14.图搜索
不知情vs知情搜索
不知情搜索算法不提供任何关于目标位置的信息,因此盲目搜索。不同的非知情算法之间的唯一区别是它们展开节点的顺序。下面列出了几种不同类型的不知情算法:
---Breadth-first Search广度优先搜索
---Depth-first Search深度优先搜索
---Uniform Cost Search成本一致搜索
另一方面,知情搜索提供了与目标位置有关的信息。因此,这些搜索算法能够评估一些节点比其他节点更有希望。这使得他们的搜索更有效率。这节课要学习的知情算法是,
---A *搜索
上述搜索存在几种变体,并将简要讨论。
15.术语
用来描述算法的两个主要术语——完整性和最优性。
算法的时间复杂度评估算法生成路径所需的时间,通常与当前节点或维度的数量有关。它也可以指算法的质量(例如完整性)与计算时间之间的权衡。
算法的空间复杂度评估执行搜索需要多少内存。一些算法必须在整个运行期间在内存中保留大量的信息,而其他算法可以只保留很少的信息。
算法的通用性考虑的是该算法可以解决的问题类型——它是局限于非常特定的问题类型,还是该算法在广泛的问题中表现良好?
在学习每种搜索算法时,请记住这些概念!
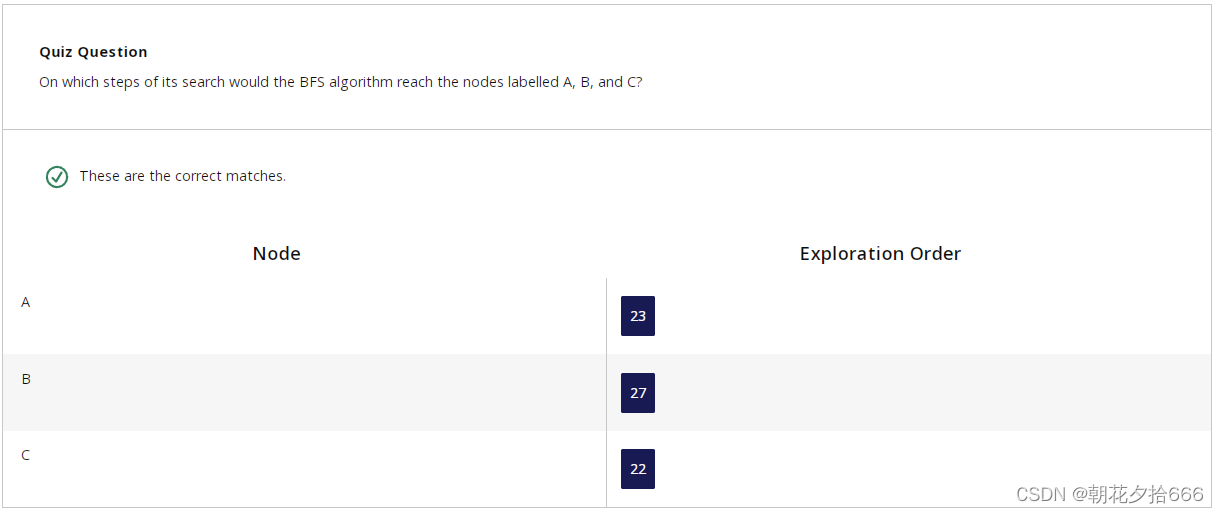
16.Breadth-First Search广度优先搜索


17.Depth-First Search深度优先搜索


18.Uniform Cost Search成本一致搜索


 19.A* Search
19.A* Search
A*搜索使用优先级队列对边界进行排序,由f(n)排序,即路径代价和启发式函数的和。这是非常有效的,因为它要求搜索在朝着目标前进的同时保持路径短。然而,正如你可能在测试中发现的那样,A*搜索并不一定是最优的。让我们看看为什么会这样!
如果满足以下条件,A*搜索将找到最优路径:
——每条边的代价都必须大于某个值ε,否则,搜索就会陷入无限循环,搜索就不会完成。
——启发式函数必须一致。这意味着它必须服从三角形不等式定理。也就是说,对于三个相邻点(x_1, x_2, x_3), x_1到x_3的启发式值必须小于x_1到x_2和x_2到x_3的启发式值之和。
启发式函数必须是可容许的。这意味着h(n)必须总是小于或等于从每个节点达到目标的真实代价。换句话说,h(n)绝不能高估真实的路径代价。
要了解可容许条款的来源,请看下图。假设有两条通往目标的路径,其中一条是最优路径(高亮显示的路径),另一条不是(较低的路径)。这两种启发式方法都高估了路径代价。从一开始,在边界上有四个节点,但节点N会首先展开,因为它的h(N)是最小的——它等于62。从这里开始,目标节点被添加到边界-代价为23 + 37 = 60。这个节点看起来比节点P更有希望,后者的h(n)等于63。在这种情况下,A *找到了一条不是最优的通往目标的路径。如果启发式从来没有高估真实成本,这种情况就不会发生,因为节点P看起来比节点N更有希望,并且首先被探索。

正如在上图中看到的,可接受性是A *最优的要求。出于这个原因,常见的启发式包括从节点到目标的欧几里得距离,或者在某些应用程序中是曼哈顿距离。当比较两种不同类型的值时——例如,如果路径代价以小时为单位测量,但启发式函数估计距离——那么您需要确定一个缩放参数,以便能够以一种有用的方式将两者相加。
如果你有兴趣了解更多关于启发式的知识,请访问斯坦福网站上Amit的启发式指南:Amit’s Heuristics Guide http://theory.stanford.edu/~amitp/GameProgramming/Heuristics.html。
虽然A*在大多数情况下是一种更有效的搜索,但在某些环境下,它不会胜过其他搜索算法。如果到达目标的路径恰好首先朝相反的方向走,就会发生这种情况。
A*搜索的变体存在——一些适应在动态环境中使用A*搜索,而另一些则帮助A*在大型环境中变得更易于管理。
额外的资源
下面的可视化是一个很好的工具,允许绘制自己的障碍物,设置自己的规则,并使用不同的算法执行搜索。
寻径可视化 https://qiao.github.io/PathFinding.js/visual/
关于A*变体的更多信息,请查看:MovingAI A*变体 https://movingai.com/astar-var.html
A*变体-斯坦福 http://theory.stanford.edu/~amitp/GameProgramming/Variations.html
花点时间来研究A*对BFS在不同场景下的效率!如果你觉得特别冒险,可以研究模拟中提供的其他一些算法,并将它们的结果与BFS & A*的结果进行比较。

20.关于搜索的总体关注
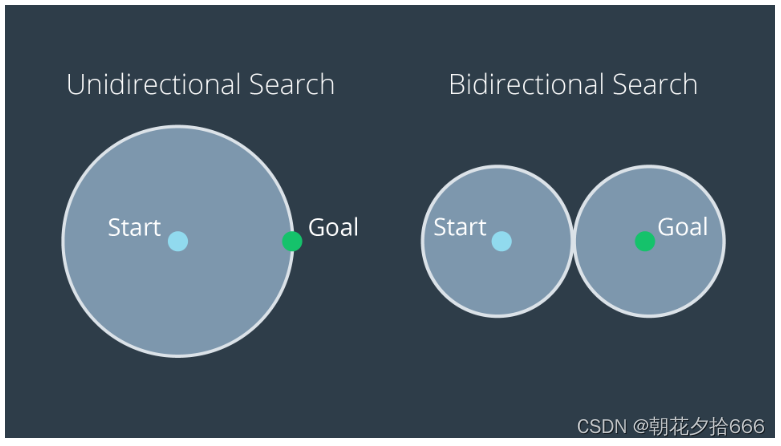
双向搜索
提高搜索效率的一种方法是同时进行两个搜索——一个在开始节点,另一个在目标节点。一旦两个搜索满足,就会在开始节点和目标节点之间存在一条路径。
这种方法的优点是减少了作为搜索的一部分需要扩展的节点数量。正如您在下面的图像中所看到的,对于同一个问题,单向搜索所扫出的体积明显大于双向搜索所扫出的体积。
路径与障碍物的距离
离散化空间搜索的另一个关注点包括最终路径与障碍物或其他危险的接近性。当使用单元格分解等方法离散空间时,空单元格不会彼此区分。最优路径通常会让机器人非常接近障碍物。在某些情况下,这可能是相当有问题的,因为由于机器人定位的不确定性,它将增加碰撞的机会。最优路径不一定是最佳路径。为了避免这种情况,可以在应用搜索之前对地图进行“平滑”,在障碍物附近标记单元格,其成本高于自由单元格。然后,A*搜索找到的路径可能会通过一些额外的清除障碍。
对齐到网格的路径
离散化空间的另一个问题是,生成的路径将沿着离散单元格。当机器人在现实世界中执行路径时,看到机器人在房间中曲折地前进,而不是沿着房间的对角线前进,这似乎很有趣。在这种情况下,在离散化空间中最优的路径在现实世界中可能是次优的。一些小心的路径平滑,注意障碍物的位置,可以解决这个问题。