上篇根据自己实际工作内容,写了一个简单的程序,用于读取csv文件,简单处理后输出到excel文件。接下来想更多更深入地使用pandas进行数据分析,其实最缺的是各种各样的数据集。搜索的过程中,搜到了飞浆的数据分析相关练习题,里面也提供了大量的数据集。参考飞浆这十套练习,教你如何使用Pandas做数据分析 - 飞桨AI Studio,实际操作一下。操作的过程中,其实还是会遇到一些问题,也在这里做一些整理。
目录
一、读取数据
import pandas as pd
path1 = "exercise_data/chipotle.tsv"
data = pd.read_csv(path1)
print(data.head(10))万事开头难,在读取数据这里就出现问题了,报错:

这意思是说:在第6行期望1个fields,但是发现有5个,我们看下数据集的第六行:
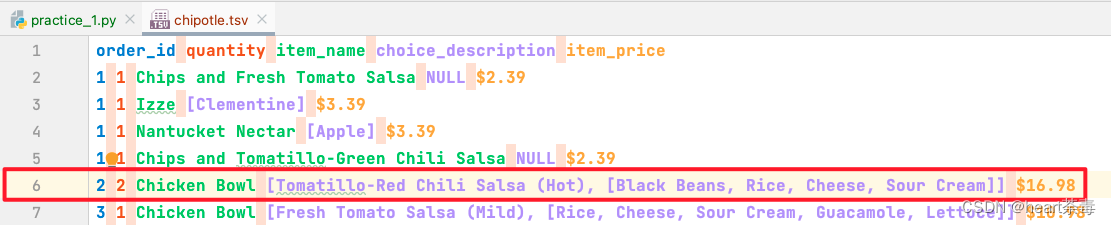
也没看到有啥,就看到这一行有点长,然后多了些",",感觉是这里的问题。因为我看飞浆是使用制表符分割,read_csv默认使用","分割。解决方式有三种:
1、打开tsv文件,导出为标准的csv文件
path1 = "exercise_data/chipotle.csv"2、使用文件中不存在的符号进行分割
data = pd.read_csv(path1, sep="\t")3、跳过解析报错的行(如果有大量的数据出现问题,不建议跳过)
data = pd.read_csv(path1, on_bad_lines='skip')建议使用第一种,完整代码修改后如下:
import pandas as pd
path1 = "exercise_data/chipotle.csv"
data = pd.read_csv(path1)
print(data.head(10))
二、设置显示长度
显示出来了,但是显示...,这是因为数据太长,而pandas显示长度不够,可以设置一下:
# 设置显示的最大列、宽等参数,消掉打印不完全中间的省略号
pd.set_option('display.width', 1000)
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)设置后,显示如下:

三、显示行列数、列名称和索引
# 打印行和列数量
print('行:' + str(data.shape[0]) + '; ' + '列:' + str(data.shape[1]))
# 打印出全部的列名称
print(data.columns)
# 打印数据集的索引
print(data.index)
四、统计次数
对quantity累加后按照item_name分组,然后从大到小排序:
c = data[['item_name', 'quantity']].groupby(['item_name'], as_index=False).agg({'quantity': sum})
c1 = c.sort_values(['quantity'], ascending=False)
print(c1.head())
sort_values方法的参数说明如下:
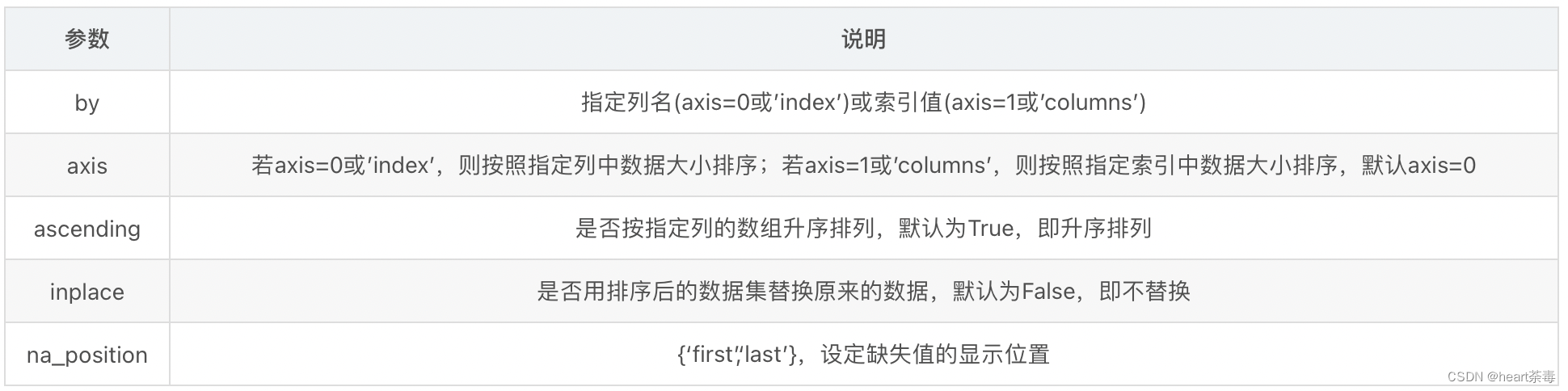
五、去重
# 打印去重后item_name列的数量
print(data['item_name'].nunique())六、求和
# quantity求和
print(data['quantity'].sum())七、复杂计算
# 将item_price转换为浮点数
dollarizer = lambda x: float(x[1:-1])
data['item_price'] = data['item_price'].apply(dollarizer)
print(data.head())
# 计算收入,保留整数
data['sub_total'] = round(data['item_price'] * data['quantity'])
print(data['sub_total'].sum())
# 订单数量
print(data['order_id'].nunique())
# 计算每单平均价格
c2 = data[['order_id', 'sub_total']].groupby(by=['order_id']
).agg({'sub_total': 'sum'})['sub_total'].mean()
print(round(c2)) 
八、完整代码
import pandas as pd
# 设置显示的最大列、宽等参数,消掉打印不完全中间的省略号
pd.set_option('display.width', 1000)
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 读取csv文件
path1 = "exercise_data/chipotle.csv"
data = pd.read_csv(path1)
# 打印前五条
print(data.head())
# 打印行和列数量
print('行:' + str(data.shape[0]) + '; ' + '列:' + str(data.shape[1]))
# 打印出全部的列名称
print(data.columns)
# 打印数据集的索引
print(data.index)
# 按照quantity求和并且按照item_name分组
c = data[['item_name', 'quantity']].groupby(['item_name'], as_index=False).agg({'quantity': sum})
# 按照quantity从大到小排序
c1 = c.sort_values(['quantity'], ascending=False)
print(c1.head())
# 打印去重后item_name列的数量
print(data['item_name'].nunique())
# quantity求和
print(data['quantity'].sum())
# 将item_price转换为浮点数
dollarizer = lambda x: float(x[1:-1])
data['item_price'] = data['item_price'].apply(dollarizer)
print(data.head())
# 计算收入,保留整数
data['sub_total'] = round(data['item_price'] * data['quantity'])
print(data['sub_total'].sum())
# 订单数量
print(data['order_id'].nunique())
# 计算每单平均价格
c2 = data[['order_id', 'sub_total']].groupby(by=['order_id']
).agg({'sub_total': 'sum'})['sub_total'].mean()
print(round(c2))
本篇是我们第一次跟着飞桨的练习题去做数据分析。搞了这么多年开发,自己也经常遇到这种情况:跟着一些网站的练习题或者视频书籍等,总会遇到一些坑。本篇跟着飞桨的练习题去做,一个是使用其练习题和数据集,再一个就是帮助大家避坑,希望可以帮助到大家。