K-means++聚类算法
前言
K-means++算法:K-means++算法是K-means算法的改进版,其在选择初始质心时采用了一种更加聪明的方法,能够有效地避免局部最优解。具体来说,K-means++算法的初始质心是根据距离数据点最远的原则来选择的,这样可以保证初始质心的分布更加广泛,从而使得算法更容易找到全局最优解。
K-means算法链接: https://blog.csdn.net/qq_40276082/article/details/130231301?spm=1001.2014.3001.5501
一、算法简介
k-means++ 是一种改进的 k-means 聚类算法,它可以更好地初始化聚类中心,从而提高聚类结果的准确性和稳定性。
在 k-means 中,初始的聚类中心通常是随机选择的,这可能会导致聚类结果不稳定,因为聚类中心的位置可能会影响最终的聚类结果。k-means++ 算法通过一种启发式的方式选择初始聚类中心,使得它们彼此之间的距离更远,从而提高聚类结果的准确性和稳定性。
二、K-means++算法步骤
K-means++算法的操作步骤如下:
1.从数据集中随机选择一个数据点作为第一个质心。
2.对于每个数据点x,计算它与已选取的质心中距离最近的距离D(x),并将D(x)的值累加起来得到一个累积距离S。
3.从剩余的数据点中随机选择一个数据点y,使得每个数据点被选中的概率与它与已选取的质心中距离最近的距离的平方成正比,即P(y) = D(y)^2 / S。这样选择的质心距离已选取的质心较远,从而保证了初始质心的分布更加广泛。
4.重复步骤2和步骤3,直到选取k个质心为止。
5.运行K-means算法,将数据点分配到最近的质心,并更新质心的位置。
6.重复运行步骤5,直到质心的位置不再改变或达到最大迭代次数。
三、K-means++算法matlab实现
% 生成数据
X = [randn(100,2); randn(100,2)+5; randn(100,2)+10];
%聚类种类
K = 3;
max_iters = 10;
centroids = init_centroids(X, K);
% 迭代更新簇分配和簇质心
for i = 1:max_iters
% 簇分配
labels = assign_labels(X, centroids);
% 更新簇质心
centroids = update_centroids(X, labels, K);
end
% 绘制聚类结果
colors = ['r', 'g', 'b'];
figure;
hold on;
for i = 1:K
plot(X(labels == i, 1), X(labels == i, 2), [colors(i) '*']);
plot(centroids(i, 1), centroids(i, 2), [colors(i) 'o'], 'MarkerSize', 10, 'LineWidth', 3);
end
title('K-means++ ');
legend('类别1', '质心1', '类别 2', '质心 2', '类别 3', '质心 3');
hold off;
% 初始化簇质心函数
function centroids = init_centroids(X, K)
% 随机选择一个数据点作为第一个质心
centroids = X(randperm(size(X, 1), 1), :);
% 选择剩余的质心
for i = 2:K
D = pdist2(X, centroids, 'squaredeuclidean');
D = min(D, [], 2);
D = D / sum(D);
centroids(i, :) = X(find(rand < cumsum(D), 1), :);
end
end
% 簇分配函数
function labels = assign_labels(X, centroids)
[~, labels] = min(pdist2(X, centroids, 'squaredeuclidean'), [], 2);
end
% 更新簇质心函数
function centroids = update_centroids(X, labels, K)
centroids = zeros(K, size(X, 2));
for i = 1:K
centroids(i, :) = mean(X(labels == i, :), 1);
end
end
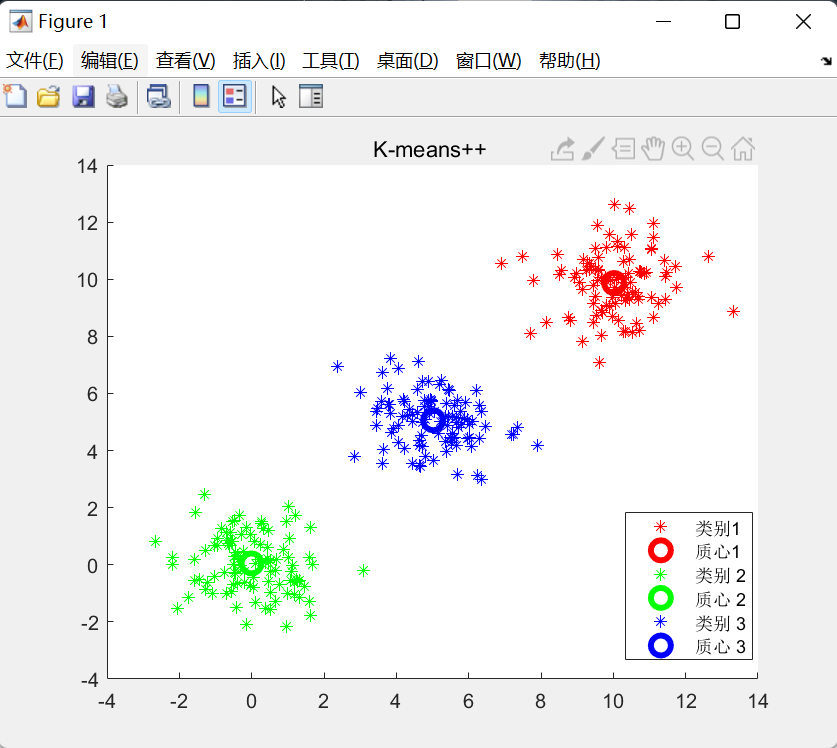
运行结果:
总结
K-means++算法的核心思想是选择初始质心时考虑数据点之间的距离,使得初始质心的分布更加广泛,从而避免了K-means算法的局部最优解问题。实践证明,K-means++算法的聚类效果优于K-means算法,特别是在较大的数据集上。
需要注意的是,K-means++算法的计算复杂度较高,因为需要计算每个数据点与已选取的质心中距离最近的距离,而这个计算是O(kn)的,其中k是簇的数量,n是数据点的数量。因此,在实际应用中需要根据数据集的大小和计算资源的限制进行调整和优化