整天说Batch Norm,CNN的论文里离不开Batch Norm。BN可以使每层输入数据分布相对稳定,加速模型训练时的收敛速度。但BN操作在CNN中具体是如何实现的呢?
1. BN在MLP中的实现步骤
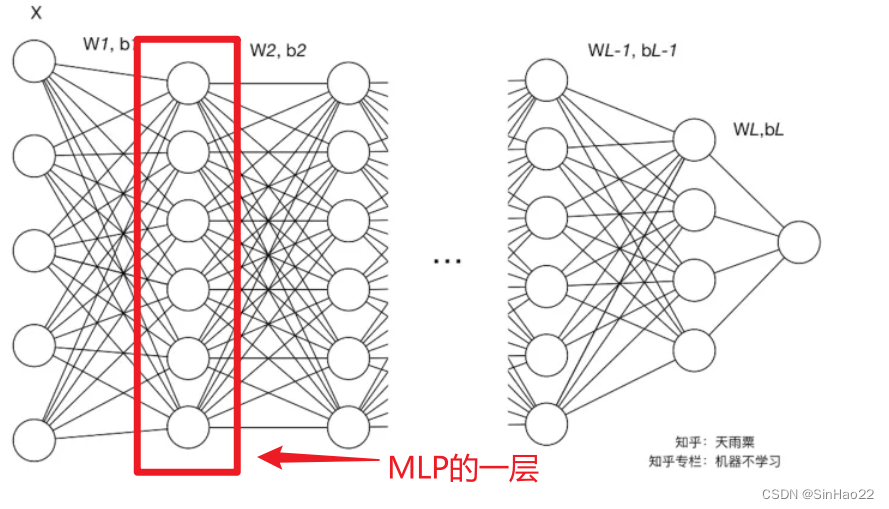
首先快速回顾下BN在MLP中是怎样的,步骤如下图:

图片来源:BN原论文
一句话概括就是对于每个特征,求一个batch求均值和方差。然后该特征减去均值除以标准差,再进行一个可以学习参数的线性缩放(即乘以γ加上β)即可。本质上是对输入进行线性缩放,使得每层的输入数值分布相对稳定。
在MLP中更具体的实现可以参考BN原论文,也可以看这篇讲解——Batch Normalization原理与实战,写得非常清楚。
2. BN在CNN中的实现细节
其实本质上还是对于每层进行线性缩放,使得每层的数据分布相对稳定。但由于MLP中的一层是一个1D的向量,而CNN的每一层是一个3D的tensor,所以具体实现细节还是有差异的。
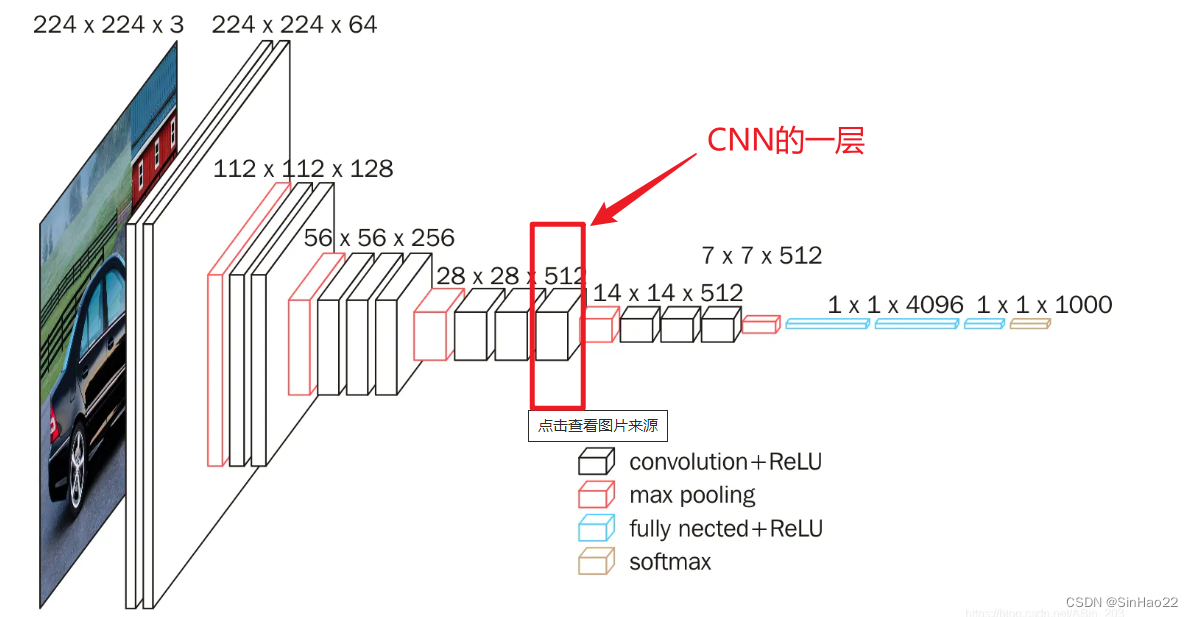
整体过程还是和上面的步骤一致:
2.1 训练过程

只是我们不在对每个特征,求一个batch的均值和方差;而是对每个feature map,求一个batch的均值和方差。
也可以这么表述:MLP是对在特征维度(即每个神经元)求均值和方差,而CNN是在通道(channel)维度(即每个feature map)求均值和方差。
表述得更清楚一些:
上图中红框圈出的是CNN的一层,形状是(C, H, W),其中,C是通道个数(即feature map的数量),H和W是feature map的长和宽。我们可以这么理解:CNN的一层是一个3D的矩阵,是由C层2D的feature map组成的。
若一个batch有N张图片,则红框圈出的一层的形状为(N, C, H, W),即共有NxCxHxW个数值。
在训练时,BN做的就是在该batch中,对该层每一个feature map的所有数据(即第二个维度C,共有C个feature map),求均值和方差。即对NxHxW个数据求均值μ和方差σ。【一个feature map有HxW个数据,一个batch中有N张图片】即对第i个feature map,有与之对应的μ_i和σ_i。
因为一层有C个feature map,所以就共有C个μ_i和σ_i。i∈[1, C]
其余过程就和MLP一样了:第i个feature map每个元素减去对应的均值μ_i除以标准差,然后再进行一个可以学习参数的线性缩放(即乘以γ加上β)即可。
2.2 前向推断过程
和MLP一样,在训练过程中,每个batch都会求出C个均值和方差(因为每个feature map都会有一个均值和方差)。
而在前向推断过程,则对于所有的batch的每个feature map的均值和方差做平均,论文中是求出所有均值的期望和方差的无偏估计,如下:
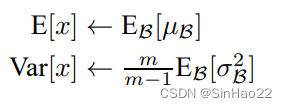
得到前向推断时每一层feature map的均值μ_i_test和方差σ_i_test。然后第i个feature map每个元素减去对应的均值μ_i_test除以标准差,然后再进行一个的线性缩放(即乘以γ加上β)即可。其中γ和β是训练过程已经训练好的。
总而言之:MLP是对在特征维度(即每个神经元)对一个batch求均值和方差,而CNN是在通道(channel)维度(即每个feature map)对一个batch求均值和方差。
END:)
总觉得文字还是无法完全把我的想法表述清楚,最好的学习方法还是去看原论文,然后自己多琢磨。
参考:
1.【原论文】 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift