一、实验目的
通过预测分析算法的设计与实现,加深对自上而下语法分析方法的理解,尤其是对自上而下分析条件的理解。
二、实验内容
输入文法及待分析的输入串,输出其预测分析过程及结果。
1. 参考数据结构
(1)/定义产生式的语法集结构/
typedef struct{
char formula[200];//产生式
}grammarElement;
grammarElement gramOldSet[200];//原始文法的产生式集
(2)/变量定义/
char terSymbol[200];//终结符号
char non_ter[200];//非终结符号
char allSymbol[400];//所有符号
char firstSET[100][100];//各产生式右部的FIRST集
char followSET[100][100];//各产生式左部的FOLLOW集
int M[200][200];//分析表
2. 判断文法的左递归性,将左递归文法转换成非左递归文法。(该步骤可以省略,直接输入非左递归文法)。


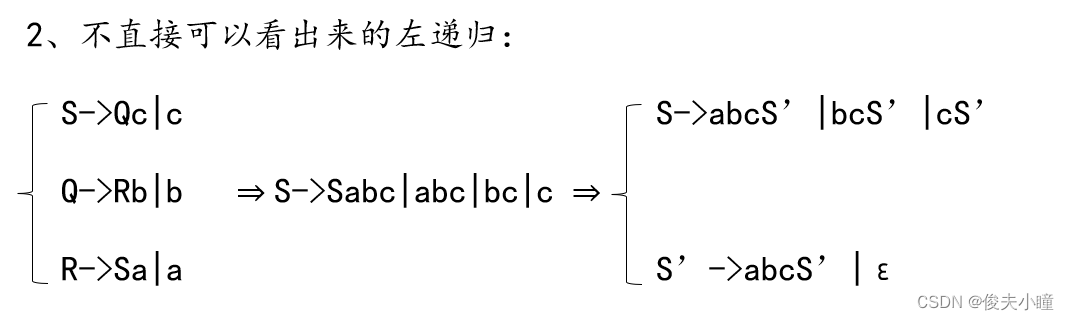
3.根据文法求FIRST集和FOLLOW集。
(1)/求 First 集的算法/
begin
if X为终结符(XÎ )
在所有产生式中查找X所在的产生式
if 产生式右部第一个字符为终结符或空(即X®a(aÎ )或X®e)
then 把a或e加进FIRST(X)
if 产生式右部第一个字符为非终结符 then
if产生式右部的第一个符号等于当前字符 then
跳到下一条产生式进行查找
if 当前非终结符还没有求其FIRST集 then
查找它的FIRST集并标识此符号已求其FIRST集
求得结果并入到X的FIRST集
if 当前产生式右部符号可推出空字且当前字符不是右部的最后一个字符
then 获取右部符号下一个字符在所有字符集中的位置
if 此字符的FIRST集还未查找 then
找其FIRST集,并标其查找状态为1
把求得的FIRST集并入到X的FIRST集
if 当前右部符号串可推出空且是右部符号串的最后一个字符(即产生式为X® ,若对一切1£ i£ k,均有e ÎFIRST( ),则将eÎ符号加进FIRST(X)) then 把空字加入到当前字符X的FIRST集
else
不能推出空字则结束循环
标识当前字符X已查找其FIRST集。
end
(2)/求 FOLLOW 集的算法/
begin
if X为开始符号 then # ÞFOLLOW(X)
对全部的产生式找一个右部含有当前字符X的产生式
if X在产生式右部的最后(形如产生式A®aX) then
查找非终结符A是否已经求过其FOLLOW集.避免循环递归
if 非终结符A已经求过其FOLLOW集 then
把FOLLOW(A)中的元素加入FOLLOW(X)
继续查下一条产生式是否含有X
else
求A的FOLLOW集,并标记为A已求其FOLLOW集
else if X不在产生式右部的最后(A®aBb) then
if 右部X后面的符号串b能推出空字e then
查找b是否已求过其FOLLOW集.避免循环递归
if 已求过b的FOLLOW集 then
把FOLLOW(A)中的元素加入FOLLOW(B)
结束本次循环
else if b不能推出空字 then
求 FIRST(b)
把FIRST(b)中所有非空元素加入到FOLLOW(B)中
标识当前要求的非终结符X的FOLLOW集已求过
end
4.构造预测分析表。

5.构造总控程序。
6.对给定的输入串,给出分析过程及结果。
三、实验报告
1.实验步骤
输入文法及待分析的输入串,输出其预测分析过程及结果。
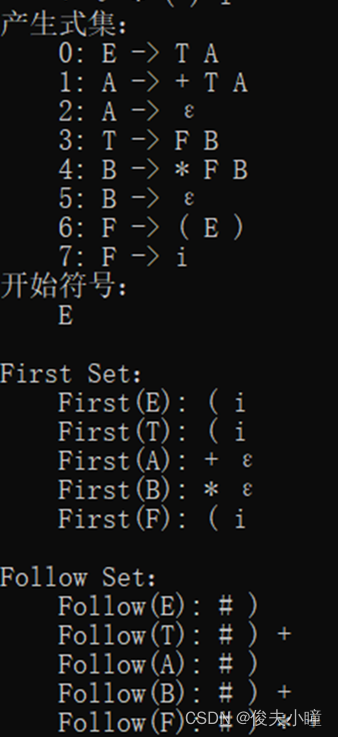
1.根据文法求FIRST集和FOLLOW集。

第4条的意思是:
如果一个产生式的右边是一串非终结符,只要前i-1个非终结符的FIRST集里有ε,那么就可以直接不看他们把他们划掉就行,相当于第i个非终结符就变成了第一个非终结符,这就变成了第3条的情况;
如果这一串非终结符的FIRST集里都有ε,那么就都可以全部不看全部划掉,就相当于右边啥也没有,这就变成了第二条的情况。

β是一串终结符和非终结符的有限序列。
如果这个序列的第一个字符为终结符,比如a,那么FIRST(β)=FIRST(a)=a;
如果这个序列的第一个字符为非终结符,比如A,那么FIRST(β)=FIRST(A)。
举个例子:
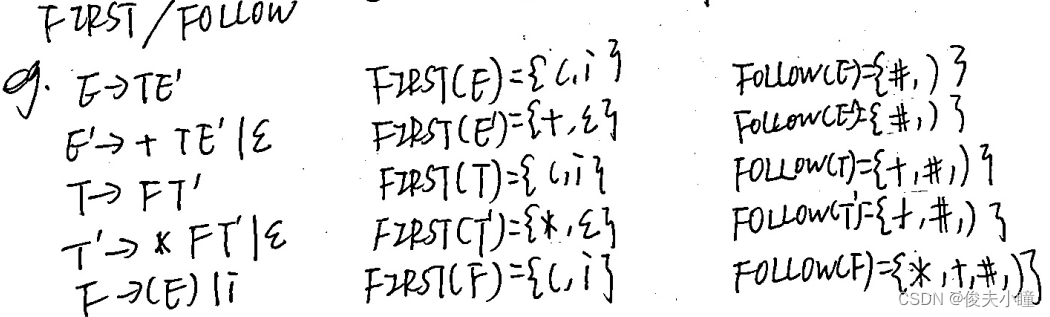
2.构造预测分析表。
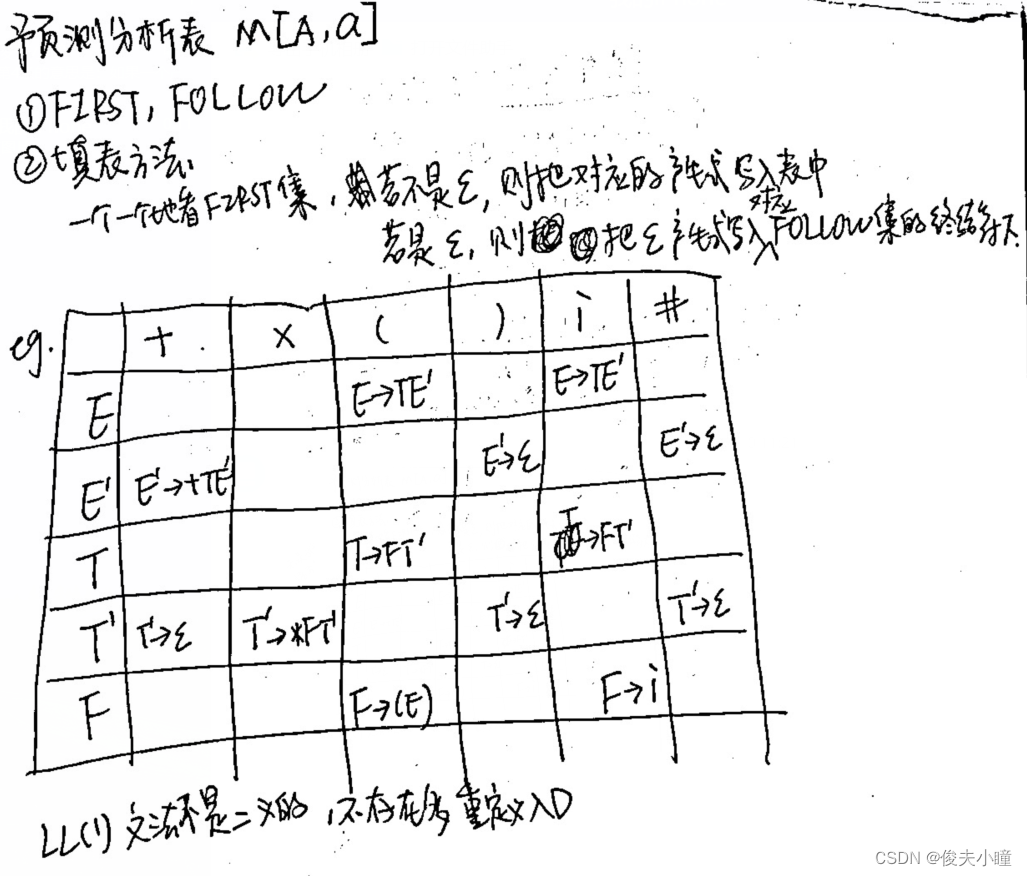
3.对给定的输入串,给出分析过程及结果。

上面是我以前写的笔记,我就不详细讲了,因为我也忘了,具体见代码运行结果吧。
2.源代码及运行结果
1、源代码
#include<iostream>
#include<iomanip>
#include<vector>
#include<set>
#include<stack>
using namespace std;
class WF{
public:
string *VN; //非终结符集
string *VT; //终结符集
string *P; //产生式集
string S; //开始符号
string Token; //待分析串
string *head; //存储产生式->的左半部分
vector<string> *tail;//存储产生式->的右半部分
set<string> *first; //用以存储First集
set<string> *follow;//用以存储Follow集
int length[3]; //记录VN,VT,P的长度
set<string>::iterator tt;//用作iterator读取set集合内容
int **M;//二维数组,可以用存储预测分析表的内容,
//某位置没有产生式标记为-1,否则标记为产生式的序列号
void init(){
//init函数用于初始化
char ch;
string token;
cin>>length[0]; //获得非终结符符集数目
M=new int *[length[0]];
VN=new string[length[0]];
head=new string[length[2]];
tail=new vector<string>[length[2]];
first=new set<string>[length[0]];
follow=new set<string>[length[0]];
for(int i=0;i<length[0];i++)
cin>>VN[i];
cin>>length[1]; //获得终结符符集数目
for(int i=0;i<length[0];i++)
M[i]=new int[length[1]+1];
VT=new string[length[1]+1];
for(int i=0;i<length[1];i++)
cin>> VT[i];
VT[length[1]]="ε";
cin>>length[2]; //获得产生式集数目
P=new string[length[2]];
getline(cin,P[0]); //跳转到下一行
for(int i=0;i<length[2];i++){
getline(cin,P[i]);
head[i]=P[i].substr(0,P[i].find(" "));
for(int j=P[i].find(" ")+4;j<P[i].size();j++){
if(P[i][j]==' '){
tail[i].push_back(token);
token.clear();
continue;
}
else{
token+=P[i][j];
}
}
if(!token.empty())
tail[i].push_back(token);
token.clear();
}
cin>>S; //获得开始符号
cin>>Token; //获得待分析串
}
void getFirstSet(){
//求解其Frist集
int k,l;
int firstSetLength[length[0]];
bool flag=true;
for(int i=0;i<length[0];i++){
for(int j=0;j<length[2];j++){
if(!VN[i].compare(head[j])){
if(isVT(tail[j][0])){
//cout<<tail[j][0]<<endl;
first[i].insert(tail[j][0]);
}
}
}
}
for(int i=0;i<length[0];i++){
firstSetLength[i]=first[i].size();
}
//保存初始长度
do{
flag=false;
for(int i=0;i<length[0];i++){
//遍历VN
for(int j=0;j<length[2];j++){
//遍历产生式
if(!VN[i].compare(head[j])){
//遇到VN对应产生式
k=0,l=0;
while(k<tail[j].size()&&!isVT(tail[j][k])){
for(int loc=0;loc<length[0];loc++)
if(!tail[j][k].compare(VN[loc])){
for(tt=first[loc].begin();tt!=first[loc].end();tt++)
//添加LOC所定位的非终结符对应的First集\ε
if(!(*tt).compare("ε"))
k++;
else
first[i].insert(*tt);
break;
}
if(k>l) l=k;//当前VN的的first集含有ε,继续添加下一个
else break;
}
if(k==tail[j].size()) first[i].insert("ε");
//对于所有Yi都含有ε的,添加ε到first集
else if(isVT(tail[j][k])){
//添加可以推导出ε部分临近的终结符
first[i].insert(tail[j][k]);
}
}
}
}
for(int i=0;i<length[0];i++){
if(firstSetLength[i]!=first[i].size()){
firstSetLength[i]=first[i].size();
flag=true;
}
}
}while(flag);//保证各个Frist集不再发生变化
}
void getFollowSet(){
//求解其Follow集
set<string> temp;
int l,h;
int followSetLength[length[0]];
bool flag;
for(int i=0;i<length[0];i++)
if(!VN[i].compare(S)){
follow[i].insert("#");
break;
}
for(int i=0;i<length[0];i++){
followSetLength[i]=follow[i].size();
}
//保存每个Follow集的长度
do{
flag=false;
for(int i=0;i<length[0];i++)
for(int j=0;j<length[2];j++)
for(int k=0;k<tail[j].size();k++){
temp.clear();
if(!isVT(tail[j][k])){
if((k+1)==tail[j].size()){
int loc=locVN(head[j]);
for(tt=follow[loc].begin();tt!=follow[loc].end();tt++){
temp.insert(*tt);
}
}else if(isVT(tail[j][k+1])){
temp.insert(tail[j][k+1]);
}else {
l=k+1;
h=k+1;
while(h<tail[j].size()&&!isVT(tail[j][h])){
int loc=locVN(tail[j][l]);
for(tt=first[loc].begin();tt!=first[loc].end();tt++){
if(!(*tt).compare("ε"))
h++;
else{
temp.insert(*tt);
}
}
if(h>l) l=h;
else break;
}
if(h==tail[j].size()) {
int loc=locVN(head[j]);
for(tt=follow[loc].begin();tt!=follow[loc].end();tt++)
temp.insert(*tt);
}else if(isVT(tail[j][h])){
temp.insert(tail[j][h]);
}
}
}
for(tt=temp.begin();tt!=temp.end();tt++){
follow[locVN(tail[j][k])].insert(*tt);
}
}
for(int i=0;i<length[0];i++)
if(followSetLength[i]!=follow[i].size()){
followSetLength[i]=follow[i].size();
flag=true;
}
}while(flag);//当Follow集长度不在发生变化时,求解完毕,跳出该循环
}
void printPredictionAnalysisTable(){
//对M初始化并输出预测分析表
set<string> temp[length[2]];
int i,j;
bool flag;
for(i=0;i<length[0];i++)
for(j=0;j<=length[1];j++)
M[i][j]=-1;//为预测分析表中的状态进行初始化,-1代表
for(i=0;i<length[2];i++){
flag=false;
for(j=0;j<tail[i].size();j++){
if(isVT(tail[i][j])){
temp[i].insert(tail[i][j]);
break;
}else{
int loc=locVN(tail[i][j]);
for(tt=first[loc].begin();tt!=first[loc].end();tt++)
if((*tt).compare("ε"))
temp[i].insert(*tt);
else
flag=true;//表明当前添加的First集中含有ε,可以继续向下进行
}
if(!flag) break;
}
if(j==tail[i].size())
temp[i].insert("ε");
}
for(i=0;i<length[0];i++)
for(j=0;j<length[1];j++)
for(int loc=0;loc<length[2];loc++)
if(!head[loc].compare(VN[i])&&temp[loc].count(VT[j]))
M[i][j]=loc;
for(int loc=0;loc<length[2];loc++)
if(temp[loc].count("ε")){
int k=locVN(head[loc]);//获得VN下标
for(tt=follow[k].begin();tt!=follow[k].end();tt++){
if(!(*tt).compare("#"))
M[k][length[1]]=loc;
else for(j=0;j<length[1];j++)
if(!VT[j].compare(*tt)){
M[k][j]=loc;
break;
}
}
}
cout<<"预测分析表:\n"<<setw(8)<<left<<" ";
for(i=0;i<length[1];i++)
cout<<setw(6)<<left<<VT[i];
cout<<"#\n";
cout<<"-----+";
for(i=0;i<=length[1];i++)
cout<<"-----+";
for(i=0;i<length[0];i++){
cout<<"\n"<<setw(8)<<left<<VN[i];
for(j=0;j<=length[1];j++){
if(M[i][j]!=-1)
cout<<"P"<<setw(5)<<left<<M[i][j];
else
cout<<setw(6)<<left<<" ";
}
}
cout<<"\n-----+";
for(i=0;i<=length[1];i++)
cout<<"-----+";
}
void analyse(string token){
//分析读取的待分析串
stack<string> LL;
vector<string> temp;
string X;
string a;
int i=0;
int step=1;
int loc;
bool flag=true;
LL.push("#");
LL.push(S);//#和开始符号均入栈
token+='#';
cout<<"\n\n"<<token<<"分析过程:\n";
cout<<"\n初始化:#入栈,"<<S<<"入栈;";
a.clear();
a+=token[i];
while(flag){
X=LL.top();
LL.pop();
cout<<"\n"<<setfill('0')<<setw(3)<<right<<step<<":出栈X="<<X<<",输入c="<<a<<",";
if(isVT(X)){
if(!X.compare(a)){
step++;
cout<<"匹配,输入指针后移;\n";
a.clear();
a+=token[++i];
}else{
cout<<"ERROR!!"<<endl;
break;
}
}else if(!X.compare("#")){
if(!X.compare(a)){
flag=false;//完成
cout<<"匹配,成功。"<<endl;
break;
}else{
cout<<"ERROR!!"<<endl;
break;
}
}else if((loc=M[locVN(X)][locVT(a)])!=-1){
step++;
cout<<"查表,M[X,c]="<<X<<"->";
for(int j=0;j<tail[loc].size();j++){
cout<<tail[loc][j];
}
cout<<",产生式右部逆序入栈(ε不入栈);\n";
for(int j=tail[loc].size();j;j--)
if(tail[loc][j-1].compare("ε"))
LL.push(tail[loc][j-1]);
}else{
cout<<"ERROR!!"<<endl;
break;
}
}
}
bool isVT(string str){
//判断是否为VT,若是则返回true,否则返回false
for(int i=0;i<length[1]+1;i++)
if(!str.compare(VT[i]))
return true;
return false;
}
int locVN(string str){
//返回VN的位置序号
for(int i=0;i<length[0];i++)
if(!str.compare(VN[i]))
return i;
return -1;
}
int locVT(string str){
//返回VT的列位置序号,对于符号#返回其为最后一列的序号
for(int i=0;i<length[1];i++)
if(!str.compare(VT[i]))
return i;
if(!str.compare("#"))
return length[1];
return -1;
}
};
int main(){
//实验6程序,输入文件请采用ANSI编码格式,否则无法正常读取!!!!!!
WF G;
G.init();
//文法初始化
G.getFirstSet();
//获得First集
G.getFollowSet();
//获得Follow集
G.printPredictionAnalysisTable();
//构建并输出预测分析表
G.analyse(G.Token);
//输出对G.Token的分析
system("pause");
return 0;
}
2、运行结果
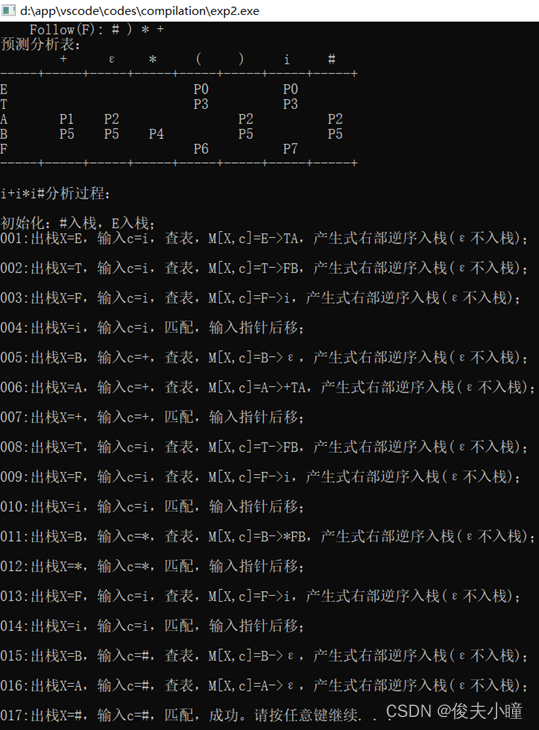
下面的运行结果是我以前写报告的时候截的,大家应该可以看懂吧,先输有几个非终结符,再输非终结符,再输有几个终结符,再输终结符,然后输文法,注意我的文法输入形式,是一小条一小条的,不要合并,最后还要输开始符号是哪个。
其他的我也忘了,大家自己探索代码吧,如果有编译错误的地方,自己也不知道怎么改的话,可以先不要管,直接运行试试,应该是可以运行的,如果实在不行,那就放弃我这篇吧,因为我真的忘了。
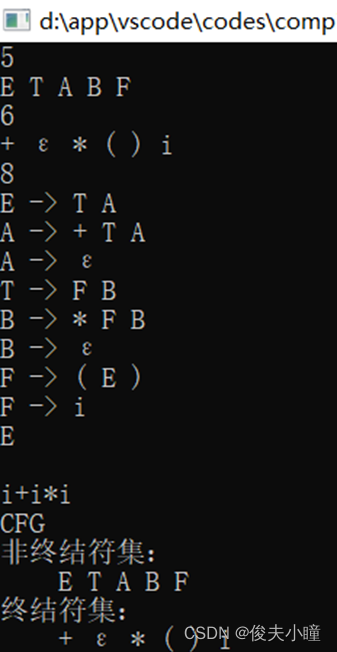
3.实验时发现的问题及解决过程
实验存在一定的不足,与实验要求存在差别,首先栈顶元素输出的时候,没有输出T‘,取而带之的是小写的t,这里主要区别是前者是两个字符,后者是一个字符,相比易两个字符,一个字符在进行字符读取时更好处理,比如说在倒序入栈时,两个字符由于可以分割,进入栈中时就变成了’T,这样就导致了程序混乱。还有不同的地方当前单词记号实验要求输出的时id,而我输出的时i,这里也是遇到了逆序入栈的问题,多于一个字符串,就会导致入栈出错,这里我想到了解决办法,这就需要于词法分析器联合使用,词法分析器将单词分析出来,然后再进行处理。再然后就是动作动作中由于id是两个字符,所以在进行处理时,识别了i,但是在识别d是,发现终结符中不存在该字符,导致程序出错,识别不出,跳过。这个问题的解决方式也和上一个是一样的,利用词法分析,将语句进行词法分析。再进行处理,就不会出错了。实验算是完成了,但是还有许多不足。