前言
上次说要写这个报告,半年过去了,我终于决定写lab2了。
一、关于lab2?
In this lab assignment, you will write a set of operators for SimpleDB to implement table modifications (e.g., insert and delete records), selections, joins, and aggregates. These will build on top of the foundation that you wrote in Lab1 to provide you with a database system that can perform simple queries over multiple tables.
Additionally, we ignored the issue of buffer pool management in Lab 1: we have not dealt with the problem that arises
when we reference more pages than we can fit in memory over the lifetime of the database. In Lab 2, you will design an eviction policy to flush stale pages from the buffer pool.
You do not need to implement transactions or locking in this lab.
二、lab2
1.Exercise 1
Exercise 1主要是让我们去实现两种操作符Filter和Join
- Filter: This operator only returns tuples that satisfy a that is specified as part of its constructor.
Hence, it filters out any tuples that do not match the predicate.Predicate- Join: This operator joins tuples from its two children according to a that is passed in as part of
its constructor. We only require a simple nested loops join, but you may explore more interesting join
implementations. Describe your implementation in your lab writeup.JoinPredicate
这里的Filter在我们的SQL语句中既指代where的作用,比如select * from lists where id > 1。这里有个重要的辅助类Predicate,这是用于将tuple中的字段与指定的字段进行比较,实现对单个tuple的过滤操作。在下图我们可以看到Predicate有三个重要的成员变量,其中fieldNum代表比较是tuple中哪一列数据;op是一个枚举类,代表我们的运算符,比较的逻辑有EQUALS, GREATER_THAN, LESS_THAN, LESS_THAN_OR_EQ, GREATER_THAN_OR_EQ, LIKE, NOT_EQUALS;operand代表的是要比较的那个量。
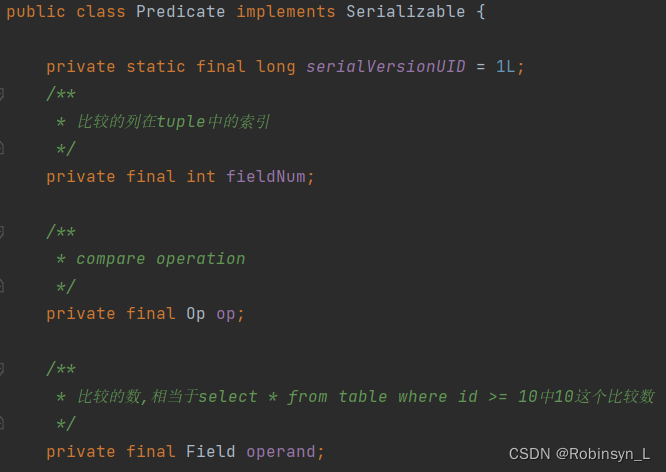
通过Predicate中的filter函数,传入我们要比较的Tuple,得到对应列的数据,通过Field中的compare 实现进行比较(以IntField为例)
//Predicate
public boolean filter(Tuple t) {
// some code goes here
boolean res = t.getField(this.fieldNum).compare(op, this.operand);
return res;
}
//IntField
public boolean compare(Predicate.Op op, Field val) {
IntField iVal = (IntField) val;
switch (op) {
case EQUALS:
case LIKE:
return value == iVal.value;
case NOT_EQUALS:
return value != iVal.value;
case GREATER_THAN:
return value > iVal.value;
case GREATER_THAN_OR_EQ:
return value >= iVal.value;
case LESS_THAN:
return value < iVal.value;
case LESS_THAN_OR_EQ:
return value <= iVal.value;
}
return false;
}
现在我们有了Predicate可以过滤单个的Tuple,那么对于整个表需要进行select * from lists where id > 1操作的时候,只需要一个迭代器即可。我们可以看到在Filter是构造函数中传入了一个迭代器,用于迭代每一行的Tuple。
public Filter(Predicate p, OpIterator child) {
// some code goes here
this.predicate = p;
this.opIterator = child;
this.tupleDesc = child.getTupleDesc();
}
Filter本身是继承Operator的,Operator实现了OpIterator接口,在next()和hasNext()中都调用了抽象方法fetchNext()。那么我们只需要实现fetchNext()即可。
protected Tuple fetchNext() throws NoSuchElementException,
TransactionAbortedException, DbException {
// some code goes here
if (opIterator == null) {
throw new NoSuchElementException("Operator Iterator is empty");
}
while (opIterator.hasNext()) {
Tuple tuple = opIterator.next();
if (predicate.filter(tuple)) return tuple;
}
return null;
}
做完Filter与Predicate的实现后,接下来做Join和JoinPredicate就变得简单了。值得注意的是,我们这里的Join是内连接。即我们要实现这样一条语句的功能:SELECT * FROM a INNER JOIN b ON a.No=b.No。不知道什么是内连接外连接的同学可以看这篇左右连接和内连接的区别
对于JoinPredicate,和Predicate类似 ,是Join的辅助类,其作用是对两个tuple中的某一字段进行比较。
//JoinPredicate
public boolean filter(Tuple t1, Tuple t2) {
// some code goes here
Field operand1 = t1.getField(fieldNum1);
Field operand2 = t2.getField(fieldNum2);
return operand1.compare(op, operand2);
}
同样接下来,我们要去实现Join的fetchNext()。这里的思路是用两个迭代器child1和child2循环获取两个表中的数据:先获取child1中的一个tuple 赋值给t,t依次与child2中的tuples进行比较,与满足连接条件的t2进行连接并返回连接后的newTuple,遍历完child2之后child2.rewind()重置,下一次外层循环t = child1.next(),
protected Tuple fetchNext() throws TransactionAbortedException, DbException {
// some code goes here
while (this.it1.hasNext() || this.t != null) {
if (this.it1.hasNext() && this.t == null) {
t = it1.next();
}
while (it2.hasNext()) {
Tuple t2 = it2.next();
if (p.filter(t, t2)) {
TupleDesc td1 = t.getTupleDesc();
TupleDesc td2 = t2.getTupleDesc();
TupleDesc newTd = TupleDesc.merge(td1, td2);
Tuple newTuple = new Tuple(newTd);
newTuple.setRecordId(t.getRecordId());
int i = 0;
for (; i < td1.numFields(); ++i)
newTuple.setField(i, t.getField(i));
for (int j = 0; j < td2.numFields(); ++j)
newTuple.setField(i + j, t2.getField(j));
if (!it2.hasNext()) {
//child1匹配到的刚好是child2的最后一条记录,
//不重置的话取出child1的下一个tuple就不是与child2的第一个tuple进行比较了)
it2.rewind();
t = null;
}
return newTuple;
}
}
//child1的其中一个tuple与child2所有tuple都不匹配
//同样不重置的话取出child1的下一个tuple就不是与child2的第一个tuple进行比较
it2.rewind();
t = null;
}
return null;
}
2.Exercise 2
Exercise 2主要是让我们实现Integer和String类型中五个支持分组的SQL聚合:GROUP BY、COUNT、SUM、AVG、MIN、MAX,其中String类型只需要实现COUNT。还是以SQL语句举例,如:select sum(money) as 总收入 from table GROUP BY xx,实验要求我们只需实现根据一个字段去分组和聚合,也就是只有一个分组字段和一个聚合字段,这里的xx就是分组字段,money就是聚合字段
IntegerAggregator中成员变量如下:
gbFieldIndex:分组字段的序号
gbFieldType:分组字段的类型
aggFieldIndex:聚合字段的序号
gbHandler:一个抽象类,其中gbResult是一个map,用于保存聚合后的结果,其key的值为分类的字段,如果不要求分类则为NO_GROUPING_KEY,其value为聚合的字段。不同实现的抽象方法handle()实现具体的操作,实现了GBHandler的类有CountHandler、SumHandler、MaxHandler、MinHandler、AvgHandler。
private abstract class GBHandler{
ConcurrentHashMap<String,Integer> gbResult;
abstract void handle(String key,Field field);
private GBHandler(){
gbResult = new ConcurrentHashMap<>();
}
public Map<String,Integer> getGbResult(){
return gbResult;
}
}
private class CountHandler extends GBHandler {
@Override
public void handle(String key, Field field) {
if(gbResult.containsKey(key)){
gbResult.put(key,gbResult.get(key)+1);
}else{
gbResult.put(key,1);
}
}
}
private class SumHandler extends GBHandler{
@Override
public void handle(String key, Field field) {
if(gbResult.containsKey(key)){
gbResult.put(key,gbResult.get(key)+Integer.parseInt(field.toString()));
}else{
gbResult.put(key,Integer.parseInt(field.toString()));
}
}
}
private class MinHandler extends GBHandler{
@Override
void handle(String key, Field field) {
int tmp = Integer.parseInt(field.toString());
if(gbResult.containsKey(key)){
int res = gbResult.get(key)<tmp?gbResult.get(key):tmp;
gbResult.put(key, res);
}else{
gbResult.put(key,tmp);
}
}
}
private class MaxHandler extends GBHandler{
@Override
void handle(String key, Field field) {
int tmp = Integer.parseInt(field.toString());
if(gbResult.containsKey(key)){
int res = gbResult.get(key)>tmp?gbResult.get(key):tmp;
gbResult.put(key, res);
}else{
gbResult.put(key,tmp);
}
}
}
private class AvgHandler extends GBHandler{
ConcurrentHashMap<String,Integer> sum;
ConcurrentHashMap<String,Integer> count;
private AvgHandler(){
count = new ConcurrentHashMap<>();
sum = new ConcurrentHashMap<>();
}
@Override
public void handle(String key, Field field) {
int tmp = Integer.parseInt(field.toString());
if(gbResult.containsKey(key)){
count.put(key,count.get(key)+1);
sum.put(key,sum.get(key)+tmp);
}else{
count.put(key,1);
sum.put(key,tmp);
}
gbResult.put(key,sum.get(key)/count.get(key));
}
}
我们现在有了分组聚合的功能,接下来只需要传入Tuple然后调用即可,如果分组类型是非法的则抛出异常,正常的话就是进行常规map操作调用handle()即可
public void mergeTupleIntoGroup(Tuple tup) {
// some code goes here
if(gbFieldType!=null&&(!tup.getField(gbFieldIndex).getType().equals(gbFieldType))){
throw new IllegalArgumentException("Given tuple has wrong type");
}
String key;
if (gbFieldIndex == NO_GROUPING) {
key = NO_GROUPING_KEY;
} else {
key = tup.getField(gbFieldIndex).toString();
}
gbHandler.handle(key,tup.getField(aggregateFieldIndex));
}
返回GBHandler中聚合结果的迭代器
public OpIterator iterator() {
// some code goes here
Map<String,Integer> results = gbHandler.getGbResult();
Type[] types;
String[] names;
TupleDesc tupleDesc;
List<Tuple> tuples = new ArrayList<>();
if(gbFieldIndex==NO_GROUPING){
types = new Type[]{
Type.INT_TYPE};
names = new String[]{
"aggregateVal"};
tupleDesc = new TupleDesc(types,names);
for(Integer value:results.values()){
Tuple tuple = new Tuple(tupleDesc);
tuple.setField(0,new IntField(value));
tuples.add(tuple);
}
}else{
types = new Type[]{
gbFieldType,Type.INT_TYPE};
names = new String[]{
"groupVal","aggregateVal"};
tupleDesc = new TupleDesc(types,names);
for(Map.Entry<String,Integer> entry:results.entrySet()){
Tuple tuple = new Tuple(tupleDesc);
if(gbFieldType==Type.INT_TYPE){
tuple.setField(0,new IntField(Integer.parseInt(entry.getKey())));
}else{
tuple.setField(0,new StringField(entry.getKey(),entry.getKey().length()));
}
tuple.setField(1,new IntField(entry.getValue()));
tuples.add(tuple);
}
}
return new TupleIterator(tupleDesc,tuples);
}
StringAggregator的实现和IntegerAggregator相似,并且Handler部分只需实现COUNT,故不再赘述。接下来只剩下Aggregate的实现了,Aggerate类就是前面两种Aggregator的封装,根据聚合字段类型的不同调用不同的Aggregator中的iterator(),返回一个结果集的迭代器。
3.Exercise 3
Exercise 3主要是实现HeapPage、HeapFile、BufferPool的插入Tuple、删除Tuple,这里是先实现单个页面HeapPage数据的增删,然后在HeapFile中只需要遍历每个页面,调用Page中方法即可,BufferPool中的实现同理,调用Database.getCatalog().getDatabaseFile(tableId)即可。
先看HeapPage中插入的实现,在开头调用了一个getNumEmptySlots()方法,通过位运算得到空slot的个数,如果没有足够的空间抛出异常,如果空间够的话,在遇见的第一个空的slot标记处标记已被使用,然后在slot对应的位置插入数据。对于删除Tuple只需将对应位置置为null,将对应的slot标记为未使用即可
public void insertTuple(Tuple t) throws DbException {
// some code goes here
// not necessary for lab1
if (getNumEmptySlots() == 0) throw new DbException("Not enough space to insert tuple");
if (!t.getTupleDesc().equals(this.td)) throw new DbException("Tuple's Description is not match for this page");
for (int i = 0; i < tuples.length; i++) {
if (!isSlotUsed(i)) {
markSlotUsed(i, true);
tuples[i] = t;
tuples[i].setRecordId(new RecordId(pid, i));
break;
}
}
}
public void deleteTuple(Tuple t) throws DbException {
// some code goes here
// not necessary for lab1
RecordId recordId = t.getRecordId();
int tupleIndex = recordId.getTupleNumber();
if (recordId != null && pid.equals(recordId.getPageId())) {
if (tupleIndex < getNumTuples() && isSlotUsed(tupleIndex)) {
tuples[tupleIndex] = null;
markSlotUsed(tupleIndex, false);
return;
}
throw new DbException("can't find tuple in the page");
}
throw new DbException("can't find tuple in the page");
}
public int getNumEmptySlots() {
// some code goes here
int res = 0;
for (int i = 0; i < numSlots; i ++ ) {
if ((header[i / 8] >> (i % 8) & 1) == 0) {
res ++;
}
}
return res;
}
/**
* Returns true if associated slot on this page is filled.
*/
public boolean isSlotUsed(int i) {
// some code goes here
int index = i / 8; //在bitmap的第几个字节中
int offset = i % 8; //在第几个字节中的偏移量
return (header[index] & (1 << offset)) != 0; //判断是否为1,即该slot是否填充
}
/**
* Abstraction to fill or clear a slot on this page.
*/
private void markSlotUsed(int i, boolean value) {
// some code goes here
// not necessary for lab1
int index = Math.floorDiv(i, 8);
byte b = header[index];
byte mask = (byte) (1 << (i % 8));
// change header's bitmap
if (value) header[index] = (byte) (b | mask);
else header[index] = (byte) (b & (~mask));
}
实现了HeapPage的插入和删除,接着实现HeapFile的遍历所有的Page找到有空slot的页面,记住所有的页面都是从BufferPool中获取的,如果BufferPool没有,它会去磁盘找。如果目前表中的所有的Page都没剩余空间,那么需要写入一个新的页面,即writePage()。删除就简单了,调用Page的删除就好了。不过为什么每次插入和删除都要返回修改page的list呢,这是为了将脏页返回,在缓冲池中进行标脏。
public List<Page> insertTuple(TransactionId tid, Tuple t)
throws DbException, IOException, TransactionAbortedException {
ArrayList<Page> list = new ArrayList<>();
BufferPool pool = Database.getBufferPool();
int tableid = getId();
for (int i = 0; i < numPages(); ++i) {
HeapPage page = (HeapPage) pool.getPage(tid, new HeapPageId(tableid, i), Permissions.READ_WRITE);
if (page.getNumEmptySlots() > 0) {
page.insertTuple(t);
page.markDirty(true, tid);
list.add(page);
return list;
}
}
HeapPage page = new HeapPage(new HeapPageId(tableid, numPages()), HeapPage.createEmptyPageData());
page.insertTuple(t);
writePage(page);
list.add(page);
return list;
}
public ArrayList<Page> deleteTuple(TransactionId tid, Tuple t) throws DbException,
TransactionAbortedException {
// some code goes here
ArrayList<Page> list = new ArrayList<>();
HeapPage page = (HeapPage) Database.getBufferPool().getPage(tid, t.getRecordId().getPageId(), Permissions.READ_WRITE);
page.deleteTuple(t);
list.add(page);
return list;
// not necessary for lab1
}
public void writePage(Page page) throws IOException {
// some code goes here
int pageNumber = page.getId().getPageNumber();
if (pageNumber > numPages()) {
throw new IllegalArgumentException("page is not in the heap file or page'id in wrong");
}
RandomAccessFile randomAccessFile = new RandomAccessFile(file, "rw");
randomAccessFile.seek(pageNumber * BufferPool.getPageSize());
byte[] pageData = page.getPageData();
randomAccessFile.write(pageData);
randomAccessFile.close();
// not necessary for lab1
}
最后实现BufferPool中的插入和删除,通过databaseFile.insertTuple(tid, t)得到了修改的脏页,调用markDirty进行标脏操作,这里的lruCache.put(page.getId(), page)是接下来实验实现的LRU缓存的流程。删除操作同理。
public void insertTuple(TransactionId tid, int tableId, Tuple t)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
// List<Page> pageList = Database.getCatalog().getDatabaseFile(tableId).insertTuple(tid, t);
// for (Page page : pageList) {
// addToBufferPool(page.getId(), page);
// }
// not necessary for lab1
DbFile databaseFile = Database.getCatalog().getDatabaseFile(tableId);
//System.out.println(tid.getId());
List<Page> pages = databaseFile.insertTuple(tid, t);
//System.out.println(tid.getId());
for (Page page : pages) {
//用脏页替换buffer中现有的页
page.markDirty(true, tid);
lruCache.put(page.getId(), page);
}
}
public void deleteTuple(TransactionId tid, Tuple t)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
// DbFile dbFile = Database.getCatalog().getDatabaseFile(t.getRecordId().getPageId().getTableId());
// dbFile.deleteTuple(tid, t);
// not necessary for lab1
DbFile dbFile = Database.getCatalog().getDatabaseFile(t.getRecordId().getPageId().getTableId());
List<Page> pages = dbFile.deleteTuple(tid, t);
for (int i = 0; i < pages.size(); i++) {
pages.get(i).markDirty(true, tid);
}
}
4.Exercise 4
Exercise 4是要求Insert和Delete两个操作符,有了Exercise 3的插入和删除这里就很简单了,和Exercise 1类似,Insert继承了Operator,我们只需要实现fetchNext()就好了,返回的字段是我们插入的个数,这里的state是为了避免重复重复调用。Delete的实现类似,不再赘述。
//Insert
protected Tuple fetchNext() throws TransactionAbortedException, DbException {
// some code goes here
if (state) return null;
Tuple t = new Tuple(this.td);
int cnt = 0;
BufferPool bufferPool = Database.getBufferPool();
while (child.hasNext()) {
try {
bufferPool.insertTuple(tid, this.tableID, child.next());
} catch (IOException e) {
throw new DbException("fail to insert tuple");
}
cnt++;
}
t.setField(0, new IntField(cnt));
state = true;
return t;
}
5.Exercise 5
实现一个页面淘汰策略,网上这个实验大家都是实现的LRU,思路很简单,一个双端链表加一个map即可解决
public class LRUCache<K,V> {
class DLinkedNode {
K key;
V value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {
}
public DLinkedNode(K _key, V _value) {
key = _key; value = _value;}
}
private Map<K, DLinkedNode> cache = new ConcurrentHashMap<K, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
head.prev = tail;
tail.prev = head;
tail.next = head;
}
public int getSize() {
return size;
}
public DLinkedNode getHead() {
return head;
}
public DLinkedNode getTail() {
return tail;
}
public Map<K, DLinkedNode> getCache() {
return cache;
}
//必须要加锁,不然多线程链表指针会成环无法结束循环。在这卡一天
public synchronized V get(K key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return null;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public synchronized void remove(DLinkedNode node){
node.prev.next = node.next;
node.next.prev = node.prev;
cache.remove(node.key);
size--;
}
public synchronized void discard(){
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
size--;
}
public synchronized void put(K key, V value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
总结
今天导师发消息让过完大年返校了,拖了半年的实验报告也重新启动,当然下一篇报告什么时候写就不一定了,提前预告下一篇写lab4,lab3我没有做,因为这部分内容是让去实现一个解析优化,我不想在这方面涉入太深,不然这个方向学着学着不就成数据库开发工程师了,然后去搞分布式存储什么的哈哈哈哈。