目标:AI设计基础–采集数据
作为AI算法工程师,面对新需求,明明方法千万条,数据没一条。老是为了做一个功能,费尽心思求数据而不得,或找到现有数据集不理想,匹配度不高。本文就学习一下怎样快速下载数据资源(资源:文字文章,图像,影像)。
- 数据不求人。
- 熟悉网页请求库,urllib,requests,beautiful soup。
- 重点学习scrapy框架,学会灵活使用这个工具。
学习内容:
scrapy框架的使用给我的感觉和Django框架的应用差不多。
本节将简要介绍Scrapy的安装,命令和实现过程。
安装
Scrapy:Scrapy是用 Python 写的。采用虚拟环境安装,一行代码自动匹配安装依赖库。
安装:conda install -c conda-forge scrapy
其他方式安装,手动匹配安装一下依赖库。
安装依赖库:
lxml 一个高效的XML和HTML解析器
parsel ,一个写在lxml上面的html/xml数据提取库,
w3lib ,用于处理URL和网页编码的多用途帮助程序
twisted 异步网络框架
cryptography 和 pyOpenSSL ,处理各种网络级安全需求
基础命令
Scrapy工具提供了多个命令,用于多种目的,每个命令接受一组不同的参数和选项。
scrapy <command> -h 查看命令使用方法的帮助
scrapy -h 框架使用帮助
全局命令:
startproject新建项目; genspider ;settings;runspider;shell;fetch;view;version
仅Project命令:
crawl爬;check;list;edit;parse;bench
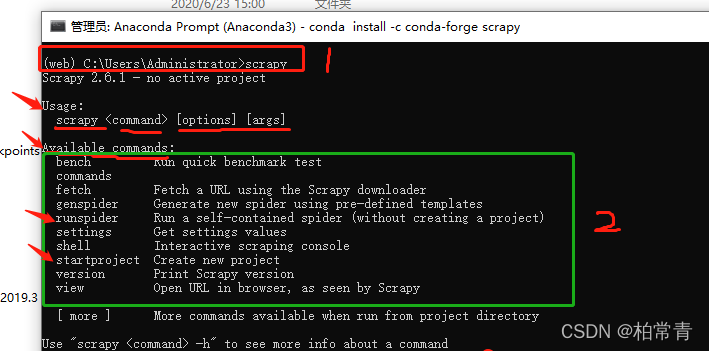
提升示例
也可以参见入门教程:入门教程:https://www.osgeo.cn/scrapy/intro/tutorial.html
-
scrapy startproject <project_name> [project_dir]
创建一个名为 project_name 下 project_dir 目录。如果 project_dir 没有指定, project_dir 将与 project_name .例如:虚拟环境Anaconda3下切换到对应的虚拟环境,
activate web。输入:scrapy startproject spider_one新建一个项目。

目录包含以下内容:
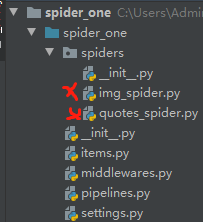
创建一只爬虫蜘蛛,就是在spider里面新建一个继承scrapy.Spider的类。以访问名字方式使用。
spiders文件夹下就是装有蜘蛛的.py文件了。xx就是我自己建的两个不同类型蜘蛛。(注,不以文件名为蜘蛛数,以继承的scrapy.Spider类为计)
conda命令行处,cd spider_one,后切换IDE.
使用pycharm打开项目,将项目的环境设置为当前安装了scrapy的虚拟环境。
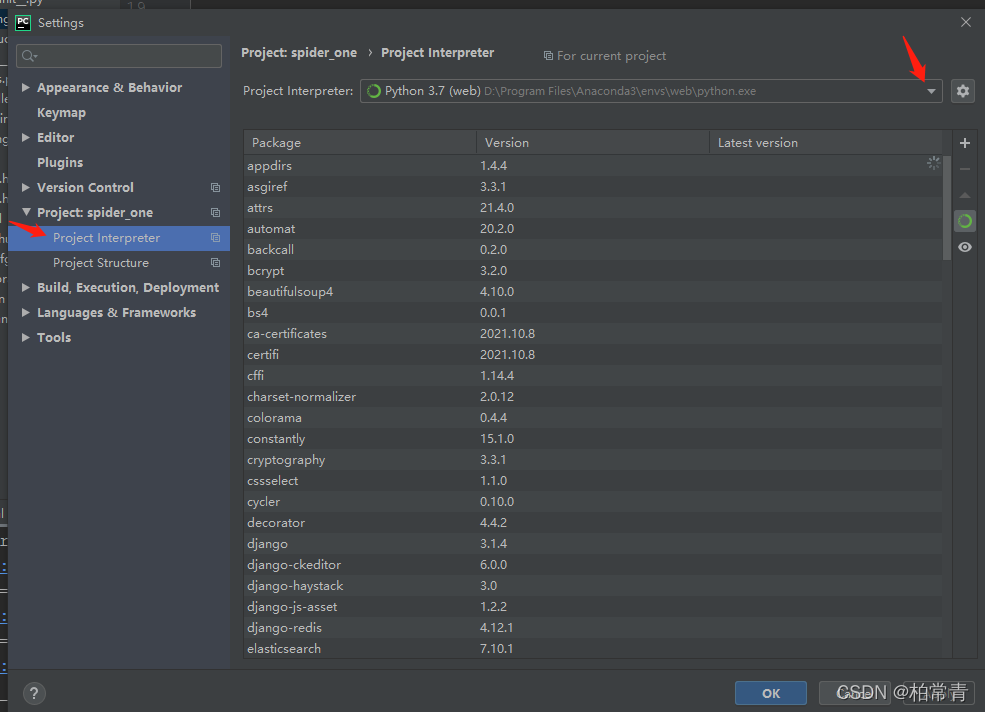
scrapy手册实例之爬取网站名人名言:scrapy startproject spider_one
专门用来举例爬虫框架的一个网站网址:http://quotes.toscrape.com/
代码都很简单,这里需要重点说明的有两点:一是两种选择器:css,xpath,二是翻页与重组网址使用的4种方法。源码:spiders文件见下的quotes_spider.py:
# !/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2022/3/23 15:41 # @Author : Haiyan Tan # @Email : [email protected] # @File : quotes_spider.py # Begin to show your code! import scrapy # 如何使用scrappy跟踪链接和回调的机制 class QuotesSpider(scrapy.Spider): name = "quotes" # 标识蜘蛛.它在一个项目中必须是唯一的,即不能为不同的爬行器设置相同的名称。使用时:scrapy crawl quotes # 创建一个可以返回请求列表或编写生成器的函数 def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', # 'http://quotes.toscrape.com/page/2/', ] for url in urls: # 爬行器将从该请求开始爬行。后续请求将从这些初始请求中相继生成。 yield scrapy.Request(url, callback=self.parse) # 实例化 Response 对象,并调用与请求关联的回调方法(parse 方法)将响应作为参数传递。 def parse(self, response, **kwargs): # parse()是Scrapy的默认回调方法 page = response.url.split('/')[-2] # filename = f'quote-{page}.html' # with open(filename, 'wb') as f: # f.write(response.body) # self.log(f'Saved file {filename}') for quote in response.css('div.quote'): yield { 'text': quote.css('span.text::text').get(), 'author': quote.css('small.author::text').get(), 'tags': quote.css('div.tags a.tag::text').getall(), } next_page = response.css('li.next a::attr(href)').get() if next_page is not None: # 递归地跟踪下一页的链接 4种方法 方法1 # next_page = response.urljoin(next_page) # yield scrapy.Request(next_page, callback=self.parse) # 方法2 # 不像Scrapy.Request, response.follow 直接支持相对URL-无需调用URLJOIN。 yield response.follow(next_page, callback=self.parse) # 创建请求对象的快捷方式 # 要从iterable创建多个请求 方法3 # anchors = response.css('ul.pager a') # yield from response.follow_all(anchors, callback=self.parse) # 等价于 方法4 # yield from response.follow_all(css='ul.pager a', callback=self.parse)next_page = response.css('li.next a::attr(href)').get() if next_page is not None:递归地跟踪下一页的链接 4种方法
方法1:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)方法2: response.follow 直接支持相对URL-无需调用URLJOIN。
yield response.follow(next_page, callback=self.parse)# 创建请求对象的快捷方式方法3:通过iterable创建多个请求
anchors = response.css('ul.pager a')
yield from response.follow_all(anchors, callback=self.parse)扫描二维码关注公众号,回复: 15279776 查看本文章
方法4:等价于方法3
yield from response.follow_all(css='ul.pager a', callback=self.parse)settings.py的修改
BOT_NAME = 'spider_one' SPIDER_MODULES = ['spider_one.spiders'] NEWSPIDER_MODULE = 'spider_one.spiders' LOG_LEVEL = 'ERROR' # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = True -
运行蜘蛛:
scrapy crawl <spider>
scrapy crawl quotes# 第三步,运行抓取name= quotes
或者:scrapy runspider quotes_spider.py -o quotes.jl
更多详细信息,请参考scrapy的使用手册。
进阶使用:多页取图
取图片是取文字信息的流程上加入管道和图像保存机制。
取网站:主页:https://699pic.com/
搜对象狗的网址:https://699pic.com/tupian/photo-gou.html
-
首先在items.py里定义图像命名,图像网址等字段。
items.pyimport scrapy class MyImagesItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() image_urls = scrapy.Field() images = scrapy.Field() image_path = scrapy.Field() -
在设置文件
settings.py新增或设定配置信息。
设置图片保存的路径,项目保存的最长时间90,设置的图片尺寸大小。设置管道。# Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html # 图像、管道 ITEM_PIPELINES = { 'spider_one.pipelines.ImgPipeline': 300, # 'scrapy.pipelines.images.ImagesPipeline': 1, } # 设置图片保存的路径,项目保存的最长时间90,设置的图片尺寸大小 IMAGES_STORE = r'E:\\Datasets\\obj_detect_data\\scrapy_images_0325\\' IMAGES_EXPIRES = 90 IMAGES_MIN_HEIGHT = 100 IMAGES_MIN_WIDTH = 100 -
定义管道
pipelines.py# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface import scrapy from itemadapter import ItemAdapter from scrapy.pipelines.images import ImagesPipeline from scrapy.exceptions import DropItem class ImgPipeline(ImagesPipeline): def get_media_requests(self, item, info): return [scrapy.Request(x) for x in item.get(self.images_urls_field, [])] def item_completed(self, results, item, info): if isinstance(item, dict) or self.images_result_field in item.fields: item[self.images_result_field] = [x for ok, x in results if ok] return item -
最后,在spiders文件夹下定义取图片的蜘蛛。
img_spider.py# !/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2022/3/24 16:29 # @Author : Haiyan Tan # @Email : [email protected] # @File : img_spider.py # Begin to show your code! import scrapy from ..items import * class ImgSpider(scrapy.Spider): name = 'imgspider' allowd_domains = ['699pic.com', ] start_urls = [ 'https://699pic.com/tupian/photo-gou.html', ] def parse(self, response, **kwargs): items = MyImagesItem() # items['image_urls'] = [response.urljoin(response.xpath('//a/img/@data-original').get())] items['image_urls'] = response.xpath('//a/img/@data-original').getall() for i, urls in enumerate(items['image_urls']): items['image_urls'][i] = response.urljoin(urls) yield items yield from response.follow_all(xpath='//div[@class="pager-linkPage"]/a/@href', callback=self.parse) # next_page = response.xpath('//div[@class="pager-linkPage"]/a/@href').get() -
运行项目:
scrapy crawl --nolog imgspider
取图片数目:24527张

Debug:scrapy ERROR: Error processing {'image_urls':
原因:Scrapy tryies to process your string as a list of image URLs:
修改与这个test_item['image_urls'] = [image_urls]一致。
Debug:ValueError: Missing scheme in request url:
scrapy会对request的URL去重(RFPDupeFilter),加上dont_filter则告诉它这个URL不参与去重。
两种方法能够使 requests 不被过滤:
- 在 allowed_domains 中加入 url
- 在 scrapy.Request() 函数中将参数
dont_filter=True设置为True
意思就是,scrapy可能会处于一些原因把没有问题的url过滤掉,我们只有加上这样的命令才能防止丢失。