demo:
tracking_video2
基于深度关联的摄像头-激光雷达融合的三维多目标跟踪框架
paper:https://arxiv.org/abs/2202.12100
code:https://github.com/wangxiyang2022/DeepFusionMOT
2d:RRC
3d:PointRCNN
摘要:一方面,许多3D多目标跟踪(MOT)工作专注于跟踪精度而忽略了计算速度,通常通过设计相当复杂的代价函数和特征提取器。另一方面,一些方法过于注重计算速度而牺牲了跟踪精度。
针对这些问题,本文提出了一种鲁棒且快速的基于相机-激光雷达融合的MOT方法,该方法在精度和速度之间取得了良好的平衡。基于摄像机和激光雷达传感器的特点,设计并嵌入了一种有效的深度关联机制。该关联机制实现了在距离较远且仅被摄像机探测到的情况下,对二维区域内的目标进行跟踪,并在目标出现在激光雷达视场时,利用获取的三维信息更新二维轨迹,实现了二维和三维轨迹的平滑融合。基于典型数据集的大量实验表明,我们提出的方法在跟踪精度和处理速度方面都比最先进的MOT方法具有明显的优势。
多数MOT方法都是在跟踪检测框架下设计主要包括两个步骤:1)目标检测,2)数据关联。
将当前帧内的轨迹投影到下一帧,直接在映射区域内找到匹配点并计算对应的代价函数,从而减小搜索区域和计算成本。
现在存在的常见问题如下:1)现有的基于摄像头的MOT方法通常缺乏三维跟踪所需的深度信息。虽然有些方法利用立体摄像机获取距离信息,进而实现三维跟踪,但计算量较大,深度信息的精度不如激光雷达传感器。另一方面,由于缺乏像素信息,基于lidar的跟踪方法无法准确跟踪远处的目标。现有的大多数基于相机和激光雷达融合的跟踪方法都设计了复杂的特征提取器,因此这些方法通常需要在gpu上运行,不容易实现实时应用。2)大多数方法在摄像-激光雷达的过程中没有充分利用视觉数据和点云数据。


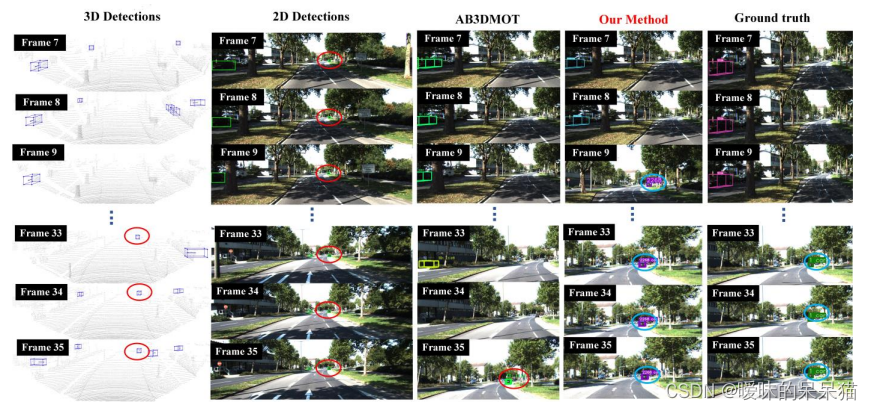
可视化结果:


