B+树
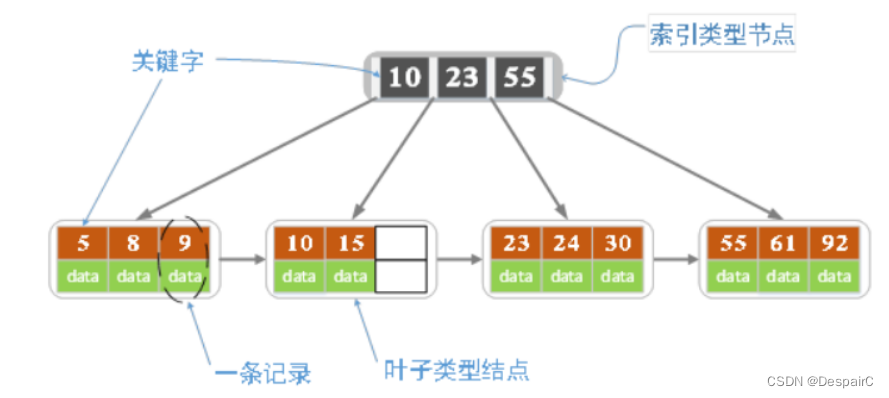
一棵 m 阶的 B+ 树最多有 m - 1 个关键字,孩子结点的个数也就是阶数
上图就是一个 4 阶的 B+树,维基百科上的定义是关键字个数比孩子节点数小 1
构造
B+数是B树的变种,是一颗多叉搜索树,一颗 n 阶的B+树主要有一下特点:
- 每个节点至多有 n 个子女
- 非根节点关键值个数范围: n / 2 <= k <= n - 1
- 叶子节点间通过直接相连
- 非叶节点不保存数据,只做索引作用(可以储存更多的指针)
- 内部节点和父节点的 key 值不能重复,页节点与其父节点可以重复
查询
与 key 比较,逐层向下寻找
插入流程
-
将数据插入到叶子节点当中
-
判断叶子节点的 key 数量是否小于 n
小于
- 结束
大于
- 将该节点分裂成两个叶子节点
- 复制第( n / 2 )个key,将其添加到父节点(内部节点)中
-
判断父节点的 key 数量是否小于n
大于
- 分裂父节点
- 将第( n / 2 )个key,添加到父节点中
分裂叶子节点(具体的内容节点)
节点中的 key 值复制到父结点中(父节点和子节点可以重复)
- 抽出来的值相当于做一个索引,不储存相应的值
比如:
父节点 1
子节点 1 2 3 4 5 6
// 子节点此时候太多了需要分裂
父节点 1 4
子节点 1 2 3 4 5 6
分裂内部节点(也就是索引节点)
也就是说内部节点太多,需要挤压到父节点(父节点和子节点不能够重复)
- 原本就是索引,所以抽出来的也是索引列,可以从子节点中取出
父节点 1
子节点 2 3 4 5 6
--------------------------------
父节点 1 4
子节点 2 3 5 6
删除过程
规则:
子节点个数大于(B+树的阶数 / 2 - 1) Math.ceil(m-1)/2 – 1 向上取整
过程:
- 删除节点后判断是否符合规则
- 若兄弟节点 key 中有富余的key,向兄弟节点借一个key,同时借的key代替成为父节点的索引,否则第 3 步
- 若兄弟节点 key 中没有富余的key,则当前节点和兄弟节点合并成为一个新的节点,删除父节点的key,当前节点指向父节点(必为索引节点)
- 若索引节点的key的个数大于等于规则,结束,否则第 5 步
- 若兄弟节点有富余,父节点key下移,兄弟节点key上移,结束,否则第 6 步
- 当前节点和兄弟节点及父节点下移key合并成一个新的节点。当前节点指向父节点,重复第 4 步
PS:通过 B+ 树的删除操作后,索引节点存在的key,不一定在子节点当中存在相应的记录
前提概要
辅助类
BTreePageId:页面标识符
BTreeInternalPage、BTreeLeafPage、BTreeHeaderPage 和 BTreeRootPtrPage 对象的唯一标识符。
- private final int tableId; // 表id
- private final int pgNo; // 表内的页面id
- private final int pgcateg; // 页面的类型
- public final static int ROOT_PTR = 0;
- public final static int INTERNAL = 1;
- public final static int LEAF = 2;
- public final static int HEADER = 3;
BTreeInternalPage:B+树的内部节点
BTreeInternalPage 的每个实例都存储 BTreeFile 的一页的数据,并实现 BufferPool 使用的 Page 接口。
- private final byte[] header; //槽位占用的情况
- private final Field[] keys; // 记录key的数组
- private final int[] children; // 存储page的序号(PgNo),用于获取左孩子、右孩子的BTreePageId
- private final int numSlots; // 槽数量
- private int childCategory; // 孩子节点的类型:叶子或内部节点
BTreeLeafPage:B+树的叶节点
BTreeLeafPage 的每个实例都存储 BTreeFile 的一页的数据,并实现 BufferPool 使用的 Page 接口
- private final byte[] header; // 槽位占用的情况
- private final Tuple[] tuples; // 元组数组
- private final int numSlots; // 槽数量
- private int leftSibling; // 叶子节点(pgNo)或 0
- private int rightSibling; // 叶子节点(pgNo)或 0
BTreeEntry:
-
private Field key; // 内部节点中的key
-
private BTreePageId leftChild; // 左孩子
-
private BTreePageId rightChild; // 右孩子
-
private RecordId rid; // 储存在页面的路径
Exercise 1
实验一针对的是搜索
BTreeFile
参数
- private final File f; // 文件
- private final TupleDesc td; // 元组的模式
- private final int tableid ; // 表id
- private final int keyField; // 索引键所在的字段
方法
- findLeafPage:递归函数,查找并锁定 B+ 树中与可能包含关键字段 f 的最左侧页面相对应的叶子页面
Map<PageId, Page> dirtypages:当创建新page或更改page中的数据、指针时,需要将其添加到dirtypages中
private BTreeLeafPage findLeafPage(TransactionId tid, Map<PageId, Page> dirtypages, BTreePageId pid, Permissions perm,
Field f)
throws DbException, TransactionAbortedException {
// some code goes here
// 获页面类别
int type = pid.pgcateg();
// 叶子节点
if(type == BTreePageId.LEAF){
return (BTreeLeafPage) getPage(tid, dirtypages, pid, perm);
}
// 锁定路径上的所有内部节点,以READ_ONLY锁
BTreeInternalPage internalPage = (BTreeInternalPage) getPage(tid, dirtypages, pid, Permissions.READ_ONLY);
Iterator<BTreeEntry> it = internalPage.iterator();
BTreeEntry entry = null;
while(it.hasNext()){
entry = it.next();
// 如果要搜索的字段为空,找到最左节点(用于迭代器)
if(f == null){
return findLeafPage(tid, dirtypages, entry.getLeftChild(), perm, f);
}
// 如果找到的节点相等,返回
if(entry.getKey().compare(Op.GREATER_THAN_OR_EQ, f)){
return findLeafPage(tid, dirtypages, entry.getLeftChild(), perm, f);
}
}
return findLeafPage(tid, dirtypages, entry.getRightChild(), perm, f);
}
-
getPage()
封装锁取页面过程的方法。首先,该方法检查本地缓存(“dirtypages”),如果在那里找不到请求的页面,则从缓冲池中获取它。如果以读写权限获取页面,它还会将页面添加到dirtypages缓存中,因为据推测它们很快就会被此事务弄脏。
测试
BTreeFileReadTest.java and the system tests in BTreeScanTest.java.
Exercise 2
实验二针对的是新增节点
BTreeFile
参数
- private final File f; // 文件
- private final TupleDesc td; // 元组的模式
- private final int tableid ; // 表id
- private final int keyField; // 索引键所在的字段
方法
splitLeafPage():分裂叶子节点
public BTreeLeafPage splitLeafPage(TransactionId tid, Map<PageId, Page> dirtypages, BTreeLeafPage page, Field field)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
//
// Split the leaf page by adding a new page on the right of the existing
// page and moving half of the tuples to the new page. Copy the middle key up
// into the parent page, and recursively split the parent as needed to accommodate
// the new entry. getParentWithEmtpySlots() will be useful here. Don't forget to update
// the sibling pointers of all the affected leaf pages. Return the page into which a
// tuple with the given key field should be inserted.
// 1. 获取空白的页面作为新的右页面 (叶子页面)
BTreeLeafPage newRightPage = (BTreeLeafPage)getEmptyPage(tid, dirtypages, BTreePageId.LEAF);
// 2. 插入当前的tuple,分割一半节点给右节点
// 获取反向迭代器
int tupleNum = page.getNumTuples();
Iterator<Tuple> it = page.reverseIterator();
for (int i = 0; i < tupleNum / 2; i++) {
Tuple tuple = it.next();
// 原页面删除
page.deleteTuple(tuple);
// 写入新页面
newRightPage.insertTuple(tuple);
}
// 3. 如果当前 page 有右兄弟,连接右兄弟
BTreePageId oldRightPageId = page.getRightSiblingId();
// 获取页面
BTreeLeafPage oldRightPage = oldRightPageId == null ? null : (BTreeLeafPage) getPage(tid, dirtypages, oldRightPageId, Permissions.READ_ONLY);
if(oldRightPage != null){
// 连接
oldRightPage.setLeftSiblingId(newRightPage.getId());
newRightPage.setRightSiblingId(oldRightPageId);
// 放入脏页缓存
dirtypages.put(oldRightPageId, oldRightPage);
}
// 4. 分裂节点连接
page.setRightSiblingId(newRightPage.getId());
newRightPage.setLeftSiblingId(page.getId());
// 放入脏页缓存
dirtypages.put(page.getId(), page);
dirtypages.put(newRightPage.getId(), newRightPage);
// 5. 获取原节点的内部节点
BTreeInternalPage parent = getParentWithEmptySlots(tid, dirtypages, page.getParentId(), field);
// 右节点的第一个节点作为要挤入父节点的新内部节点值
Field mid = newRightPage.iterator().next().getField(keyField);
// 创建新的内部节点
BTreeEntry entry = new BTreeEntry(mid, page.getId(), newRightPage.getId());
parent.insertEntry(entry);
// 放入脏页缓存
dirtypages.put(parent.getId(), parent);
// 6. 更新page 和 newRightPage的父指针
updateParentPointers(tid, dirtypages, parent);
// 7. 返回 field 所在的页
// 如果当前值大于等于中点,说明在右边节点
if(field.compare(Op.GREATER_THAN_OR_EQ, mid)){
return newRightPage;
}
// 否则在左边节点,也就是原节点
return page;
}
- getEmptyPage():获取空闲的叶子页面
- getParentWithEmptySlots():获得父节点(内部节点),如果满了会触发分裂,也就是下面的方法,分裂内部节点
splitInternalPage():分裂内部节点
public BTreeInternalPage splitInternalPage(TransactionId tid, Map<PageId, Page> dirtypages,
BTreeInternalPage page, Field field)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
//
// Split the internal page by adding a new page on the right of the existing
// page and moving half of the entries to the new page. Push the middle key up
// into the parent page, and recursively split the parent as needed to accommodate
// the new entry. getParentWithEmtpySlots() will be useful here. Don't forget to update
// the parent pointers of all the children moving to the new page. updateParentPointers()
// will be useful here. Return the page into which an entry with the given key field
// should be inserted.
// 1. 获取空白页面 (内部节点)
BTreeInternalPage newRightPage = (BTreeInternalPage) getEmptyPage(tid, dirtypages, BTreePageId.INTERNAL);
// 2. 拆分当前节点
// 获取反向迭代器
Iterator<BTreeEntry> iterator = page.reverseIterator();
int tupleNum = page.getNumEntries();
// 一半的节点移动到右节点
for (int i = 0; i < tupleNum / 2 ; i++) {
BTreeEntry entry = iterator.next();
page.deleteKeyAndRightChild(entry);
newRightPage.insertEntry(entry);
}
// 3. 抽出中间的内部节点
BTreeEntry mid = iterator.next();
// 左页面删除当前节点
page.deleteKeyAndRightChild(mid);
mid.setLeftChild(page.getId());
mid.setRightChild(newRightPage.getId());
BTreeInternalPage parent = getParentWithEmptySlots(tid, dirtypages, page.getParentId(), mid.getKey());
parent.insertEntry(mid);
// 4. 写入脏页缓存
dirtypages.put(page.getId(), page);
dirtypages.put(newRightPage.getId(), newRightPage);
dirtypages.put(parent.getId(), parent);
updateParentPointers(tid, dirtypages, parent);
updateParentPointers(tid, dirtypages, page);
updateParentPointers(tid, dirtypages, newRightPage);
// 5. 返回 field 所在的页
// 如果当前值大于等于中点,说明在右边节点
if(field.compare(Op.GREATER_THAN_OR_EQ, mid.getKey())){
return newRightPage;
}
// 否则在左边节点,也就是原节点
return page;
}
- deleteKeyAndRightChild():删除传入的键和右指针
- 图中的原因是要分割,也就是分为两段,理应断开右指针
BufferPoll
补一下之前的错误
方法
-
insertTuple():原本是写死了HeapFile,改为DbFile
public void insertTuple(TransactionId tid, int tableId, Tuple t) throws DbException, IOException, TransactionAbortedException { // some code goes here // not necessary for lab1 // 获取 数据库文件 DBfile DbFile dbFile = Database.getCatalog().getDatabaseFile(tableId); // 将页面刷新到缓存中 updateBufferPoll(dbFile.insertTuple(tid, t), tid); } -
deleteTuple():和上面原因一样
public void deleteTuple(TransactionId tid, Tuple t) throws DbException, IOException, TransactionAbortedException { // some code goes here // not necessary for lab1 // 查询所属表对应的文件 DbFile dbFile = Database.getCatalog().getDatabaseFile(t.getRecordId().getPageId().getTableId()); // 将页面刷新到缓存中 updateBufferPoll(dbFile.deleteTuple(tid, t), tid); } -
discord():传入页中不存在缓存
public synchronized void discardPage(PageId pid) {
// some code goes here
// not necessary for lab1
// 删除使用记录
if(pageStore.containsKey(pid)){
remove(pageStore.get(pid));
// 删除缓存
pageStore.remove(pid);
}
}
- updateBufferPoll()
private void updateBufferPoll(List<Page> pageList, TransactionId tid) throws DbException {
for (Page page : pageList){
page.markDirty(true, tid);
// 如果缓存池已满,执行淘汰策略
if(pageStore.size() > numPages){
evictPage();
}
// 如果缓存中有当前节点,更新
LinkedNode node;
if(pageStore.containsKey(page.getId())){
// 获取节点,此时的页一定已经在缓存了,因为刚刚被修改的时候就已经放入缓存了
node = pageStore.get(page.getId());
// 更新新的页内容
node.page = page;
}
// 如果没有当前节点,新建放入缓存
else{
// 是否超过大小
if(pageStore.size() >= numPages){
// 使用 LRU 算法进行淘汰最近最久未使用
evictPage();
}
node = new LinkedNode(page.getId(), page);
addToHead(node);
}
// 更新到缓存
pageStore.put(page.getId(), node);
}
}
这里推荐能把这个新增节点方法抽象出来,我懒得弄了,之前忘记了
测试
BTreeFileInsertTest and BTreeDeadlockTest
Exercise 3、4
实验三的内容是删除节点
BTreeFile
方法
stealFromLeafPage
public void stealFromLeafPage(BTreeLeafPage page, BTreeLeafPage sibling,
BTreeInternalPage parent, BTreeEntry entry, boolean isRightSibling) throws DbException {
// some code goes here
//
// Move some of the tuples from the sibling to the page so
// that the tuples are evenly distributed. Be sure to update
// the corresponding parent entry.
// 1. 判断是 左兄弟 还是 右兄弟
Iterator<Tuple> iterator = isRightSibling ? sibling.iterator() : sibling.reverseIterator();
// 2. 根据兄弟节点中的数量,确定窃取的数量
int curTupleNum = page.getNumTuples();
int siblingTupleNum = sibling.getNumTuples();
int targetTupleNum = (curTupleNum + siblingTupleNum) / 2;
// 窃取到target
while(curTupleNum < targetTupleNum){
Tuple tuple = iterator.next();
sibling.deleteTuple(tuple);
page.insertTuple(tuple);
curTupleNum++;
}
// 3. 提到中间节点到原内部节点
Tuple mid = iterator.next();
entry.setKey(mid.getField(keyField));
parent.updateEntry(entry);
}
stealFromLeftInternalPage
public void stealFromLeftInternalPage(TransactionId tid, Map<PageId, Page> dirtypages,
BTreeInternalPage page, BTreeInternalPage leftSibling, BTreeInternalPage parent,
BTreeEntry parentEntry) throws DbException, TransactionAbortedException {
// some code goes here
// Move some of the entries from the left sibling to the page so
// that the entries are evenly distributed. Be sure to update
// the corresponding parent entry. Be sure to update the parent
// pointers of all children in the entries that were moved.
// 1. 确定窃取几个key
Iterator<BTreeEntry> iterator = leftSibling.reverseIterator();
int curEntryNum = page.getNumEntries();
int siblingEntryNum = leftSibling.getNumEntries();
int targetNum = (curEntryNum + siblingEntryNum) / 2;
// 2. 窃取父节点(内部节点和父节点没有重复节点)
BTreeEntry entry = iterator.next();
BTreeEntry mid = new BTreeEntry(parentEntry.getKey(), entry.getRightChild(), page.iterator().next().getLeftChild());
page.insertEntry(mid);
curEntryNum++;
// 3. 窃取左兄弟节点
while(curEntryNum < targetNum){
leftSibling.deleteKeyAndRightChild(entry);
page.insertEntry(entry);
entry = iterator.next();
curEntryNum++;
}
// 4. 更新父节点
// 从左节点删除,拉到父节点
leftSibling.deleteKeyAndRightChild(entry);
parentEntry.setKey(entry.getKey());
parent.updateEntry(parentEntry);
// 5. 更新指标
dirtypages.put(page.getId(), page);
dirtypages.put(parent.getId(), parent);
dirtypages.put(leftSibling.getId(), leftSibling);
updateParentPointers(tid, dirtypages, page);
}
stealFromRightInternalPage
public void stealFromRightInternalPage(TransactionId tid, Map<PageId, Page> dirtypages,
BTreeInternalPage page, BTreeInternalPage rightSibling, BTreeInternalPage parent,
BTreeEntry parentEntry) throws DbException, TransactionAbortedException {
// some code goes here
// Move some of the entries from the right sibling to the page so
// that the entries are evenly distributed. Be sure to update
// the corresponding parent entry. Be sure to update the parent
// pointers of all children in the entries that were moved.
// 1. 确定窃取几个key
Iterator<BTreeEntry> iterator = rightSibling.iterator();
int curEntryNum = page.getNumEntries();
int siblingEntryNum = rightSibling.getNumEntries();
int targetNum = (curEntryNum + siblingEntryNum) / 2;
// 2. 窃取父节点(内部节点和父节点没有重复节点)
BTreeEntry entry = iterator.next();
BTreeEntry mid = new BTreeEntry(parentEntry.getKey(), page.reverseIterator().next().getRightChild(), entry.getLeftChild());
page.insertEntry(mid);
curEntryNum++;
// 3. 窃取左兄弟节点
while(curEntryNum < targetNum){
rightSibling.deleteKeyAndLeftChild(entry);
page.insertEntry(entry);
entry = iterator.next();
curEntryNum++;
}
// 4. 更新父节点
// 从左节点删除,拉到父节点
rightSibling.deleteKeyAndRightChild(entry);
parentEntry.setKey(entry.getKey());
parent.updateEntry(parentEntry);
// 5. 更新指标
dirtypages.put(page.getId(), page);
dirtypages.put(parent.getId(), parent);
dirtypages.put(rightSibling.getId(), rightSibling);
updateParentPointers(tid, dirtypages, page);
}
mergeLeafPages
public void mergeLeafPages(TransactionId tid, Map<PageId, Page> dirtypages,
BTreeLeafPage leftPage, BTreeLeafPage rightPage, BTreeInternalPage parent, BTreeEntry parentEntry)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
//
// Move all the tuples from the right page to the left page, update
// the sibling pointers, and make the right page available for reuse.
// Delete the entry in the parent corresponding to the two pages that are merging -
// deleteParentEntry() will be useful here
// 1. 将右兄弟的所有节点添加到左节点
Iterator<Tuple> iterator = rightPage.iterator();
while(iterator.hasNext()){
Tuple tuple = iterator.next();
rightPage.deleteTuple(tuple);
leftPage.insertTuple(tuple);
}
// 2. 更新右兄弟
BTreePageId rightSiblingPageId = rightPage.getRightSiblingId();
if(rightSiblingPageId == null){
leftPage.setRightSiblingId(null);
}
else{
leftPage.setRightSiblingId(rightSiblingPageId);
// 右兄弟更新左兄弟
BTreeLeafPage rightSiblingPage = (BTreeLeafPage) getPage(tid, dirtypages, rightSiblingPageId, Permissions.READ_WRITE);
rightSiblingPage.setLeftSiblingId(leftPage.getId());
}
// 3. 将右兄弟在 header 中置空
setEmptyPage(tid, dirtypages, rightPage.pid.getPageNumber());
// 4. 删除父节点中的 entry
deleteParentEntry(tid, dirtypages, leftPage, parent, parentEntry);
// 5. 放到脏页缓存
dirtypages.put(leftPage.getId(), leftPage);
dirtypages.put(parent.getId(), parent);
}
mergeInternalPages
public void mergeInternalPages(TransactionId tid, Map<PageId, Page> dirtypages,
BTreeInternalPage leftPage, BTreeInternalPage rightPage, BTreeInternalPage parent, BTreeEntry parentEntry)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
//
// Move all the entries from the right page to the left page, update
// the parent pointers of the children in the entries that were moved,
// and make the right page available for reuse
// Delete the entry in the parent corresponding to the two pages that are merging -
// deleteParentEntry() will be useful here
// 1. 获取中间节点插入
BTreeEntry mid = new BTreeEntry(parentEntry.getKey(), leftPage.reverseIterator().next().getRightChild(),
rightPage.iterator().next().getLeftChild());
leftPage.insertEntry(mid);
// 2. 将右兄弟连接到左兄弟
Iterator<BTreeEntry> iterator = rightPage.iterator();
while(iterator.hasNext()){
BTreeEntry entry = iterator.next();
rightPage.deleteKeyAndLeftChild(entry);
leftPage.insertEntry(entry);
}
// 3. 更新左兄弟的孩子指针
updateParentPointers(tid, dirtypages, leftPage);
// 4. 将 rightPage 在 header中标空
setEmptyPage(tid, dirtypages, rightPage.getId().getPageNumber());
// 5. 从父节点中删除左右孩子指针
deleteParentEntry(tid, dirtypages, leftPage, parent, parentEntry);
// 6. 刷新脏页缓存
dirtypages.put(leftPage.getId(), leftPage);
dirtypages.put(parent.getId(), parent);
}
测试
BTreeFileDeleteTest.java