高性能的 ReplayBuffer 应该满足以下三点:
- 随机采样 random sample 的速度要快,尽可能加快读取速度(最为重要)
- 减少保存的数据量,增加吞吐效率(对分布式而言重要)
- 保存能简化计算的变量(对特定算法而言重要)
为了达成以上要求,我建议做出以下修改:
- 把 Replay Buffer 的数据都放在连续的内存里,加快读取速度
- 按 trajectory 的顺序保存 env transition,避免重复保存 next state,减少数据量
- 分开保存 state 与其他数据,减少数据量
- 将 off-policy 的数据一直保存在显存内
- 保存
mask = gamma if done else 0用于计算 Q 值,而不是保存 done - 为 on-policy 的 PPO 算法保存
noise用于计算新旧策略的熵
本文的重点:ReplayBuffer 的数据要放在连续内存里,实验结果如下:
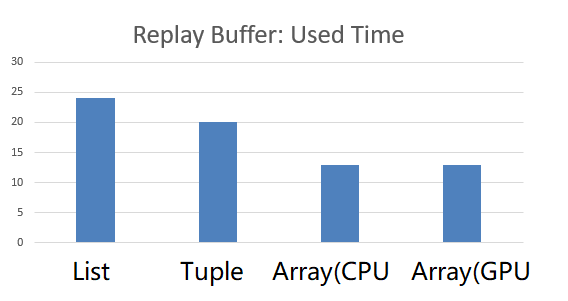
我们使用 Numpy 库在内存里、使用 PyTorch 库在显存里 创建了一整块连续的空间,对比了 List 和 Tuple 的方案。结果:连续存储空间的明显更节省时间。