文章目录
参考资料:
小破站最好的Transformer教程
台大李宏毅21年机器学习课程 self-attention和transformer
【Transformer模型】曼妙动画轻松学,形象比喻贼好记
一个新的简单的网络架构Transformer,它完全基于注意机制,完全摒弃了递归和卷积。
一、认识Transformer
基于seq2seq架构的transformer模型可以完成NLP领域研究的典型任务;如机器翻译,文本生成等。同时又可以构建预训练语言模型,用于不同任务的迁移学习。
在接下来的架构分析中,我们将假设使用Transformer模型架构处理从一种语言文本到另一种语言文本的翻译工作,因此很多命名方式遵循NLP中的规则。比如: Embeddding层将称作文本嵌入层, Embedding层产生的张量称为词嵌入张量,它的最后一维将称作词向量等。
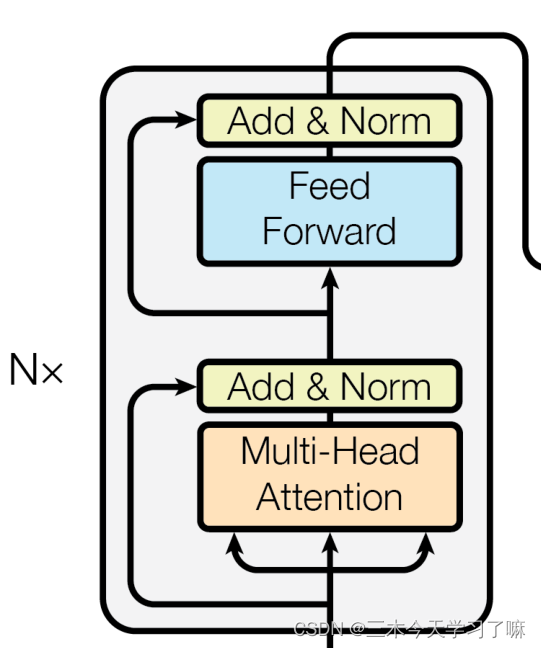
Transformer总体架构可分为四个部分:输入部分、输出部分、编码器部分、解码器部分。
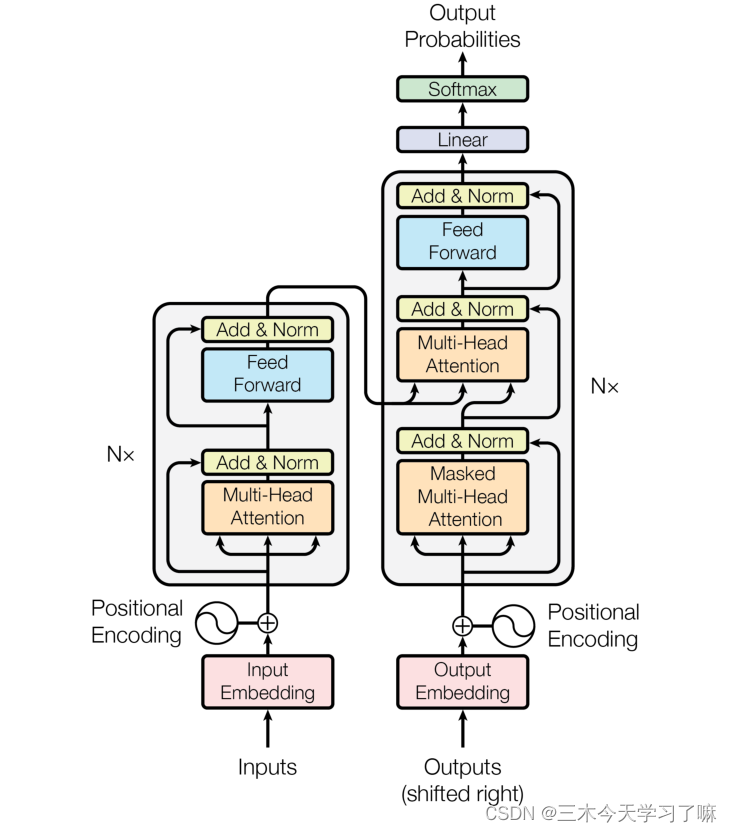
二、输入部分
- 输入部分包含:
源文本嵌入层 及其 位置编码器
目标文本嵌入层 及其 位置编码器
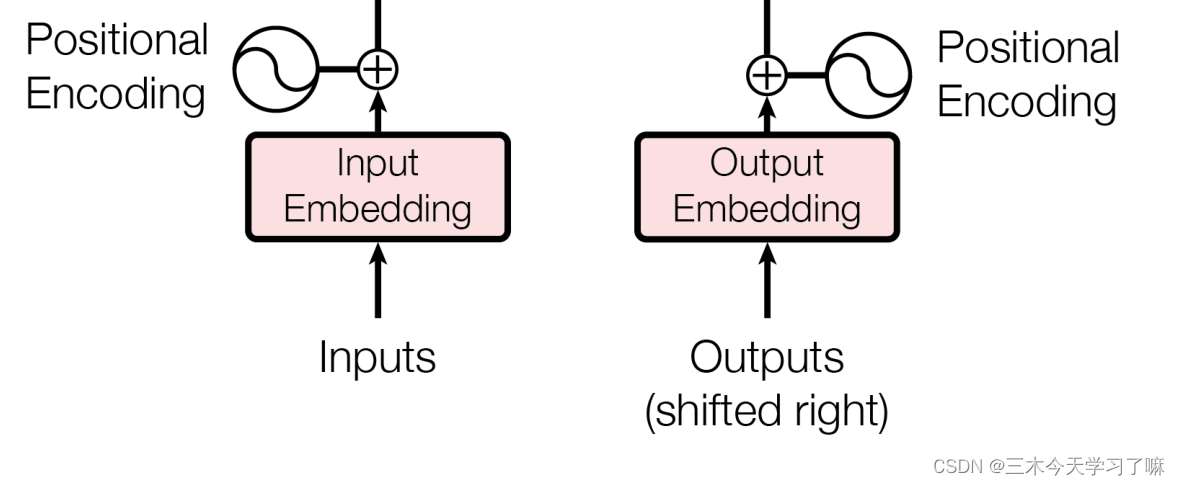
- 文本嵌入层的作用:
无论是源文本嵌入还是目标文本嵌入,都是为了将文本中词汇的数字表示转变为向量表示,希望在这样的高维空间捕捉词汇间的关系。 - 位置编码器的作用:
因为在Transformer的编码器结构中,并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失。
三、编码器部分
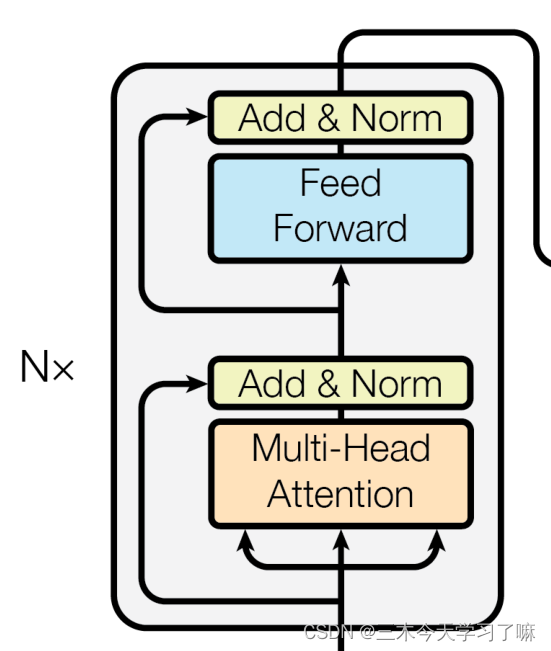
- 编码器部分:
由N个编码器层堆叠而成
每个编码器层由两个子层连接结构组成
第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
3.1 掩码张量
- 什么是掩码张量:
掩代表遮掩,码就是我们张量中的数值,它的尺寸不定,里面一般只有1和0的元素,代表位置被遮掩或者不被遮掩,至于是0位置被遮掩还是1位置被遮掩可以自定义,因此它的作用就是让另外一个张量中的一些数值被遮掩,也可以说被替换,它的表现形式是一个张量。 - 掩码张量的作用:
在Transformer中, 掩码张量的主要作用在应用attention时,有一些生成的attention张量中的值计算有可能已知了未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性 进行Embedding,但是理论上解码器的的输出却不是一次就能产生最终结果的,而是一次次通过。 上一次结果综合得出的,因此,未来的信息可能被提前利用。所以,我们会进行遮掩。
3.2 注意力机制
- 注意力:
我们观察事物时,之所以能够快速判断一种事物,是因为我们大脑能够很快把注意力放在事物最具有辨识度的部分从而作出判断,而并非是从头到尾的观察一遍事物后,才能有判断结果.正是基于这样的理论,就产生了注意力机制。 - 注意力计算规则:
它需要三个指定的输入Q(query),K(key),V(value),然后通过公式得到注意力的计算结果,这个结果代表query在key和value作用下的表示。而这个具体的计算规则有很多种,我这里只介绍我们用到的这一种。
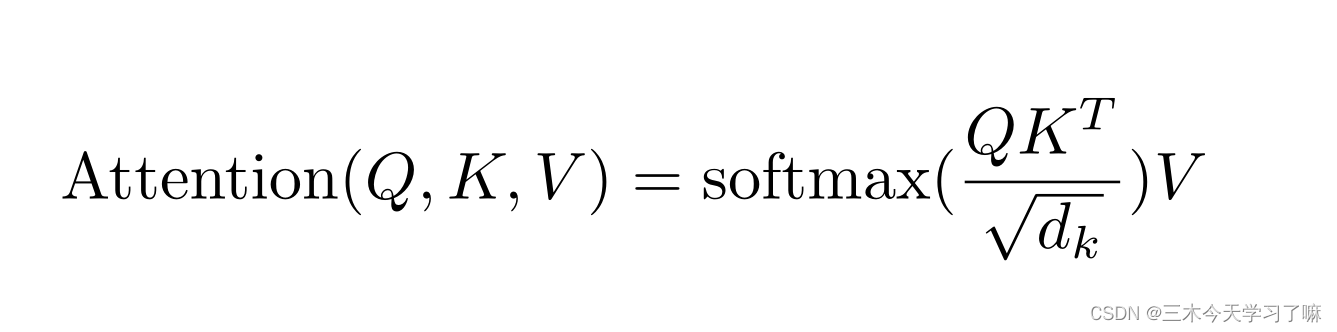
学习了Q, K, V的比喻解释:Q是一段准备被概括的文本;K是给出的提示;V是大脑中的对提示K的延伸。当Q=K=V时,称作自注意力机制。
- 注意力机制:
注意力机制是注意力计算规则能够应用的深度学习网络的载体,除了注意力计算规则外,还包括一些必要的全连接层以及相关张量处理,使其与应用网络融为一体。使用自注意力计算规则的注意力机制称为自注意力机制。
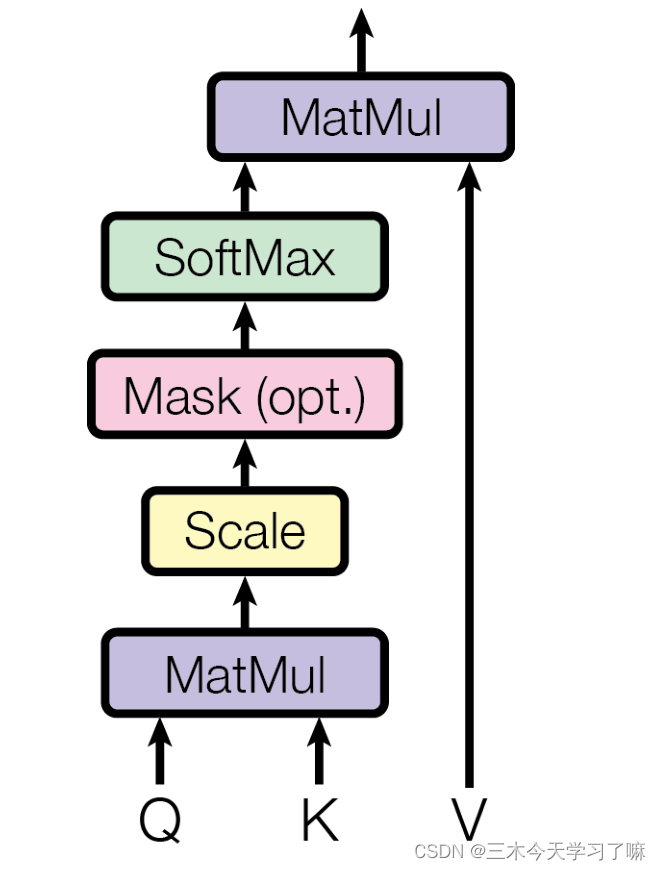
3.3 多头注意力机制
- 多头注意力机制:
从多头注意力的结构图中,貌似这个所谓的多个头就是指多组线性变换层,其实并不是,我只有使用了一组线性变化层,即三个变换张量对Q,K,V分别进行线性变换,这些变换不会改变原有张量的尺寸,因此每个变换矩阵都是方阵,得到输出结果后,多头的作用才开始显现,每个头开始从词义层面分割输出的张量,也就是每个头都想获得一组Q, K, V进行注意力机制的计算,但是句子中的每个词的表示只获得一部分, 也就是只分割了最后一维的词嵌入向量。这就是所谓的多头,将每个头的获得的输入送到注意力机制中,就形成多头注意力机制。
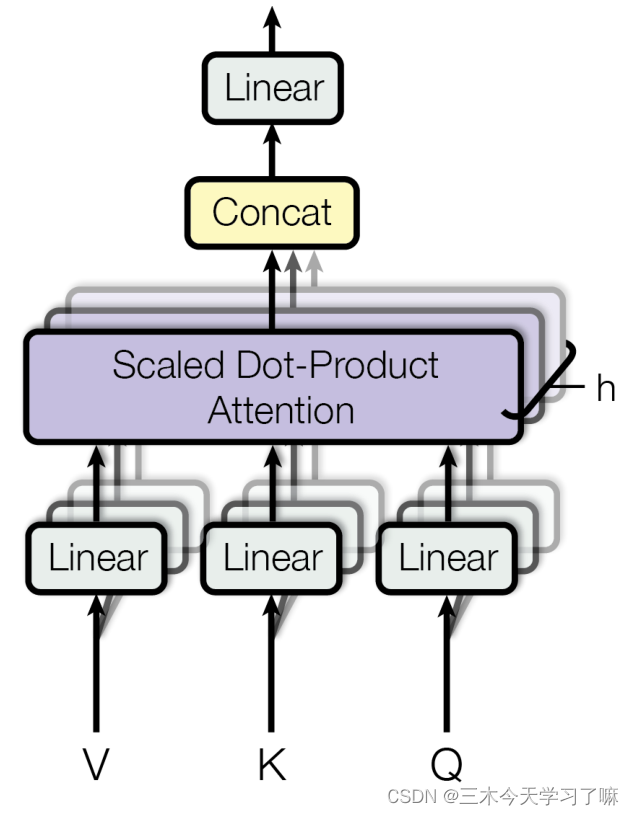
- 多头注意力机制的作用:
这种结构设计能让每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达,实验表明可以从而提升模型效果。
3.4 前馈全连接层
- 前馈全连接层:
在Transforrher中前馈全连接层就是具有两层线性层的全连接网络。 - 前馈全连接层的作用:
考虑注意力机制可能对复杂过程的拟合程度不够,通过增加两层网络来增强模型的能力。
3.5 规范化层
- 规范化层的作用: 类似batchnormalization
它是所有深层网络模型都需要的标准网络层,因为随着网络层数的增加,通过多层的计算后参数可能开始出现过大或过小的情况,这样可能会导致学习过程出现异常,模型可能收敛非常的慢.因此都会在一定层数后接规范化层进行数值的规范化,使其特征数值在合理范围内。
3.6 残差连接
- 残差连接:
如图所示,输入到每个子层以及规范化层的过程中,还使用了残差连接,因此我们把这一部分结构整体叫做子层连接(代表子层及其链接结构),在每个编码器层中,都有两个子层,这两个子层加上周围的链接结构就形成了两个子层连接结构。
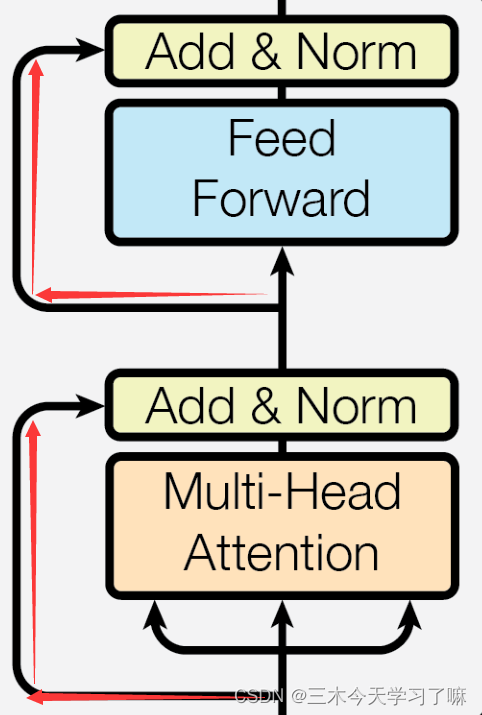
3.7 编码器层
- 编码器层的作用:
作为编码器的组成单元,每个编码器层完成一次对输入的特征提取过程,即编码过程。
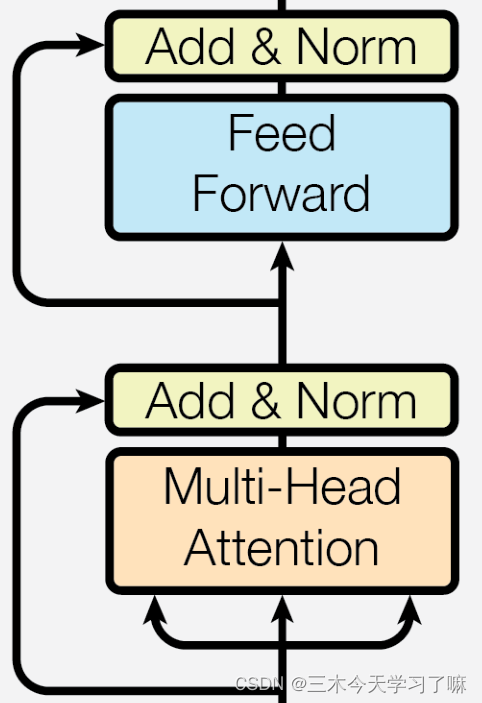
3.8 编码器
- 编码器的作用:
编码器用于对输入进行指定的特征提取过程也称为编码,由N个编码器层堆叠而成。
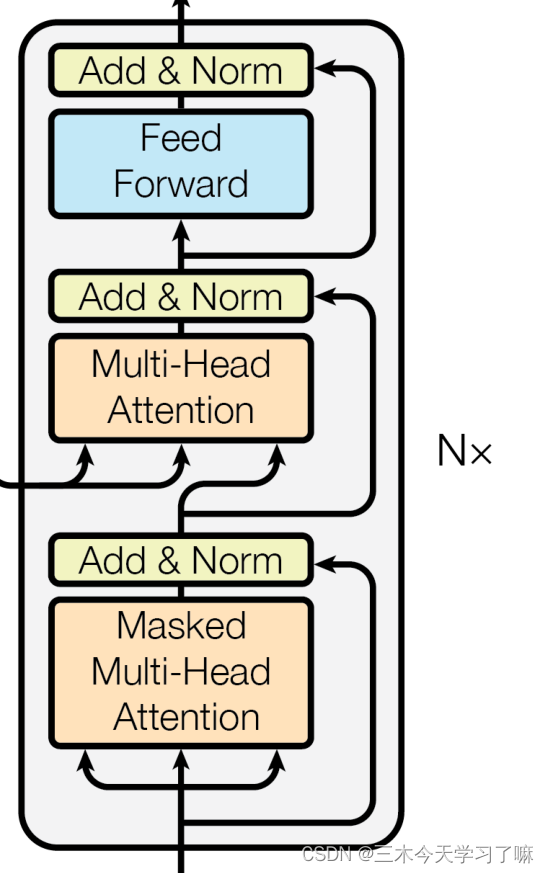
四、解码器部分
- 解码器部分:
由N个解码器层堆叠而成
每个解码器层由三个子层连接结构组成
第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
4.1 解码器层
- 解码器层的作用:
作为解码器的组成单元,每个解码器层根据给定的输入,向目标方向进行特征提取操作,即解码过程。
4.2 解码器
- 解码器的作用:
根据编码器的结果以及.上-次预测的结果,对下一次可能出现的 ”值“ 进行特征表示。
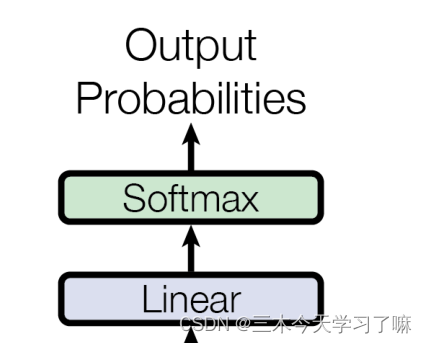
五、输出部分
-
输出部分包含:
线性层
Softmax
-
线性层的作用:
通过对上一步的线性变化得到指定维度的输出也就是转换维度的作用。 -
softmax层的作用:
使最后一维的向量中的数字缩放到0-1的概率值域内,并满足他们的和为1。