第一次自己写博客…记录一下自己的学习和日常…封校期间找点乐子,希望以后继续努力。
参考博客@ https://blog.csdn.net/weixin_42691585/article/details/108994556
以及@ https://zhuanlan.zhihu.com/p/48508221
“Stay hungry , Stay young”
Transformer的理论推导
前言
模型提出的背景:
现有的RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
-
时间片t的计算依赖 t-1 时刻的计算结果,这样限制了模型的并行能力;
-
顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
因此, Transform的提出解决了上面两个问题,首先使用Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
简介
Transformer是一种基于encoder-decoder结构的模型,它抛弃了以往的seq2seq模型中的RNN,采用Self—attention或者Mulit-head-self-attention使得输入的数据可以并行处理,提高运行效率。具体的结构可以参考下图:

具体结构
1.Encoder(编码器)部分
主要由self-attention(自注意力)组件和前馈神经网络组成,下面重点谈一下self-attention组件
1.1self-attention组件
1.首先,我们将特征进行embedding,将单词转化为各种向量或者张量
embedding:是一种稠密向量的表示形式,起到将自然语言转化为了数学语言,比起one-hot这种稀疏矩阵的表示形式,它能通过降维,占用更少的空间,降维的原理就是矩阵的乘法,在语义理解上,将不同的文字解释成向量,就能进行对他们的数学运算了
对于transformer而言, 每个词向量都有自己的路径流入编码器,且路径与路径之间两两相互联系
2.进入注意力机制
第一步:从词向量在进入self-attention模块后,通过分别乘以三个矩阵产生三个词向量,q,k,v,下面我将通过简单的例子解释过程,在过程中你将理解不同向量的用途:
比如说当我们处理"Head First Java"这句话时,对于Head的词向量而言,q1将点乘k1,k2,k3,以此获得三个评分,这是词向量q1对于 Head,First和 Java三个单词的关注程度,
好的,现在我们得到了词向量三个评分代表q1对三个部分的评价程度:
第二步,我们需要做的就是除以根号下第一个维度开方的结果:
具体的公式为:

第三步,使这个评分经过softmax函数,也就是归一化操作,得到![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lBLZwgQI-1610413482406)(file:///C:\Users\李子毅\AppData\Local\Temp\ksohtml5400\wps2.png)]](https://img-blog.csdnimg.cn/20210112091923640.png)
softmax函数是一个经典的激活函数,常用于多分类问题:他能将多个神经元的输出映射到(0,1)区间,也就是为不同映射值的概率:
下图来自知乎@PP鲁
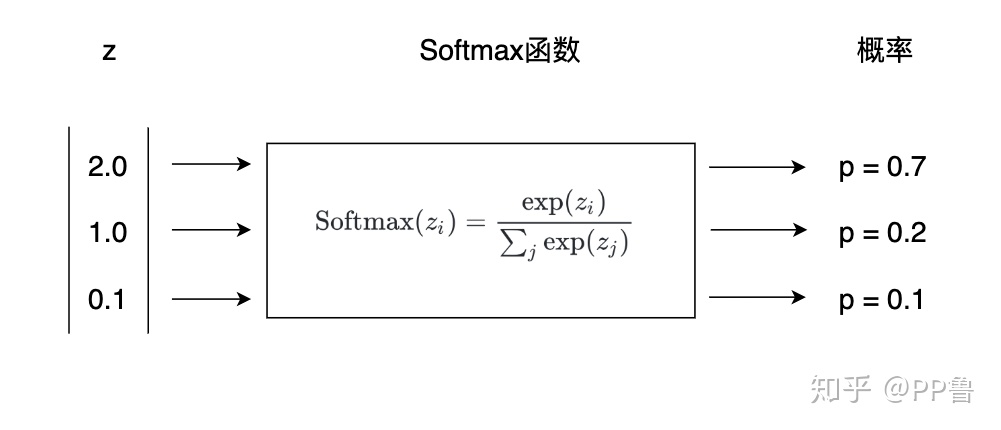
这样,最后我们就得到了这个词向量对于其他部分的关注程度。
第四步:得到的每个![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3VTem6It-1610413482408)(file:///C:\Users\李子毅\AppData\Local\Temp\ksohtml5400\wps2.png)]](https://img-blog.csdnimg.cn/2021011209200247.png)
与对应的![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-denyqyKn-1610413482408)(file:///C:\Users\李子毅\AppData\Local\Temp\ksohtml5400\wps3.png)]](https://img-blog.csdnimg.cn/20210112092019810.png)
(值向量)相乘,保留关注词的value,削弱其他非关注词的value,将所有向量加和,得到最后的![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dyw3dJbv-1610413482409)(file:///C:\Users\李子毅\AppData\Local\Temp\ksohtml5400\wps4.png)]](https://img-blog.csdnimg.cn/20210112092041339.png)
,不过为了运算速度,其实以上这些过程都是由矩阵实现,这里不再展示。
论文的新增加机制:Multi-head Attention多头注意力机制:
在self-attention机制的基础上,将每个q,k,v向量分解成了多个头部,每个头部只能进行相应的点乘和乘积运算,得到两个b,分别乘以权重矩阵拼接为一个b
2.Add&Normalization操作
对于已经得到的向量b,我们进行Add&Normalization归一化处理,处理流程如下:
对于每一个b,我们进行b’=a+b的操作,a为输入的向量,然后再进行LayerNormalization(横向归一化)处理,
LayerNormalization:经典的正态分布标准化的方式来标准化,然后加上激活函数输出
最后,我们将输出的数据输入前馈神经网络,并进行Add&Normalization操作
2.Decoder(译码器)部分
比Encoder多了一个masked Multi-head Self-Attention,作用是隐藏未来信息,仅仅关注已经生成的序列信息
Decoder部分的输入是上一个时间步产生的output,通过 output embedding 加上位置信息进入解码器,具体过程如下:
第一步:进入Multi-head Self-Attention,隐藏未来信息,只关注当前的序列信息
第二步:Add&Normalization归一化处理
第三步:进入Multi-head Attention组件,此时的输入为编码器的最终输出K和V,以及上一步归一化处理得到的向量(上下文向量)
第四步:和Encoder一样的Add&Normalization,前馈神经网络,Add&Normalization过程。
第五步:将浮点向量转化成词:此时需要softmax和linear层
linear层是个简单的全连接层,将解码器的最后输出映射到一个非常大的logits向量上。假设模型已知有1万个单词(输出的词表)从训练集中学习得到。那么,logits向量就有1万维,每个值表示是某个词的可能倾向值。
softmax层是将这些值转化为概率,这个过程上文已经讨论过了,最高值对应的维对应的词就是就是最终预测得到的输出单词