])
else:
grammarElement[line[0]] += "|" + line[5:]
for i in temp:
line = str(i.strip("\n")).replace(" -> ", "")
for j in line:
if j not in non_ter and j not in terSymblo:
terSymblo.append(j)
if 'ε' in terSymblo: terSymblo.remove('ε')
def get_fistVT(formule):
x = formule[0]
ind = non_ter.index(x)
index = []
i = 5
if formule[i] in terSymblo and formule[i] not in firstVT[x]: # 首位为终结符 P->a...
firstVT[x] += formule[i]
elif formule[i] in non_ter: # 首位为非终结符
for f in firstVT[formule[i]]:
if f not in firstVT[x]:
firstVT[x] += f
if i + 1 < len(formule):
if formule[i + 1] in terSymblo and formule[i + 1] not in firstVT[x]: # P->Q..
firstVT[x] += formule[i + 1]
def get_lastVT(formule):
x = formule[0]
i = len(formule) - 1
if formule[i] in terSymblo and formule[i] not in lastVT[x]:
lastVT[x] += formule[i]
elif formule[i] in non_ter:
for f in lastVT[formule[i]]:
if f not in lastVT[x]:
lastVT[x] += f
if formule[i - 1] in terSymblo and formule[i - 1] not in lastVT[x]:
lastVT[x] += formule[i - 1]
def addtodict2(thedict, key_a, key_b, val): # 设置二维字典的函数
if key_a in thedict.keys():
thedict[key_a].update({
key_b: val})
else:
thedict.update({
key_a: {
key_b: val}})
def analy(formule): #算符优先分析表
start = 5
end = len(formule) - 2
if start == end: return
for i in range(start, end):
if formule[i] in terSymblo and formule[i + 1] in terSymblo:
addtodict2(data, formule[i], formule[i + 1], "=")
if formule[i] in terSymblo and formule[i + 1] in non_ter and formule[i + 2] in terSymblo:
addtodict2(data, formule[i], formule[i + 2], "=")
if formule[i] in terSymblo and formule[i + 1] in non_ter:
for j in firstVT[formule[i + 1]]:
addtodict2(data, formule[i], j, "<")
if formule[i] in non_ter and formule[i + 1] in terSymblo:
for j in lastVT[formule[i]]:
addtodict2(data, j, formule[i + 1], ">")
if formule[i + 1] in terSymblo and formule[i + 2] in non_ter:
for j in firstVT[formule[i + 2]]:
addtodict2(data, formule[i + 1], j, "<")
if formule[i + 1] in non_ter and formule[i + 2] in terSymblo:
for j in lastVT[formule[i + 1]]:
addtodict2(data, j, formule[i + 2], ">")
def reverseString(string):
return string[::-1]
# 初始化两个栈
def initStack(string):
# 分析栈,入栈#
analysisStack = "#"
# 当前输入串入栈,即string逆序入栈
currentStack = reverseString(string)
# 调用分析函数
toAnalyze(analysisStack, currentStack)
# 寻找分析栈最顶终结符元素,返回该元素及其下标
def findVTele(string):
ele = '\0'
ele_index = 0
for i in range(len(string)):
if (string[i] in terSymblo):
ele = string[i]
ele_index = i
return ele, ele_index
# 根据栈中内容进行分析
def toAnalyze(analysisStack, currentStack):
global analyzeResult
global analyzeStep
analyzeStep += 1
analysisStack_top, analysisStack_index = findVTele(analysisStack) # 分析栈最顶终结符元素及下标
currentStack_top = currentStack[-1] # 当前输入串栈顶
relation = data[analysisStack_top][currentStack_top]
if relation == '<':
print(" {:^5} {:^15} {:^9} {:^15} {:^12} ".format(analyzeStep, analysisStack, relation,
reverseString(currentStack), '移进'))
analysisStack += currentStack_top
currentStack = currentStack[:-1]
toAnalyze(analysisStack, currentStack)
elif relation == '>':
print(" {:^5} {:^15} {:^9} {:^15} {:^12} ".format(analyzeStep, analysisStack, relation,
reverseString(currentStack), '归约'))
currenChar = analysisStack_top
temp_string = ""
for i in range(len(analysisStack) - 1, -1, -1):
if (analysisStack[i] >= 'A' and analysisStack[i] <= 'Z'):
temp_string = analysisStack[i] + temp_string
continue
elif (data[analysisStack[i]][currenChar] == '<'):
break;
temp_string = analysisStack[i] + temp_string
currenChar = analysisStack[i]
if (temp_string in sentencePattern):
analysisStack = analysisStack[0:i + 1]
analysisStack += 'N'
toAnalyze(analysisStack, currentStack)
else:
print("归约出错!待归约串为:", temp_string, "--->产生式右部无此句型!")
analyzeResult = False
return
elif (relation == '='):
if (analysisStack_top == '#' and currentStack_top == '#'):
print(" {:^5} {:^15} {:^9} {:^15} {:^12} ".format(analyzeStep, analysisStack, relation,
reverseString(currentStack), '完成'))
analyzeResult = True
return
else:
print(" {:^5} {:^15} {:^9} {:^15} {:^12} ".format(analyzeStep, analysisStack, relation,
reverseString(currentStack), '移进'))
analysisStack += currentStack_top
currentStack = currentStack[:-1]
toAnalyze(analysisStack, currentStack)
elif (relation == None):
print(" {:^5} {:^15} {:^9} {:^15} {:^12} ".format(analyzeStep, analysisStack, 'None',
reverseString(currentStack), '报错'))
analyzeResult = False
return
data_input()
data = dict()
for i in non_ter:
firstVT.setdefault(i, "")
lastVT.setdefault(i, "")
for i in terSymblo:
for j in terSymblo:
addtodict2(data, i, j, '')
#print(data)
sym = non_ter + terSymblo
for n in range(10):
for i in formules:
get_fistVT(i)
get_lastVT(i)
print("firstVT集合:")
for i in non_ter:
print(i+" : "+firstVT[i])
print("lastVT集合:")
for i in non_ter:
print(i+" : "+lastVT[i])
temp2 = Start +" -> #" +Start+"#"
formules.append(temp2)
for i in formules:
analy(i)
print("算符优先分析表")
for i in terSymblo:
print("\t" + i.ljust(4), end="")
print()
for i in terSymblo:
print(i.ljust(4), end="")
for j in terSymblo:
if j in data[i]:
print(data[i][j].ljust(8), end="")
else:
print("\t\t", end="")
print()
sentencePattern = ["N+N", "N*N", "N/N", "(N)", "i","N^N","N,N","a"]
analyzeResult = False
analyzeStep = 0
print("请输入待分析的字符串:")
string = input()
string = string.replace(" ", "")
string+="#"
print(" {:^4} {:^13} {:^6} {:^12} {:^10} ".format('步骤', '分析栈', '优先关系', '当前输入串', '移进或归约'))
initStack(string)
if (analyzeResult):
print("该字符串是文法的合法句子。\n")
else:
print("该字符串不是文法的合法句子。\n")
测试
测试文法
S -> a
S -> ^
S -> (T)
T -> T,S
T -> S
完成