一、准备工作
1、数据准备
所使用的数据是TSA包中的co2数据,如果没有这个包的话,可以先装一下
install.packages("TSA") # 安装包 TSA
会有让你选镜像的过程,随便选就行了。下载好之后,导入并查看数据
library(TSA)
data(co2)
win.graph(width = 4.875,height = 3,pointsize = 8)
plot(co2,ylab='CO2') #绘制原始数据

可以看到,原始数据明显有一个向上的趋势和一个周期趋势。
2、基本概念
赤池信息准则(Akaike’s(1973) Information Criterion, AIC)是建立在熵的概念基础上,可以权衡所估计模型的复杂度和此模型拟合数据的优良性。
A I C = − 2 l o g ( 极 大 似 然 估 计 值 ) + 2 k AIC=-2log(极大似然估计值)+2k AIC=−2log(极大似然估计值)+2k
其中,如果模型包含截距或常数项,那么k=p+q+1;否则k=p+q。AIC越小越好。
Ljung-Box检验即LB检验、随机性检验,用来检验m阶滞后范围内序列的自相关性是否显著,或序列是否为白噪声(或者统计量服从自由度为m的卡方分布)。若是白噪声数据,则该数据没有价值提取,即不用继续分析了。
二、数据处理

拿到一个序列之后,首先判断它是不是平稳时间序列,如果是就进行模式识别;如果不是就扣除趋势项将其变成一个平稳时间序列。接着做模式识别、参数估计、模型诊断和预测。
ps: 这是从老师课件上找的流程图,个人感觉模式识别部分,不应包含参数
d,因为含有d的一般是ARIMA(p,d,q)模型,它是非平稳模型,而上一步已将非平稳时间序列转成平稳时间序列了,d应该是在上一步确认的。也有可能是,扣除趋势项和模式识别的界限根本不可能分那么细,但是又要用流程图表示出来,所以才这么写的。
1、模式识别
一般来讲,模式识别就是判别出ARIMA(p,d,q)中的各阶数p,d,q。模式识别常用的方法有:acf, pacf, eacf
首先来看它的自相关函数
acf(as.vector(co2),lag.max = 36) #自相关函数
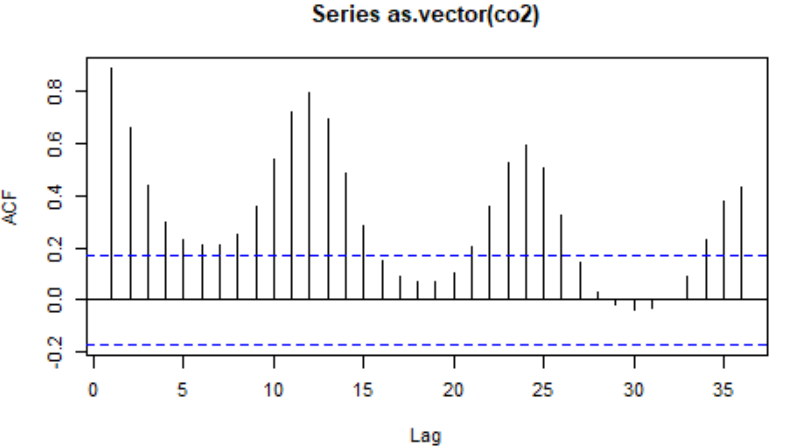
季节自相关关系十分显著:在滞后12,24,36,……上表现出很强的相关性。
plot(diff(co2),ylab='1st Diff. of CO2',xlab='Year') #一次差分,消除整体上升趋势

可以看到,经过一次差分后,序列中的整体上升趋势已经消除。再来看其样本自相关函数
acf(as.vector(diff(co2)),lag.max = 36) #一次差分后的自相关函数

一次差分后,序列中仍存在强烈的季节性;应用季节差分法应该可以得到更为简约的模型。
plot(diff(diff(co2),lag=12),xlab='Year',ylab='1st & seasonal Diff.')

绘制其自相关函数
acf(as.vector(diff(diff(co2),lag=12)),lag.max=36,ci.type='ma')

可以看到,经过一次差分和季节差分后的时间序列已经消除了季节性的大部分影响。根据样本自相关函数可以看到,除了在滞后1和12上具有自相关性外,经一次和季节差分后的序列几乎不再具有自相关性,所建模型只需要在滞后1和12上具有自相关性即可。
综上,考虑构建乘法季节 A R I M A ( 0 , 1 , 1 ) × ( 0 , 1 , 1 ) 12 ARIMA(0,1,1)\times (0,1,1)_{12} ARIMA(0,1,1)×(0,1,1)12模型。
2、参数估计
模型建立后,需要估计模型的参数。乘法季节ARIMA模型只是一般ARIMA模型的特例。
m1.co2=arima(co2,order=c(0,1,1),seasonal=list(order=c(0,1,1),period=12))
print(m1.co2)
-------------------------------------------
Coefficients:
ma1 sma1
-0.5792 -0.8206
s.e. 0.0791 0.1137
sigma^2 estimated as 0.5446: log likelihood = -139.54, aic = 283.08
上面第一行代码便得到了参数的极大似然估计值,参数估值的标准差为0.5446,对数似然值为-139.54,AIC=283.08。模型的参数估值均为高度显著,进而将对该模型加以检验。
ps:为什么能根据这些指标值说明参数估值高度显著,标准是多少?
3、诊断性检验
1 残差序列
首先观察残差的时间序列图
plot(window(rstandard(m1.co2),start=c(1995,2)),ylab='Standardized Resi.',type='o');
abline(h=0)

除了序列中间存在某些异常行为外,残差图中并没有表明模型有任何主要的不规则性。然后对残差的样本自相关函数进一步观察
acf(as.vector(window(rstandard(m1.co2),start=c(1995,2))),lag.max=36)

统计上显著的相关系数位于滞后22,其值仅为-0.194,相关性非常小,且滞后22上的依赖关系难以给出合理的解释。除了滞后22处的边缘显著以外,该模型似乎已捕捉到了序列中依赖关系的本质。
注:在
acf前打个
2 Ljung-Box 检验
下面进行Ljung-Box检验:
win.graph(width=3,height =3,pointsize = 8)
hist(window(rstandard(m1.co2),start=c(1995,2)),xlab='Standardized Resi.',ylab='Frequency')
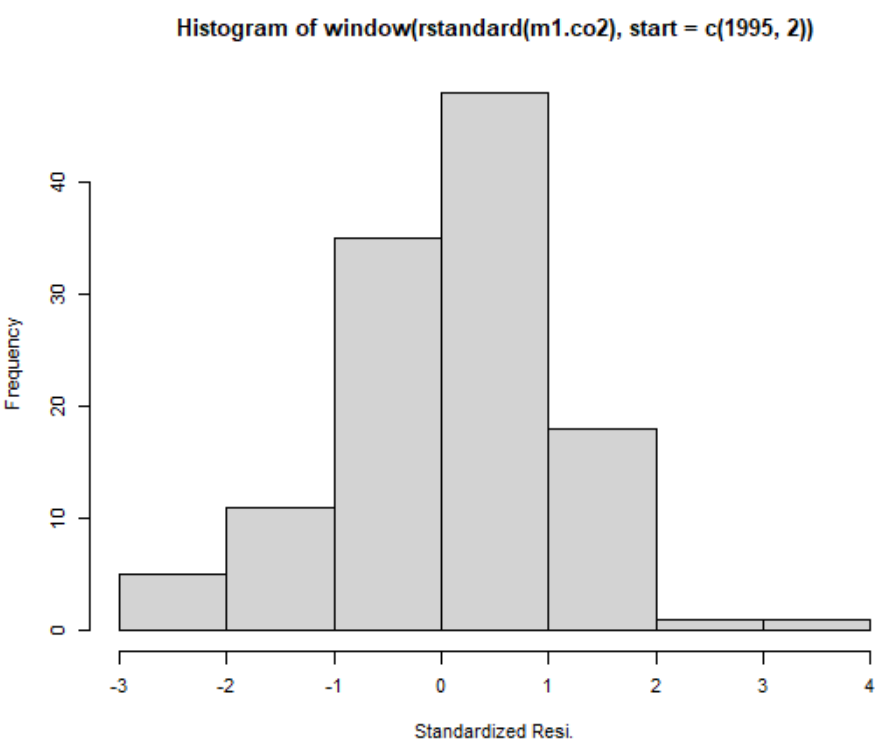
直方图的形状像钟形,但并不标准。对模型进行Ljung-Box检验,给出自由度为22的x=25.59, p=0.27,表明该模型已捕获时间序列中的依赖关系。
why?
R 语言进行 Ljung-Box 检验的函数如下:
Box.test(x, lag = 1, type = c("Box-Pierce", "Ljung-Box"), fitdf = 0)
- x: 一个时间序列,残差检验时,一般是残差
- lag: 基于自相关因子得出的lag值
- type: Ljung-Box 检验就设置为 Ljung-Box
- fitdf: 如果x是一系列残差,则需要减去自由度。
调用函数后,我们关心的就是p值,如果p > 0.05,则说明是白噪声序列,是纯随机性序列。否则数据不是白噪声,具有研究价值。
示例如下:
x <- rnorm (100)
Box.test(x, lag = 5)
Box.test(x, lag = 10, type = "Ljung")
a=Box.test(resid(m1.xpole),type="Ljung",lag=20,fitdf=11)
接着绘制分位数-分位数图(qq图)
win.graph(width=5,height =5,pointsize = 8)
qqnorm(window(rstandard(m1.co2),start=c(1995,2)))
abline(c(0,0),c(1,1),col='red')

QQ 图的上尾部,再次出现了一个异常值。但是,Shapiro-Wilk正态性检验给出的统计量W=0.982,进而得到p=0.11,且在任何显著水平上正态性都未被拒绝。
作为对模型的进一步检验,考虑用 A R I M A ( 0 , 1 , 2 ) × ( 0 , 1 , 1 ) 12 ARIMA(0,1,2)\times (0,1,1)_{12} ARIMA(0,1,2)×(0,1,1)12模型进行过度拟合。
m2.co2=arima(co2,order=c(0,1,2),seasonal=list(order=c(0,1,1),period=12))
print(m1.co2)
print(m2.co2)
--------------------------------
arima(x = co2, order = c(0, 1, 1), seasonal = list(order = c(0, 1, 1), period = 12))
Coefficients:
ma1 sma1
-0.5792 -0.8206
s.e. 0.0791 0.1137
sigma^2 estimated as 0.5446: log likelihood = -139.54, aic = 283.08
--------------------------------
arima(x = co2, order = c(0, 1, 2), seasonal = list(order = c(0, 1, 1), period = 12))
Coefficients:
ma1 ma2 sma1
-0.5714 -0.0165 -0.8274
s.e. 0.0897 0.0948 0.1224
sigma^2 estimated as 0.5427: log likelihood = -139.52, aic = 285.05
可以看到, θ 1 \theta_1 θ1和 θ \theta θ的估计变化很小(考虑标准差的大小时)。新参数 θ 2 \theta_2 θ2的估值在统计上与零无异。AIC 已经增加的情况下,sigma^2和对数似然值均无显著变化。所以使用 A R I M A ( 0 , 1 , 2 ) × ( 0 , 1 , 1 ) 12 ARIMA(0,1,2)\times (0,1,1)_{12} ARIMA(0,1,2)×(0,1,1)12模型是过度拟合,根据“奥卡姆剃刀原理”,如无必要,勿增实体。所以使用 A R I M A ( 0 , 1 , 1 ) × ( 0 , 1 , 1 ) 12 ARIMA(0,1,1)\times (0,1,1)_{12} ARIMA(0,1,1)×(0,1,1)12模型即可。
4、预测
前置时间设为2年,进行预测2年并绘制预测值与预测极限。
win.graph(width = 4.875,height = 3,pointsize = 8)
plot(m1.co2,n1=c(2003,1),nahead=24,xlab='Year',type='o',ylab='CO2 Levels')

前置时间设为1年,进行预测4年并绘制预测值与预测极限。
win.graph(width = 4.875,height = 3,pointsize = 8)
plot(m1.co2,n1=c(2004,1),n.ahead=48,xlab='Year',type='b',ylab='CO2 Levels')

ps: 上面参数的含义,n1=c(2004,1)代表从2004年1月开始(实际数据到2005年12月结束),n.ahead=48代表预测48个值(一年12个值,所以是4年)