写在前面
Distributed Prioritized Experience Replay (DPER)是一种增强学习中的经验回放方法,用于训练深度强化学习网络。在深度强化学习中,通常使用经验回放来存储和重复使用智能体与环境的交互经验。经验回放的基本思想是将智能体的经验存储在一个经验回放缓冲区中,然后从中随机抽样一批经验用于训练智能体的神经网络。这种方法具有两个主要优点:一是可以更好地利用数据,避免训练过程中的相关性问题;二是可以提高数据的利用效率,因为智能体可以多次重复使用之前的经验。然而,传统的经验回放方法并没有考虑到经验的重要性,而是简单地进行随机抽样。这可能导致一些重要的经验被频繁地选择,而其他的经验则很少被选中,从而影响学习的效果。
DPER引入了优先级经验回放的概念,它根据经验的优先级来决定选择的概率。优先级可以根据经验的TD误差(Temporal Difference error)或其他衡量重要性的指标来计算。具有较高优先级的经验将更有可能被选中进行训练,从而使得智能体能够更加聚焦于重要的经验。此外,DPER还引入了分布式经验回放的概念,将经验回放的计算任务分布到多个计算节点上进行并行处理。这种分布式的方法可以加速经验回放的过程,提高学习效率。
综上所述,Distributed Prioritized Experience Replay结合了优先级经验回放和分布式计算的优势,可以提高深度强化学习中智能体的学习效率和性能。它在许多强化学习任务中都取得了很好的效果,并成为当前深度强化学习领域的一种常用方法。
论文译读
DISTRIBUTED PRIORITIZED EXPERIENCE REPLAY
摘要
我们提出了一种分布式深度强化学习的架构,该架构使得Agent能够有效地从比以前可能的数量级更多的数据中学习。该算法将Acting与学习分离:Actor根据共享神经网络选择动作,并与他们自己的环境实例进行互动,将产生的经验累积在共享的经验重放记忆中;Learner重放经验样本并更新神经网络。这个架构依赖于优先经验重放,只关注由Actor生成的最重要的数据。我们的架构在Arcade学习环境上大大改善了SOTA技术的表现,实现了更好的最终性能,并且使用了更少的实际训练时间。
1 引入
深度学习的一个广泛趋势是,更多的计算(Dean等,2012)与更强大的模型(Kaiser等,2017)和更大的数据集(Deng等,2009)可以产生更令人印象深刻的结果。我们有理由期望对深度强化学习也有类似的原则。有越来越多的例子证明这种乐观的态度:有效使用更大的计算资源是Gorila (Nair等,2015)、A3C (Mnih等,2016)、GPU优势Actor批评 (Babaeizadeh等,2017)、分布式PPO (Heess等,2017)和AlphaGo (Silver等,2016)等算法成功的关键因素。像TensorFlow (Abadi等,2016)这样的深度学习框架支持分布式训练,使得大规模机器学习系统更易于实现和部署。尽管如此,深度强化学习当前的大部分研究仍在关注如何在单机的计算预算内提高性能,而如何更好地利用更多资源的问题相对较少被探索。在本文中,我们描述了一种通过生成更多数据并以优先方式选择它来扩大深度强化学习的方法 (Schaul等,2016)。对于神经网络的分布式训练的标准方法是关注并行计算梯度,以更快地优化参数 (Dean等,2012)。相反,我们分布生成和选择经验数据,并发现这种方法本身就足以改善结果。这与分布式梯度计算是互补的,这两种方法可以结合使用,但在这项工作中,我们仅关注数据生成。我们使用这种分布式架构来扩大深度Q网络(DQN)和深度确定性策略梯度(DDPG)的变种,并在Arcade学习环境基准(Bellemare等,2013)以及一系列连续控制任务上对这些进行评估。我们的架构在Atari游戏上取得了新的最新水平的性能,与上一个最新水平相比,只使用了一小部分的实际时间,而且没有进行每个游戏的超参数调优。我们通过实验研究了我们的框架的可扩展性,分析了随着我们增加数据生成Worker数量,优先级如何影响性能。我们的实验包括对Replay能力、经验的最近性以及不同Worker使用不同的数据生成策略等因素的分析。最后,我们讨论了可能适用于我们的分布式框架之外的深度强化学习Agent的一些潜在意义。
2 背景
Distributed Stochastic Gradient Descent 分布式随机梯度下降
分布式随机梯度下降在监督学习中被广泛用于加速深度神经网络的训练,通过并行计算梯度来更新它们的参数。得到的参数更新可以同步(Krizhevsky,2014)或异步(Dean等,2012)地应用。这两种方法都已经被证明是有效的,并且已经成为深度学习工具箱的一个日益标准的部分。受此启发,Nair等(2015)应用了分布式异步参数更新和分布式数据生成到深度强化学习中。异步参数更新和并行数据生成也已经在单机内成功地应用,以多线程而不是分布式的环境中(Mnih等,2016)。GPU异步Actor-评论者(GA3C;Babaeizadeh等,2017)和并行优势Actor-评论者(PAAC;Clemente等,2017)调整这种方法以高效利用GPU。
Distributed Importance Sampling 分布式重要性抽样
一类用于加速训练的互补技术基于重要性抽样(Hastings,1970)以减小方差。这在神经网络的背景下已被证明是有用的(Hinton,2007)。通过从数据集中非均匀地进行抽样,并根据抽样概率对更新进行加权,以抵消引入的偏差,可以通过减小梯度的方差来增加收敛速度。一种方法是根据相应梯度的L2范数选择样本。在监督学习中,这种方法已成功地扩展到分布式环境(Alain等,2015)。另一种方法是根据最新已知的损失值对样本进行排序,并使抽样概率成为排名的函数,而不是损失函数本身(Loshchilov&Hutter,2015)。
Prioritized Experience Replay 有优先级的经验回放
经验回放(Lin,1992)长期以来一直被用于强化学习以提高数据效率。当使用随机梯度下降算法训练神经网络函数逼近器时,它尤其有用,例如在神经拟合Q-迭代(Riedmiller,2005)和深度Q学习(Mnih等,2015)中。经验回放还可以通过允许Agent学习先前策略生成的数据来帮助防止过拟合。优先经验回放(Schaul等,2016)将经典的优先扫描思想(Moore&Atkeson,1993)扩展到与深度神经网络函数逼近器一起工作。这种方法与前一节讨论的重要性抽样技术密切相关,但使用了一类更一般的有偏采样过程,将学习集中在最“令人惊讶”的经验上。在强化学习中,有偏采样尤其有助于处理奖励信号稀疏且数据分布取决于Agent策略的情况。因此,优先经验回放被许多Agent所使用,例如优先Dueling DQN(Wang等,2016),UNREAL(Jaderberg等,2017),DQfD(Hester等,2017)和Rainbow(Hessel等,2017)。在一项用于研究几个算法组成部分相对重要性的消融研究中(Hessel等,2017),发现优先级设置是对Agent性能最重要的因素之一。
3 DISTRIBUTED PRIORITIZED EXPERIENCE REPLAY 分布式有优先级的经验回放
在这篇文章中,我们将优先经验Replay扩展到了分布式环境,并表明这是一种高度可扩展的深度强化学习方法。我们引入了几个关键的修改,使得这种扩展性成为可能,我们将我们的方法称为Ape-X。
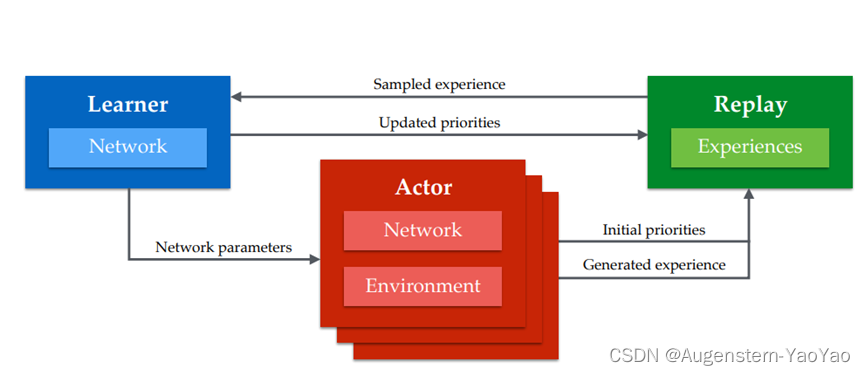
图1:Ape-X架构简述:多个Actor,每个Actor都有自己的环境实例,生成经验并将其添加到共享的经验回放内存中,并计算数据的初始优先级。(单个)学习者从该内存中进行采样,并更新网络和内存中经验的优先级。演员的网络定期使用学习者的最新网络参数进行更新。


与Gorila (Nair等,2015)一样,我们将标准的深度强化学习算法分解为两个部分,这两个部分并发运行,没有高级同步。第一部分包括通过环境步进,评估作为深度神经网络实现的策略,并将观察到的数据存储在Replay记忆中。我们将此称为Acting。第二部分包括从记忆中抽取数据批次来更新策略参数。我们将此称为学习。原则上,Acting和学习都可以在多个Worker中分发。在我们的实验中,数百个在CPU上运行的Actor生成数据,一个在GPU上运行的Learner采样最有用的经验(图1)。Actor和Learner的伪代码显示在算法1和2中。更新的网络参数定期从Learner传递给Actor。
与Nair等(2015)相比,我们使用共享的、集中的Replay记忆,并且我们优先采样,而不是均匀采样,以更频繁地抽取最有用的数据。由于优先级是共享的,任何Actor发现的高优先级数据都可以使整个系统受益。优先级可以用各种方式定义,具体取决于学习算法;接下来的部分描述了两个实例。在优先DQN中(Schaul等,2016),新转换的优先级被初始化为迄今为止看到的最大优先级,并且只有在它们被抽样时才被更新。这种方式的扩展性不好:由于我们的架构中的Actor数量众多,等待Learner更新优先级将导致对最近的数据有近视的关注,因为这些数据本身就具有最大的优先级。相反,我们利用Ape-X中的Actor已经在做的计算,来评估他们本地策略的副本,让他们也在线计算新转换的适当优先级。这确保了进入Replay的数据具有更准确的优先级,而不需要额外的成本。与共享梯度相比,共享经验有一些优点。低延迟通信在分布式SGD中并不像在分布式SGD中那样重要,因为经验数据过时的速度不如梯度快,只要学习算法对离策略数据具有鲁棒性。在系统的整个过程中,我们通过批量所有与集中Replay的通信来利用这一点,从而提高效率和吞吐量,尽管会增加一些延迟。使用这种方法,即使Actor和Learner在不同的数据中心运行,也不会限制性能。最后,通过离策略学习(参见Sutton & Barto,1998;2017),我们可以进一步利用Ape-X的能力,将来自许多分布式Actor的数据进行组合,通过给不同的Actor分配不同的探索策略,增加他们共同遇到的经验的多样性。如我们将在结果中看到,这可以足以在困难的探索问题上取得进展。
3.1 APE-X DQN
我们所描述的一般框架可以与不同的学习算法结合。首先,我们将其与DQN (Mnih等,2015)的变体结合,该变体包含了Rainbow (Hessel等,2017)的一些组件。更具体地说,我们使用双重Q学习 (van Hasselt, 2010; van Hasselt等,2016) 和多步自举目标(参见Sutton, 1988; Sutton & Barto, 1998; 2017; Mnih等,2016)作为学习算法,以及决策网络架构 (Wang等,2016) 作为函数逼近器

这导致计算批次中所有元素的失

其中

这里t是一个时间索引,用于从以状态St和动作At开始的Replay中抽样的经验,θ−表示目标网络的参数(Mnih等,2015),这是在线参数的慢速复制。如果在少于n步内结束了episode,则多步返回被截断。原则上,Q学习变体是离策略方法,所以我们可以自由选择我们用来生成数据的策略。然而,在实践中,行为策略的选择确实会影响探索和函数逼近的质量。此外,我们使用的是多步返回,没有离策略纠正,这在理论上可能会对价值估计产生不利影响。然而,在Ape-X DQN中,每个Actor执行不同的策略,这使得经验可以从各种策略中产生,依赖于优先级机制来挑选出最有效的经验。在我们的实验中,Actor使用了不同ε值的ε-greedy策略。低ε策略允许在环境中更深入地探索,而高ε策略防止过度专化。
3.2 APE-X DPG
为了测试框架的通用性,我们也将其与基于DDPG (Lillicrap等,2016)的连续动作策略梯度系统相结合,这是确定性策略梯度Silver等(2014)的一种实现,也类似于较旧的方法(Werbos,1990; Prokhorov & Wunsch,1997),并在DeepMind控制套件(Tassa等,2018)的连续控制任务上进行了测试。

图2: 左图:汇总了57款Atari游戏的结果,从随机无操作开始评估。右图:选定游戏的Atari训练曲线,与基线对比。蓝色:360个执行者的Ape-X DQN;橙色:A3C;紫色:Rainbow;绿色:DQN。详见附录,其中包含所有游戏的长期运行结果。
Ape-X DPG的设置类似于Ape-X DQN,但是Actor的策略现在由一个单独的策略网络显式表示,除了Q网络。这两个网络通过最小化采样经验上的不同损失而单独优化。我们用φ和ψ分别表示策略和Q网络的参数,并采用同样的约定表示目标网络。Q网络输出给定状态s和多维动作的动作价值估计q(s, a, ψ)。它使用多步引导目标进行时序差分学习进行更新。Q网络的损失可以写为
![]() ,
,
其中,

策略网络输出一个动作:
![]()
策略参数是通过策略梯度上升在估计的Q值上更新的,使用梯度:
![]()
——注意这依赖于策略参数φ只通过动作输入到评估网络。
Ape-X DPG算法的更多细节在附录中提供(附录没有翻译)。
4 实验
4.1 ATARI 游戏任务
在我们的第一组实验中,我们在ATARI评估了Ape-X DQN,并在这个标准的强化学习基准上展示了最新的结果。我们使用360台Actor机器(每台使用一个CPU核心)以它们可以生成的最快速度将数据输入到Replay内存中;大约每个139帧每秒(FPS),总共约50K FPS,这相当于约12.5K次转换(因为固定的动作重复4次)。Actor在将其发送到Replay之前在本地批处理经验数据:一次最多可缓冲100个转换,然后异步批处理发送B=50个。Learner异步预取最多16批512次转换,并计算每秒19个这样的批处理的更新,这意味着梯度平均每秒计算约9.7K次转换。为了减少内存和带宽需求,观察数据在发送和存储在Replay时使用PNG编解码器压缩。Learner在预取数据的同时,同时计算并应用梯度。Learner也异步处理来自Actor的任何参数请求。
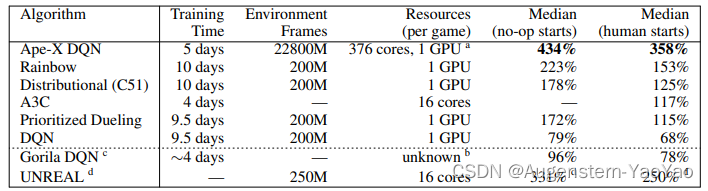
表 1:57款Atari游戏的中位数归一化分数。注:a)Tesla P100。b)使用了多于100个CPU,每台CPU机器的核心数不等。c)仅在49款游戏上进行评估。d)每款游戏的超参数都进行了调整。
Actor每400帧(大约2.8秒)从Learner那里复制网络参数。每个Actor
![]()
执行一个εi-greedy策略,其中:
![]()
每个i在训练过程中保持恒定。在训练期间,episode长度限制为50000帧。共享经验Replay内存的容量软限制为200万个转换:总是允许添加新数据,以不减慢Actor,但每100个学习步骤,超过这个容量阈值的任何超额数据都被批量删除,按照FIFO顺序。内存的实际中位数大小为2035050。数据按照比例优先级进行采样,优先级指数为0.6,重要性采样指数设置为0.4。在图2中,左边,我们将所有57个游戏的人类标准化得分的中位数与几个基线进行比较:DQN,优先级DQN,分布式DQN(Bellemare等,2017),Rainbow和Gorila。在所有情况下,性能都是在没有操作开始的测试制度(Mnih等,2015)下训练结束时测量的。右边,我们展示了一组6个游戏的初始学习曲线(从最贪婪的Actor中选取)(所有游戏的完整学习曲线在附录中)。考虑到Ape-X可以利用比大多数基线更多的计算,人们可能会期望它训练得更快。图2显示确实如此。或许更令人惊讶的是,我们的Agent实现了明显更高的最终性能。在表1中,我们将Ape-X DQN在ATARI基准测试上的人类标准化性能的中位数与他们各自出版物中报告的其他基线Agent的相应指标进行比较。只要可能,我们都会报告没有操作开始和人类开始的结果。人类开始的制度(Nair等,2015)相当于一个更具挑战性的概括测试,因为Agent是从人类专家玩的游戏中随机抽取的开始进行初始化的。根据这两个指标,Ape-X的性能高于所有基线的性能。
4.2 CONTINUOUS CONTROL 连续控制任务
在第二组实验中,我们在四个连续控制任务上评估了Ape-X DPG。在manipulator领域,Agent必须学习将球带到指定的位置。在humanoid领域,Agent必须学习控制一个人形体来解决三个不同的、复杂度递增的任务:站立,走路和跑步。由于我们从特征中学习,而不是从像素中学习,所以观察空间比在ATARI领域要小得多。因此,我们使用小型的、完全连接的网络(详细信息在附录中)。在这个领域上有64个Actor,我们获得了约14K的总FPS(每秒转换的同样数量;这里我们不使用动作重复)。我们每秒处理86批256个转换,或者每秒处理约22K个转换。图3显示Ape-X DPG在所有四项任务上都取得了很好的性能。该图显示了不同Actor数量的Ape-X DPG的性能:随着Actor数量的增加,我们的Agent在快速可靠地解决这些问题上越来越有效,超过了训练时间超过10倍的标准DDPG基线。一个并行的论文(Barth-Maron等,2018)通过将Ape-X DPG与分布价值函数相结合来扩展了这项工作,生成的算法成功地应用于进一步的连续控制任务。

图 3:Ape-X DPG在四个连续控制任务上的性能,以墙钟真实时间(Wall Clock)为函数。随着我们增加执行者的数量,性能提高。黑色虚线表示标准DDPG基线在5天训练中达到的最高性能。

图 4:扩展Actor的数量。随着我们将Actor的数量从8增加到256,性能始终在提高,注意,进行的学习更新的数量并不依赖于Actor的数量。
5 分析
在本节中,我们将描述在Atari上进行的额外Ape-X DQN实验,这些实验有助于我们更好地理解这个框架,并研究不同组件的贡献。首先,我们研究了性能如何随Actor数量的增加而变化。我们在Atari的6个游戏的子集上,使用不同数量的Actor(8、16、32、64、128和256)进行了35小时的训练。在所有实验中,我们都将共享经验Replay内存的大小固定在1百万次转换。图4显示,随着Actor数量的增加,性能一直在改善。附录中包含了其他游戏的学习曲线,以及与和没有优先Replay的算法的可扩展性比较。令人惊讶的是,仅仅通过增加Actor数量,而不改变网络参数更新的速率、网络的结构或更新规则,性能就大幅度提高了。我们假设,所提出的架构有助于解决深度强化学习常见的失败模式,即找到的策略在参数空间中是局部最优的,但不是全局最优的,例如,由于探索不足。使用大量的、探索程度不同的Actor有助于发现有希望的新Acting路线,优先Replay确保当这种情况发生时,学习算法集中精力处理这些重要的信息。接下来,我们研究了改变Replay内存容量的影响(见图5)。我们使用了256个Actor的设置,总的环境帧速率约为37K每秒(约9K转换)。对于这么大数量的Actor,内存中的内容替换得比大多数类似DQN的Agent快得多。我们观察到,使用更大的Replay容量有些许的好处。我们推测这是因为保留一些高优先级的经验更长时间并Replay它们的价值。如上所述,一个单独的学习机器以每秒19个批次的中位数训练网络,每个批次包含512个转换,每秒处理约9.7K个转换。最后,我们进行了额外的实验,以解开我们的可扩展性分析中两个可能混淆的因素的潜在影响:Replay记忆中的经验数据的近期性,和数据生成策略的多样性。这些实验的完整描述被限制在附录中;总结一下,单独的任何一个因素都不能解释我们看到的性能。因此,我们得出的结论是,这些结果主要归因于收集更多经验数据的积极影响;也就是说,更好地探索环境和更好地避免过拟合。

图 5:改变Replay的容量。拥有更大重播记忆的代理在大多数游戏中表现更好。每条曲线对应一次运行,平滑过20个点。因为训练发散,Wizard Of Wor的重播大小为250K的曲线并不完整;我们并未在其他重播大小中观察到这种情况。
6 结论
我们设计、实施和分析了一个用于深度强化学习中优先Replay的分布式框架。这个架构在一系列离散和连续任务中达到了最先进的结果,无论是在墙钟(Wall Clock)学习速度还是最终性能方面。在这篇文章中,我们专注于将Ape-X框架应用到DQN和DPG,但它也可以与任何其他离策强化学习更新结合。对于使用时间扩展序列的方法(例如,Mnih et al., 2016;Wang et al., 2017),Ape-X框架可以被调整为优先考虑过去经验的序列,而不是单个转换。Ape-X被设计为在可以并行生成大量数据的环境中使用。这包括模拟环境,也包括各种实际应用,如机械臂农场、自动驾驶汽车、在线推荐系统,或其他数据由同一环境的多个实例生成的多用户系统(参考Silver et al., 2013)。在数据获取成本高的应用中,我们的方法将无法直接应用。对于强大的函数近似器,过拟合是一个问题:生成更多的训练数据是解决这个问题的最简单的方法,但也可能为数据效率高的解决方案提供指导。许多深度强化学习算法本质上受到其在大领域中有效探索能力的限制。Ape-X使用一个简单而有效的机制来解决这个问题:生成各种各样的经验,然后识别并学习最有用的事件。这种方法的成功表明,即使对于同步Agent,简单直接的探索方法也可能是可行的。我们的架构表明,分布式系统现在不仅适用于研究,而且可能适用于深度强化学习的大规模应用。我们希望我们所提出的算法、架构和分析将有助于加速未来在这个方向上的努力。
论文总结
OpenAI的这篇论文提出了Ape-X框架,分别与DQN和DDPG控制相结合,用于离散控制与连续控制。综合使用了以下算法特性:
中央化回放存储器(Centralized Replay Memory)
这是一种用于存储和回放之前的经验(即决策和结果)的设备。这段文本中提到的新方法使用的是共享的、中央化的回放存储器。这与Nair等(2015)的方法不同,他们使用的是分布式的回放存储器。
优先采样(Prioritized Sampling)
在从回放存储器中选择经验进行学习时,作者没有均匀地随机采样,而是优先采样最有用的数据。这意味着某些经验(如那些有助于提高模型性能的经验)会被更频繁地采样。
优先级共享(Priority Sharing)
所有的执行者(actors)共享数据优先级,这意味着任何执行者发现的高优先级数据都可以惠及整个系统。
执行者计算优先级(Actors Compute Priorities)
为了使优先级更精确,执行者在生成新的经验时就计算出新经验的优先级。这样,等待学习器(learner)更新优先级的时间就缩短了,同时可以防止系统过分关注最近的数据(因为新数据的优先级默认是最高的)。
经验共享优于梯度共享(Experience Sharing Vs Gradient Sharing)
系统中的执行者共享经验,而非梯度。因为经验数据过时的速度比梯度慢,所以在分布式随机梯度下降(SGD)中,低延迟通信并不像共享经验那样重要。
批量通信(Batched Communication)
系统通过将所有的通信与中央回放存储器进行批处理,增加了效率和吞吐量,尽管这可能会增加一些延迟。
离策略学习(Off-Policy Learning)
通过离策略学习,即执行者和学习器使用不同的策略,该方法可以从多个执行者中收集更广泛的经验,从而提高学习的效果。
不同地理位置的执行者和学习者(Actors and Learners in Different Locations)
执行者和学习者甚至可以在不同的数据中心运行,这并不会限制系统的性能。
不同的探索策略(Diverse Exploration Policies)
通过给不同的执行者赋予不同的探索策略,可以增加他们共同遇到的经验的多样性。这就意味着这个系统有能力学习到更多种的情况和应对策略,从而在解决问题时能有更丰富的选项。
应对复杂探索问题的能力(Capability to Address Complex Exploration Problems)
作者提到,这种方法中各种元素的结合,特别是采用多样化的探索策略和离策略学习,足以在复杂的探索问题上取得进展。