散记知识点
——“探索复杂高级的分类方法”
1.神经网络
1.1 神经网络的基本概念
(1) 定义
- 神经网络是一组连接的输入/输出单元,其中每个连接都与一个权重相关联。在学习阶段,通过调整这些权重,使得它能够预测输入元组的正确类标号来学习。
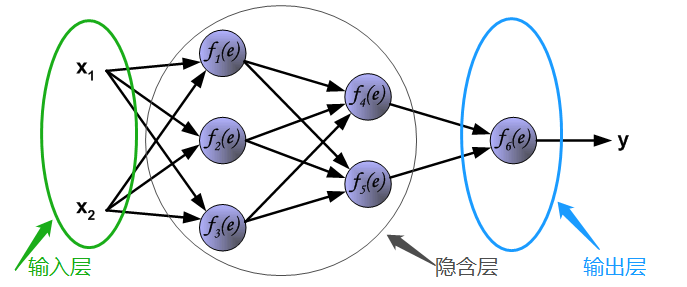
(2) 前馈神经网络结构
- 前馈神经网络,又称后向传播(BP, back propagation)神经网络。由一个输入层、一个或多个隐含层和一个输出层组成。
-
- 其中,每个输入层的每个输入 对应于每个训练元组 的观测属性,一般被称为输入神经元。输入层加权偏置后的输出作为每个隐含层神经元输入,每个隐含层神经元经过非线性激活函数 然后加权偏置的输出作为下一层每个隐含层输入……最后一层神经元称为输出神经元。它的输入为上一隐含层的输出,输出为类标号判别结果。
- 多层前馈神经网络可以将类预测作为输入的非线性组合。给定足够多的隐含层单元和足够多的训练样本,多层前馈神经网络可以逼近任意函数。
1.2 神经网络的构造
(1) 网络结构
- 输入层:输入层神经元个数取决于输入的数据,例如一个数据元组的 个属性值,组成向量作为输入。
- 隐含层:按照实际需求预定义隐含层层数以及隐含层神经元个数,后期可以不断优化调整。
- 输出层:输出层神经单元个数取决于特定的问题,比如二分类问题可以使用一个输出,多分类问题对应多个输出。
(2) 输入和输出
对于输入:
- 连续值属性:对每个属性值进行规范化至(0, 1)之间,有助于加快学习进程。
- 离散值属性:可以进行编码,使得每个值对应一个输入单元。例如,属性 有三个可能的值 ,则可以为 分配三个输入单元 。假如 ,则 置为1,其余为0
对于输出:
- 用于数值预测时,输出值为具体数值。
- 用于分类时:二分类问题对应一个输出单元,输出为0和1(1表示正类,0表示负类);多分类问题时,每个可能的分类对应一个输出值,通过具体策略(例如每个输出对应的概率大小),来确定类标号。
(3) 权值和偏置值初始化
开始训练之前,需要对网络中的权值和偏置值进行初始化,一般初始化为小随机数(-1,1)或(-0.5,0.5)。也可以使用小标准差的正态分布进行初始化权值和偏置值。
(4) 激活函数
隐含层和输出层的每个神经元都包含一个激活函数,结构如下表示:
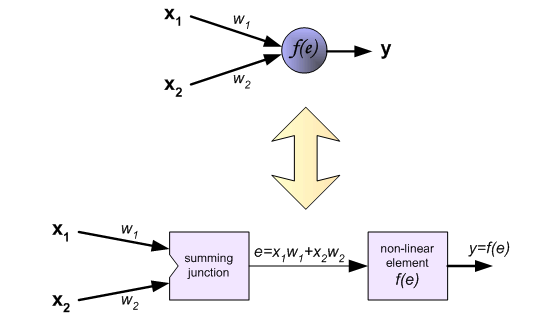 激活函数将上一层来的一个较大的输入值映射到一个小的区间(0, 1)。一般激活函数都是非线性可微的,使得后向传播算法可以对非线性可分的分类问题建模。 关于各类激活函数的总结可以参考转载文章:[神经网络各种激活函数总结](https://blog.csdn.net/weixin_40170902/article/details/80022981) **(5) 代价函数** 在训练神经网络的过程中,会选择特定的代价函数来**衡量预测值与真实值之间的差距**。BP神经网络通过这个差距,**反向传递误差**,来不断地更新权值和偏置值。 代价函数的选择需要结合具体问题,有的时候需要配合激活函数进行选择。更多关于代价函数的内容在:[机器学习:神经网络代价函数总结](https://blog.csdn.net/weixin_40170902/article/details/80032669) 。 ———-
1.3 BP神经网络后向传播算法
采用BP算法的多层感知器是至今为止应用最广泛的神经网络。
(1) BP算法的基本思想
学习过程由信号的正向传播与误差反向传播两个过程组成:
- 信号的正向传播:正向传播时,输入样本从输入层传入,经各隐含层逐层处理,传向输出层。若输出层的输出值与真实值不符,则转入误差反向传播阶段。
- 误差的反向传播:反向传播时,输出值与真实值的误差以某种形式通过隐含层向输入层逐层反传,并将误差分摊给各层的所有神经元。从而获得各层神经元的误差信号,此误差信号即作为修正各层权值和偏置值的一句。
这种信号的正向传播与误差反向传播的各层权值和偏置值调整的过程不断重复进行。权值和偏置值更新的过程,就是网络学习训练的过程。直到网络的输出误差减少到可接受的程度,或进行到预设的学习次数,才能够停止训练。
(2) BP算法推导
以一个三层BP神经网络(包含一个隐含层)为例:
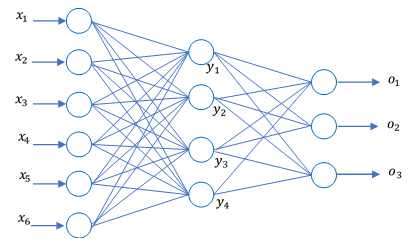 输入向量为
;隐含层输出向量为
;输出层输出向量为
,真实值向量为
。 假定输入层和隐含层之间的权值矩阵用
表示,其中列向量
为隐含层第
个神经元对应的权向量,对应的偏置值向量
;隐含层到输出层的权值矩阵用
表示,其中列向量
为输出层第
个神经元对应的权向量,对应的偏置值向量
。 ① **正向传播时**,各层信号之间的数学关系为: - 对于**输入层-隐含层**:
- 对于**隐含层-输出层**:
其中,
为激活函数这里令其为sigmoid函数:
导函数和自身的关系为:
② **网络误差定义**与**权值调整思路** - 使用**二次代价函数**,定义输出层输出与真实值存在误差时,定义误差为
:
- 将上式误差函数展开至隐含层:
- 进一步展开至输入层:
可以看出,调整权值和偏置值可以改变误差
。而要使得误差不断地减小,则权值和偏置值的调整量应与误差的梯度下降成正比。即:
其中,
表示比例系数,被称为**学习率**。 **③** **反向传播**时,**更新权值**和**偏置值** - 对于**输出层**,权值的更新:
- 对于**隐含层**,权值的更新:
- 对**输出层和隐含层**各定义一个误差信号为:
则此时**输出层和隐含层的权值更新分别为**:
- 对于**输出层,误差信号
**可展开为:
- 对于**隐含层,误差信号
**可展开为:
至此将误差信号带回权值更新公式得,**三层BP神经网络得权值更新计算公式**为: - 输出层:
- 隐含层:
同理,偏置值得更新公式为: - 输出层:
- 隐含层:
**④ 扩展到多层与矩阵向量表示形式** 设共有
隐含层,从前往后各隐含层神经元个数分别为
,各隐含层输出分别记为
,各层权值矩阵分别记为
,则各层权值更新公式为: - **输出层**:
- **第
个隐含层**:
- 以此类推,**第一个隐含层**:
三层BP神经网络得矩阵向量形式为: - **输出层**:设
,
,则:
- **隐含层**:设
,
,则:
可以看出,BP神经网络中,各层权值调整公式形式熵都是一样的,均由3个因素决定,即:学习率
,本层输出误差信号
以及本层输入信号
。其中输出层误差信号与网络的输出和真实值之间的误差有关,各隐含层的误差信号与前面各层误差信号都有关,是从输出层开始逐层反向传递过来的。 ———-
1.4 Python简单实现BP神经网络
下面用python简单训练构造一个4层BP神经网络(两个隐含层),该网络用于一个二分类问题。
(1) 数据集
- 使用UCI数据集中的Breast Cancer Wisconsin (Original) Data Set ,该数据集有9个属性(除了第1个标号属性外),1个类别。
- 属性值都介于1-10之间,因此方便归一化,即直接除以10即可。类别值为”2”和”4”,分别代表乳癌的“良性”和“恶性”,处理时分别令值为0和1.
- 原数据集中有缺失值用”?”代替,为了方便处理,剔除了缺失值。
- 取前500个样本作为训练集,后100多个样本作为测试集。
(2) 网络结构
- 为简单处理,定义一个4层神经网络,1个输入层,2个隐含层,1个输出层
- 输入层神经元个数为9(即属性个数),自定义第1个隐含层6个神经元,第二个隐含层为4个神经元。
- 输出层神经元个数为1个。测试时,当输出值大于0.5判为1;否则,判为0。
(3) 程序处理过程及难点分析
程序处理过程
- 为了方便计算,在训练网络时,都采用矩阵向量的运算。
- 网络训练过程分为两个部分:一是正向传播;二是误差反向传递。
- 设定一个最小均方误差阈值,满足阈值,则停止训练;不满足则继续训练,可以反复利用训练集。
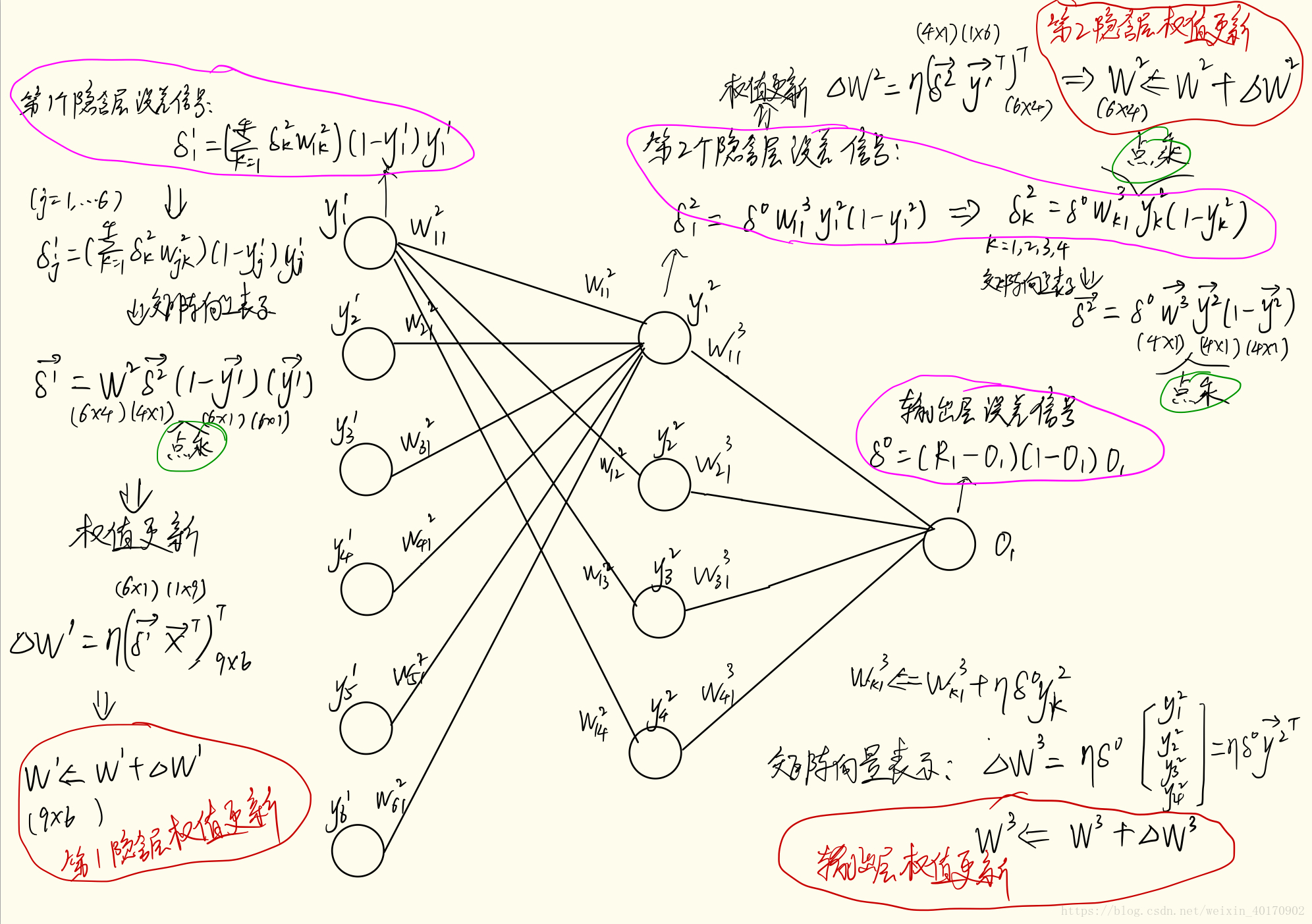
难点分析
- 反向误差传递及矩阵向量计算形式
- 下图列举了两个隐含层的误差信号传递及权值个更新分析过程
(4) python代码及运行结果
# -*- coding: utf-8 -*-
__author__ = "Yunfan Yang"
import numpy as np
def str2int_list(list1):
"""将列表中的字符串转变为数字"""
list2 = []
for value in list1:
list2.append(int(value))
return list2
def data_prep(filename):
"""读取数据集文件,进行数据预处理,返回属性和标签列表"""
with open(filename, 'r') as f:
raw_data = f.read()
data_str_list1 = raw_data.split('\n')[:-1] # 以'\n'分割,创建数据字符串列表,每个字符串为一个数据元组
data_str_list2 = [li.split(',')[1:] for li in data_str_list1] # 以','分割数据元组,去掉第一项标号,剩下10项,前9项为属性,后1项为类别
data_set = []
for data_str in data_str_list2:
if '?' not in data_str: # 为简单处理,剔除缺失值项
data_tuple = str2int_list(data_str)
data_set.append(data_tuple)
# print(data_set)
# 创建属性列表和类别列表
attribute_list = []
label_list = []
for data in data_set:
a_list = np.array(data[:-1]) / 10 # 归一化处理
attribute_list.append(a_list)
if data[-1] == 2:
c = 0
else:
c = 1
label_list.append(c)
return attribute_list, label_list
def train_network(W1,b1,W2,b2,W3,b3,train_attribute_data,train_label_data):
# 开始训练网络
t = 0
s = 0
eta = 0.6 # 学习率
min_rmse = 0.05 # 最小均方误差阈值
Goon = 1
while Goon==1:
# 正向传播时
X = train_attribute_data[t] # 输入
W1_X = np.matrix(X) * W1 + b1 # 第一个隐含层输入
Y1 = 1 / (1 + np.exp(-W1_X)) # 第一个隐含层的输出
# print(Y1)
W2_Y1 = np.matrix(Y1) * W2 + b2
Y2 = 1 / (1 + np.exp(-W2_Y1)) # 第二个隐含层的输出
# print(Y2)
W3_Y2 = np.matrix(Y2) * W3 + b3
O1 = 1 / (1 + np.exp(-W3_Y2))[0] # 输出层输出
R1 = float(train_label_data[t]) # 真实值
# print(R1)
# 计算误差
error = R1-O1
rmse = np.sqrt(np.square(error)) # 均方误差,作为判断训练是否终止准则
# print(rmse)
# 反向传播误差
delta_o = (R1-O1)*(1-O1)*O1 # 输出层误差信号
delta_y2 = np.array(delta_o*W3.T) * np.array(1-Y2) * np.array(Y2) # 第2隐含层误差信号
delta_y1 = np.array(np.matrix(delta_y2)*W2.T) * np.array(1-Y1) * np.array(Y1) # 第1隐含层误差信号
Delta_W3 = eta * delta_o * Y2
W3 = W3 + Delta_W3.T # 输出层权值更新
b3 = b3 + eta * delta_o # 输出层偏置值更新
Delta_W2 = eta * Y1.T *delta_y2
W2 = W2 + Delta_W2 # 第2隐含层权值更新
b2 = b2 + eta * delta_y2 # 第2隐含层偏置值更新
Delta_W1 = eta * np.matrix(X).T * delta_y1
W1 = W1 + Delta_W1 # 第1隐含层权值更新
b1 = b1 + eta * delta_y1 # 第1隐含层偏置值更新
t+=1
s+=1
if t >= 499:
if rmse < min_rmse: # 给定RMSE阈值为0.05
Goon = 0 # 满足该准则,停止训练输出网络
print("总训练次数为:",s,"次")
else: # 不满足则继续训练
t = 0
Goon = 1
return W1,b1,W2,b2,W3,b3 # 返回训练后的参数
def test_network(W1,b1,W2,b2,W3,b3,test_attribute_data,test_label_data):
"""测试网络"""
match_count = 0
for i in range(len(test_attribute_data)):
X = test_attribute_data[i]
W1_X = np.matrix(X) * W1 + b1 # 第一个隐含层输入
Y1 = 1 / (1 + np.exp(-W1_X)) # 第一个隐含层的输出
W2_Y1 = np.matrix(Y1) * W2 + b2
Y2 = 1 / (1 + np.exp(-W2_Y1)) # 第二个隐含层的输出
W3_Y2 = np.matrix(Y2) * W3 + b3
O1 = 1 / (1 + np.exp(-W3_Y2))[0] # 输出层输出
if O1 >= 0.5: # 二分类问题,取中间值为判别参考值
O = 1
else:
O = 0
if O == test_label_data[i]:
match_count+=1
else:
pass
correct_ratio = match_count / len(test_label_data)
print("测试集的准确率为:{}%".format(round(correct_ratio*100), 1))
if __name__ == "__main__":
filename = 'breast-cancer-wisconsin.data'
attribute_list, label_list = data_prep(filename)
# 训练集
train_attribute_data = attribute_list[:500] # 前500项为训练集
train_label_data = label_list[:500]
# 测试集
test_attribute_data = attribute_list[500:]
test_label_data = label_list[500:]
# 创建4层神经网络(包含两个隐含层), 先规定第一个隐含层6个神经元,第二个隐含层为4个神经元
# 初始化第一个隐含层的权值和偏置值
W1 = np.random.rand(9, 6)
b1 = np.random.rand(6)
# 初始化第二个隐含层的权值和偏置值
W2 = np.random.rand(6, 4)
b2 = np.random.rand(4)
# 初始化输出层的权值和偏置值
W3 = np.random.rand(4, 1)
b3 = np.random.rand(1)
# 返回训练后的参数
W1, b1, W2, b2, W3, b3 = train_network(W1, b1, W2, b2, W3, b3, train_attribute_data, train_label_data)
# 测试网络
test_network(W1, b1, W2, b2, W3, b3, test_attribute_data, test_label_data)
运行结果:
总训练次数为: 3992 次
测试集的准确率为:99%1.5 BP神经网络两种权值调整方法
在实际应用中,神经网络有两种权值调整方法:单样本训练和周期训练。
(1) 单样本训练
- 上述BP网络,每输入一个样本,都要传回误差并调整权值。这种对每个样本轮训的权值调整方法称为单样本训练。
- 单样本训练遵循只顾眼前的“本位原则”,只针对每个样本产生的误差进行调整,难免顾此失彼,使整个训练的次数增加,导致收敛速度过慢。
(2) 周期训练(批训练)
- 在所有样本输入后,计算网络的总平均误差,根据这个误差反向传播计算各层误差并调整权值和偏置值。这种累计误差的批处理方式称为批(batch)训练或周期(epoch)训练。
- 批训练遵循了以减小全局误差为目标的“集体原则”,因而可以保证总误差向减小的方向变化。在样本数较多时,批训练比单样本训练时的收敛速度快。
2. SVM支持向量机
关于SVM支持向量机,见另一篇文章:机器学习:支持向量机SVM原理与理解
参考资料: