1.什么是Transformer?
首先,我们需要弄清Transformer的来龙去脉,先从seq2seq模型谈起。seq2seq是sequence to sequence的简写,指一类模型其输入是一个序列,输出是另一个序列,比如翻译任务,输入是一段英文文本序列,输出是中文序列,序列的长度可以是不相等的。seq2seq是一类模型,而Encoder-Decoder是这类模型的网络结构。Encoder即编码器,将原始文本转换为一个固定长度的语义向量,再由解码器Decoder对其进行解码,得到输出序列,由此完成一个sequence到另一个sequence的转换。
原始的seq2seq,其encoder和decoder一般都是由RNN来承担,RNN很适合于处理这种序列,能够利用整个句子的信息,但是缺点是难以处理长程依赖,无法并行,计算效率低;CNN可以并行,但是利用的信息有限,如果要看到整个句子,就要叠很多层。Transformer就是一种encoder-decoder结构,其encoder和decoder不再简单的使用RNN或CNN,而是由特殊设计的block堆叠而成,这个特殊设计的block中应用了自注意力机制,可以并行计算,并且能够让模型对重要的信息重点关注。
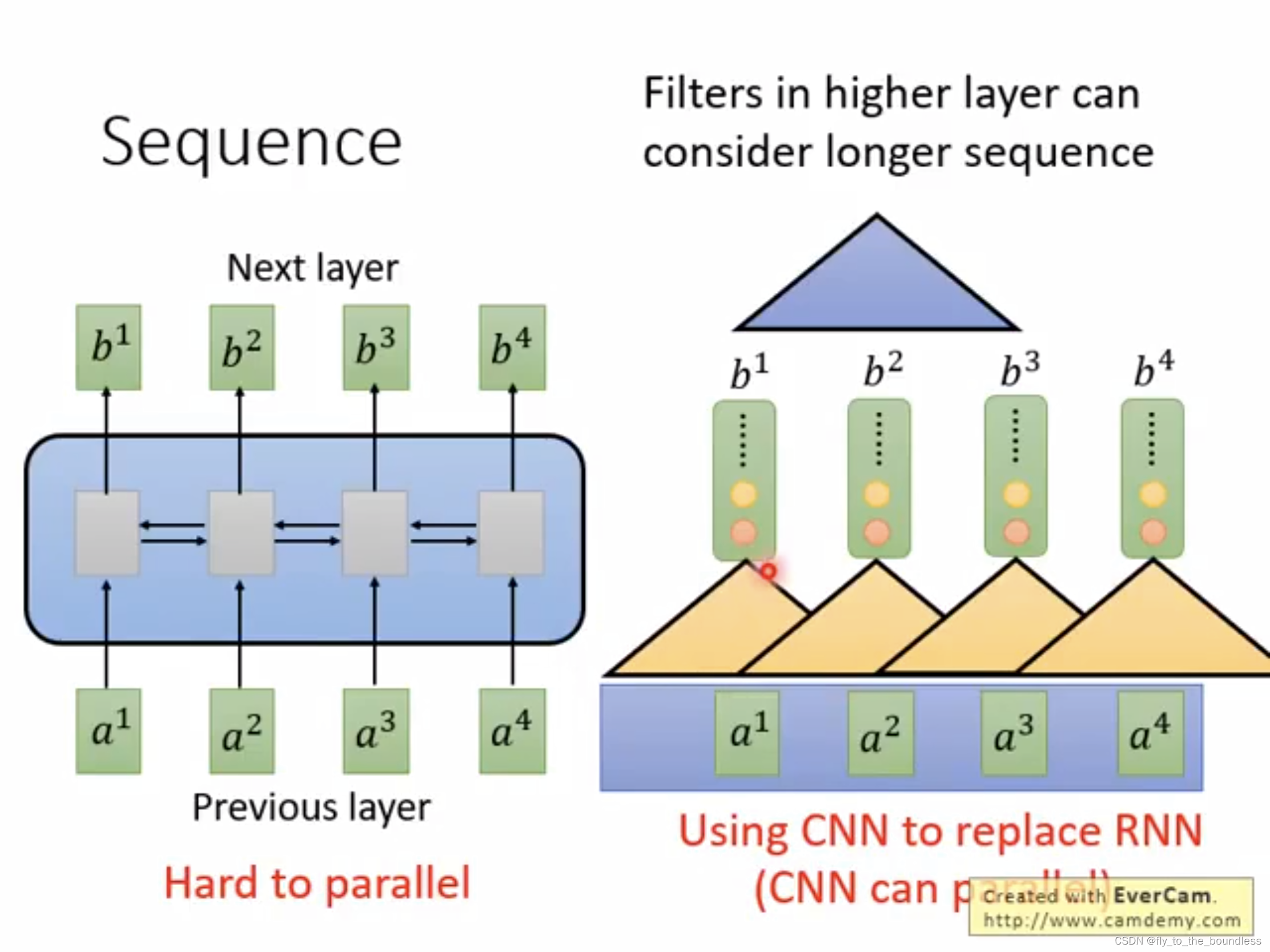
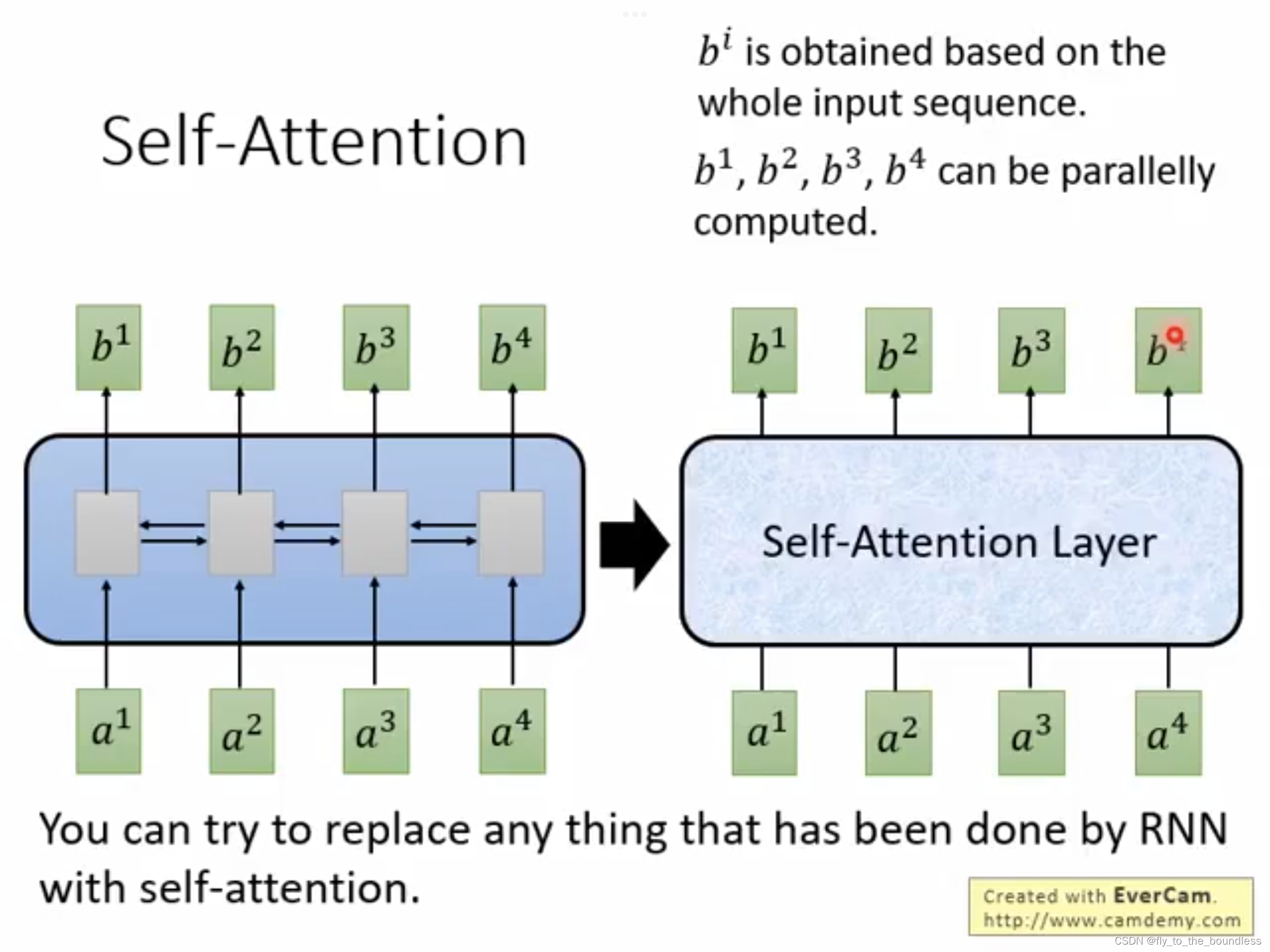
现在,总结一下什么是Transformer,看一下Transformer的整体结构。首先明确它是seq2seq的 Encoder-Decoder架构,先看Encoder部分,此时可以把它当成黑盒去只看它的输入输出,即:输入是一排向量,输出是另一排向量。Encoder的输出会送到Decoder中,经过一系列处理得到又一排向量,经过线性层和softmax层得到最终的结果。内部具体的过程后文再进行详细介绍。

2.自注意力机制
自注意力机制说白了,就是对一个句子中的词,计算其他词和它的相关性大小(这里说相关性可能不准确,就是该词和其他词之间的联系程度,或者说,理解该词时应放多少注意力在其他各个词上),这个值就是注意力分数,两个词之间的注意力分数大,意味着两者之间联系紧密,因而经过自注意力机制处理后的向量,更能够捕获词语间的语义依赖关系。其计算步骤如下:
(1)对每一个单词的词嵌入向量 x i x_i xi,生成三个向量:查询向量 q i q_i qi、键向量 k i k_i ki 、值向量 v i v_i vi. 这三个向量是通过词嵌入与三个权重矩阵相乘创建的。即:
q i = x i ⋅ W Q q_i=x_i\cdot W_Q qi=xi⋅WQ k i = x i ⋅ W K k_i=x_i\cdot W_K ki=xi⋅WK v i = x i ⋅ W V v_i=x_i\cdot W_V vi=xi⋅WV
(2)计算自注意力得分。假设我们在为句子中第一个词 “today” 计算自注意力向量,我们需要拿输入句子中的每个单词对 “today” 打分。这些分数决定了在编码单词 “today” 的过程中有多重视句子的其它部分。这些分数是通过打分单词(所有输入句子的单词)的键向量与 “today” 的查询向量相点积来计算的。
举例来说,一个句子有 n n n 个单词,其嵌入向量分别为: x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn,计算第一个单词的自注意力向量,就是用每一个词的键向量 k i ( i = 1 , . . . , n ) k_i(i=1,...,n) ki(i=1,...,n) 乘第一个单词的查询向量 q 1 q_1 q1 得到第一个单词对应其他各个词的注意力分数: s c o r e ( x 1 , x i ) = q 1 ⋅ k i score(x_1,x_i)=q_1\cdot k_i score(x1,xi)=q1⋅ki
(3)将分数除以8(除8是因为,论文中使用的键向量维数为64,其平方根为8,除8可以让梯度更稳定。这里也可以使用其它值,8只是默认值) : s c o r e ( x 1 , x i ) / 8 score(x_1,x_i)/8 score(x1,xi)/8
(4)softmax归一化,得到的分数都是正值且和为1,这个分数反应了各个单词和第一个单词相关性的大小。
(5)每个值向量 v i v_i vi (前面计算注意力分数用了 k k k 和 q q q,这里用的是 v v v) 乘以与其对应的softmax分数,相当于进行加权。
(6)对加权值向量求和,得到第一个单词 x 1 x_1 x1 经过自注意力机制处理之后的向量,然后将该结果送入前馈神经网络中即可。

以上就是自注意力机制的一般过程,但是在Transformer中,实际使用的是 多头注意力multi-head attention,其实就是同样的计算步骤基于不同的 W K , W Q , W V W_K,W_Q,W_V WK,WQ,WV 矩阵进行多次,这些矩阵都是进行随机初始化生成的。Transformer使用八个注意力头,即有八组不同的 W K , W Q , W V W_K,W_Q,W_V WK,WQ,WV 矩阵,最后每一个原始词向量都有8个不同的向量表示,将其拼接到一起,再乘以一个权重矩阵 W O W_O WO 进行融合,得到自注意力层最后的输出。

3.Transformer结构解析
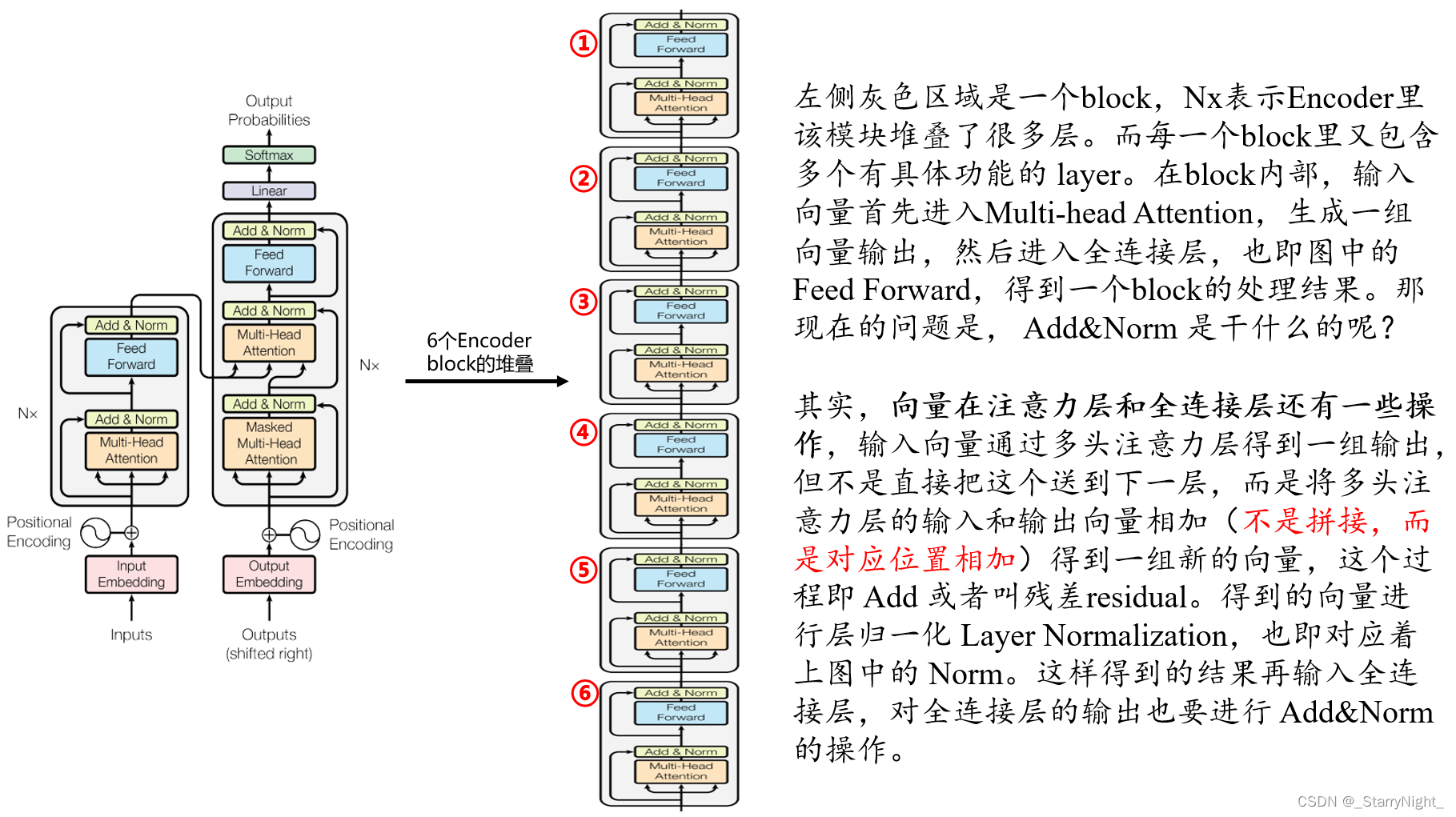
3.1 Encoder
下图展示了Encoder的主要过程:
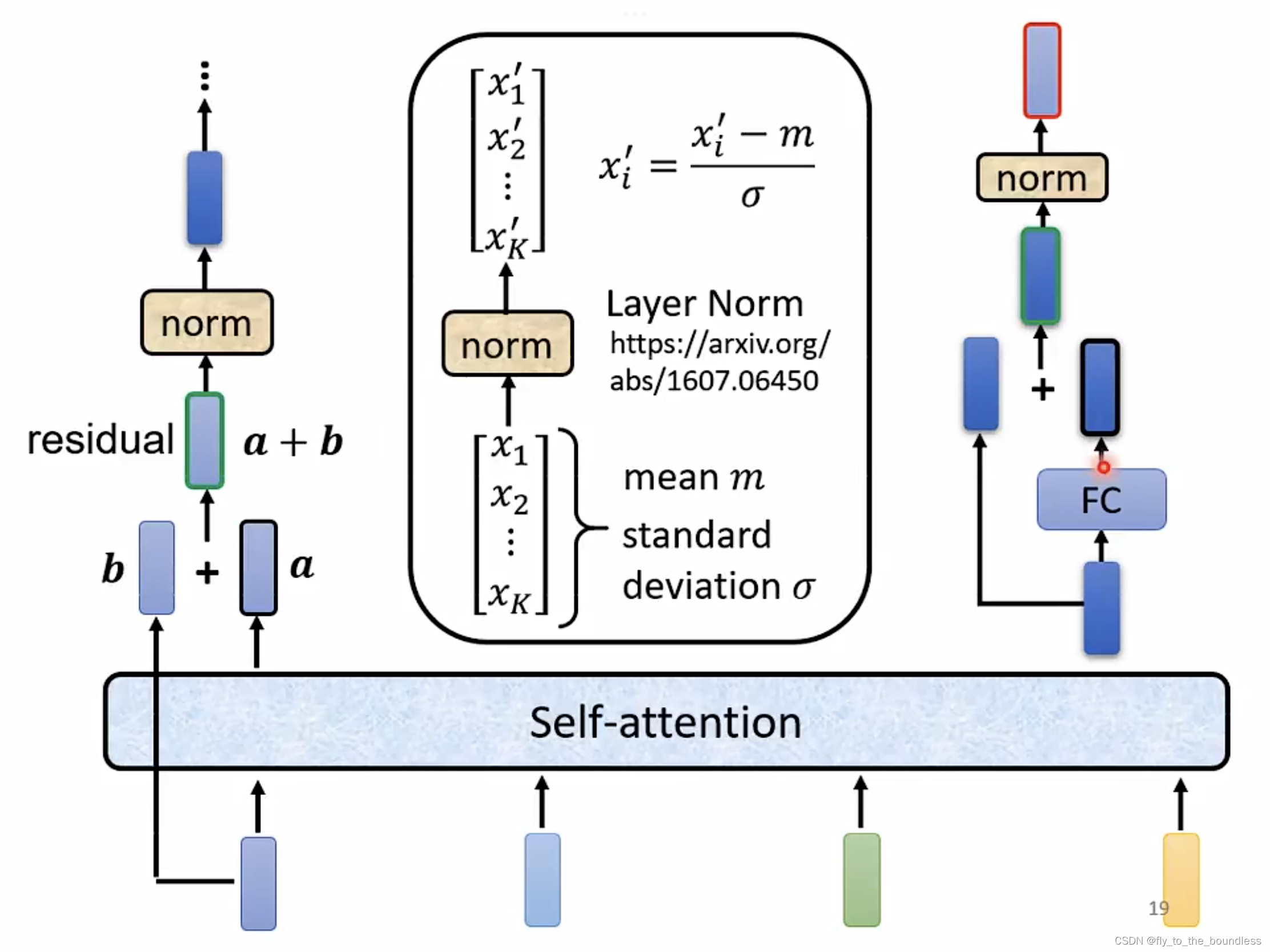
再用一个图来直观地表达一下这个过程,这个图片里解释了层归一化的具体操作(等式右侧的 x i ’ x_i^’ xi’ 改为 x i x_i xi)
3.2 Decoder
Decoder与Encoder的区别在于,有两个MultiHead Attention:
- 底层是Masked MultiHead Attention
- 中间的MultiHead Attention可以叫做cross attention,正是这个组件将encoder和decoder连接起来
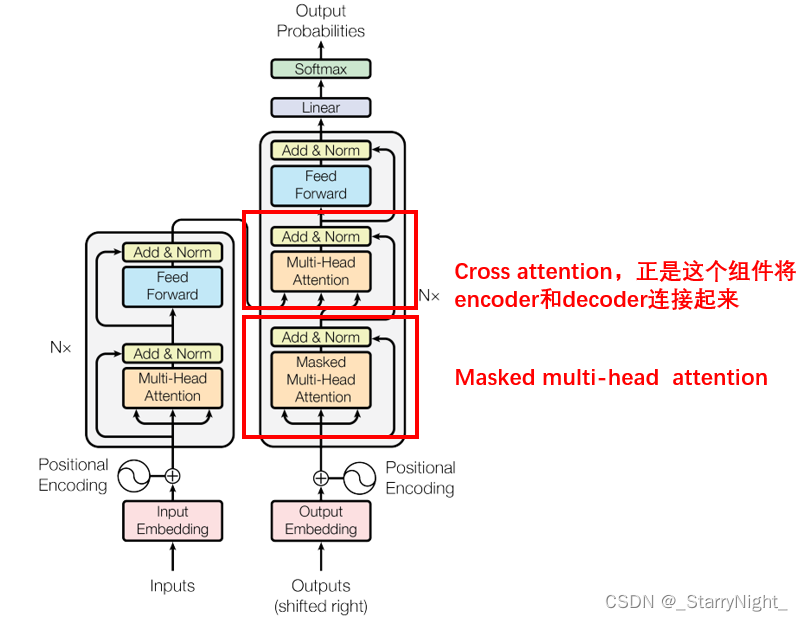
下面主要解释一下什么是Masked MultiHead Attention以及decoder和encoder是怎么连接交互的。
(1)Masked MultiHead Attention
如图所示,masked的意思是,生成 b 1 b_1 b1 的时候只能考虑 a 1 a_1 a1, 生成 b 2 b_2 b2 的时候只能考虑 a 1 a_1 a1, a 2 a_2 a2,而不能考虑 a 3 a_3 a3, a 4 a_4 a4……为什么要这样做呢?比如说翻译任务,Encoder是一次性把整个 a 1 a_1 a1- a 4 a_4 a4都用进去,但是翻成另一种语言时是从左到右依次生成的,在翻译到第一个字的时候,右边还没有其他的字。Decoder是从左到右解码的,先有 a 1 a_1 a1, 再有 a 2 a_2 a2,逐次生成,在生成 b 2 b_2 b2的时候,还没有 a 3 a_3 a3, a 4 a_4 a4.

关于这一部分的内容,这篇帖子讲解得很详细:Transformer模型详解
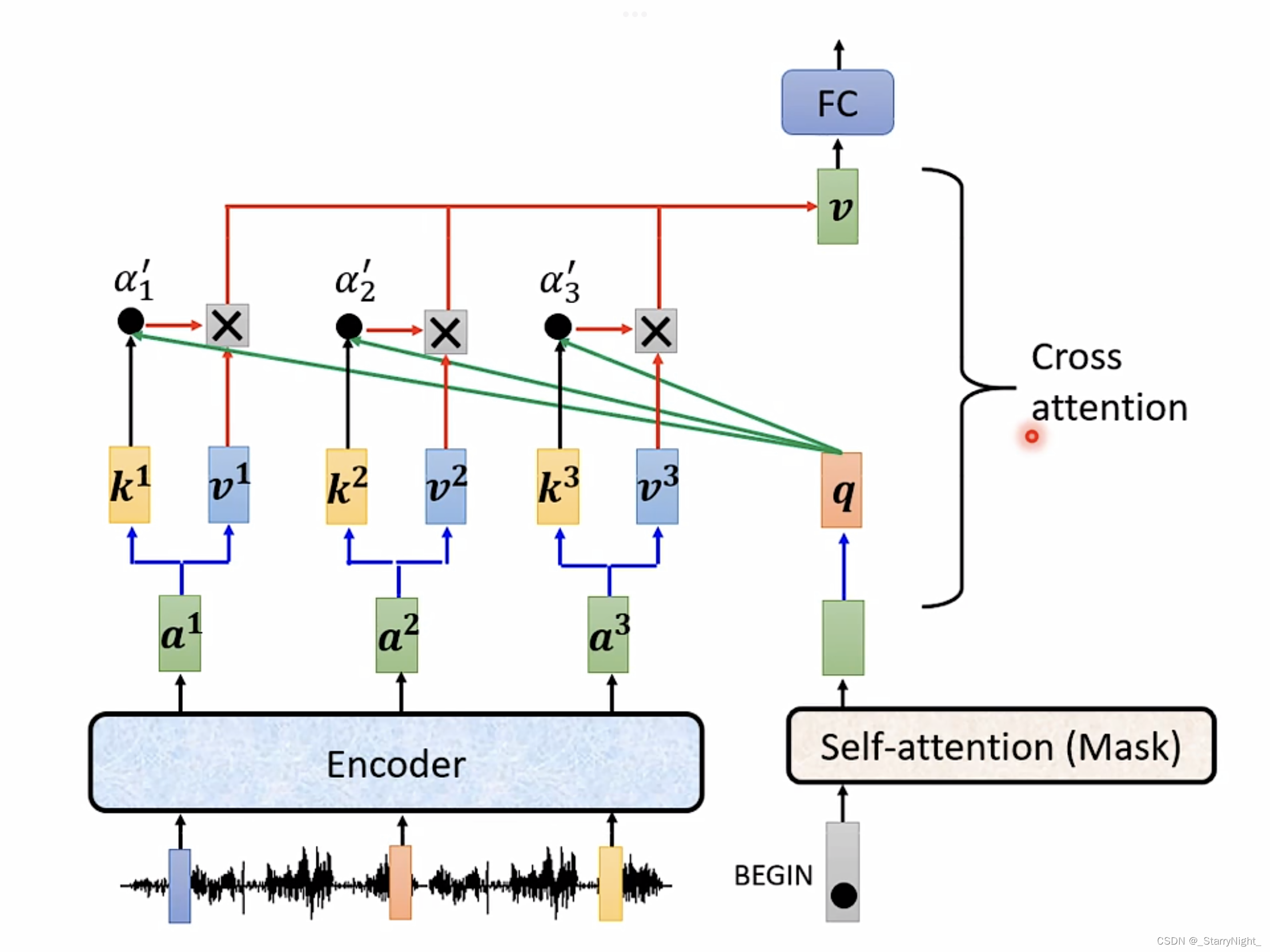
(2)cross attention
Decoder模块中间的部分即cross attention, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的的最终输出来计算的。
根据 Encoder 的输出计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q,这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
总结
Encoder部分的每一个block,接收输入向量,和八组不同的权重矩阵 W K , W Q , W V W_K,W_Q,W_V WK,WQ,WV 相乘得到八组 k , v , q k,v,q k,v,q,利用 k , q k,q k,q 计算注意力分数,这个注意力分数和 v v v 相乘起到加权求和的作用,八个拼起来再成权重矩阵 W O W_O WO得到一个block的最终输出向量。同样的操作重复6次得到encoder部分的最终输出。decoder这边先要给一个表示开始的特殊token,经过mask multihead attention处理得到中间结果,用它生成查询向量 q q q 和基于Encoder输出结果生成的 k , v k,v k,v 进行自注意力机制处理。Decoder也是有6个同样的block,每次做cross attention都是和encoder的最终结果进行的。