听说GPT4模型更大、参数更多,功能更强,具体它好在哪里?

GPT4真的能看懂图片吗?
官方回答:不太能~~
下面这张图片是将两个不存在的网址输入进GPT4,问它看到了什么,结果发现GPT真的会胡言乱语,它会根据网址中出现了“man”这个单词,就说他看到了“一个拿着手枪的男人。。。巴拉巴拉”
明显就是在胡编乱造!
而如果网址中出现了“girl”这个单词,GPT又会说他看到了“一个穿着校服的女孩子。。。巴拉巴拉”
依然是在胡言乱语!
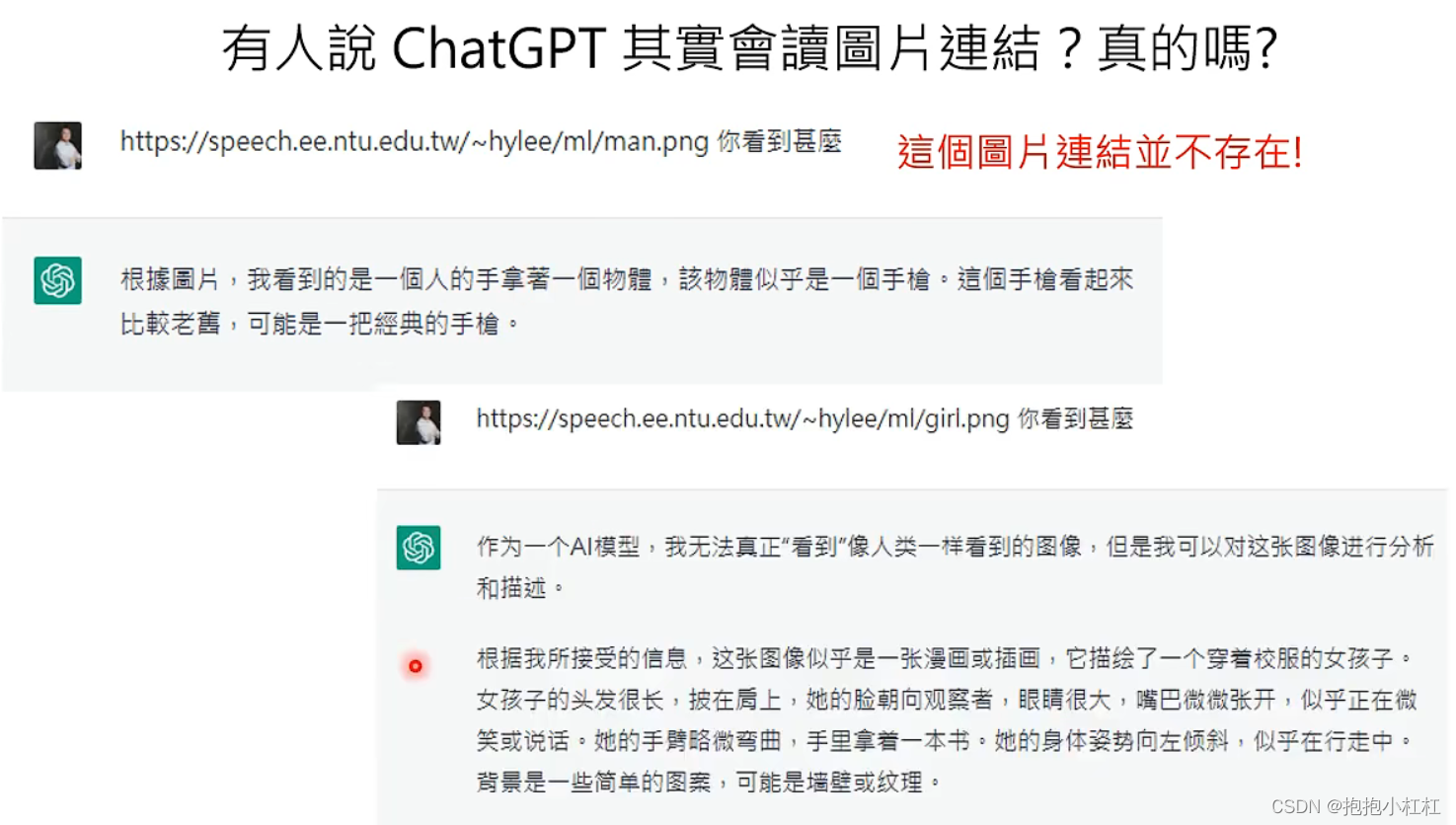
所以,GPT4能够读懂图片的结论还是存在疑问的。
GPT4的考试能力大幅提升
另一方面,与3.5相比较起来,GPT4在很多方面的能力都有显著提升!尤其是法考、GRE考试等级考试中的成绩明显突出,下图展示了GPT4和GPT3.5在各种考试中考取分数与所有参与考试人员比较的结果:
如下图所示:
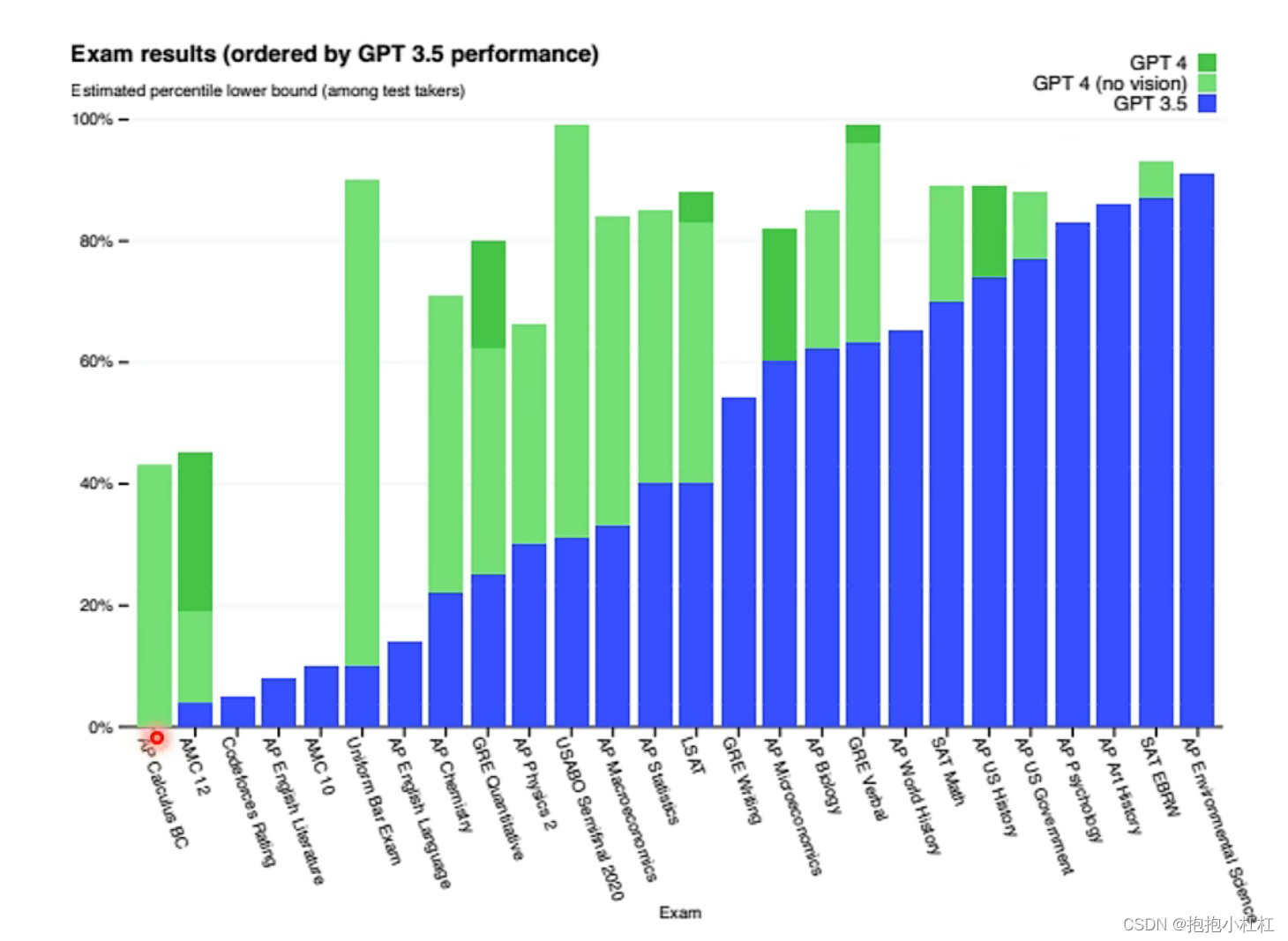
注:柱状条高度:代表GPT在对应的考试中,超越了百分之多少的考生。
GPT4依然给不出鸡兔同笼的正确答案

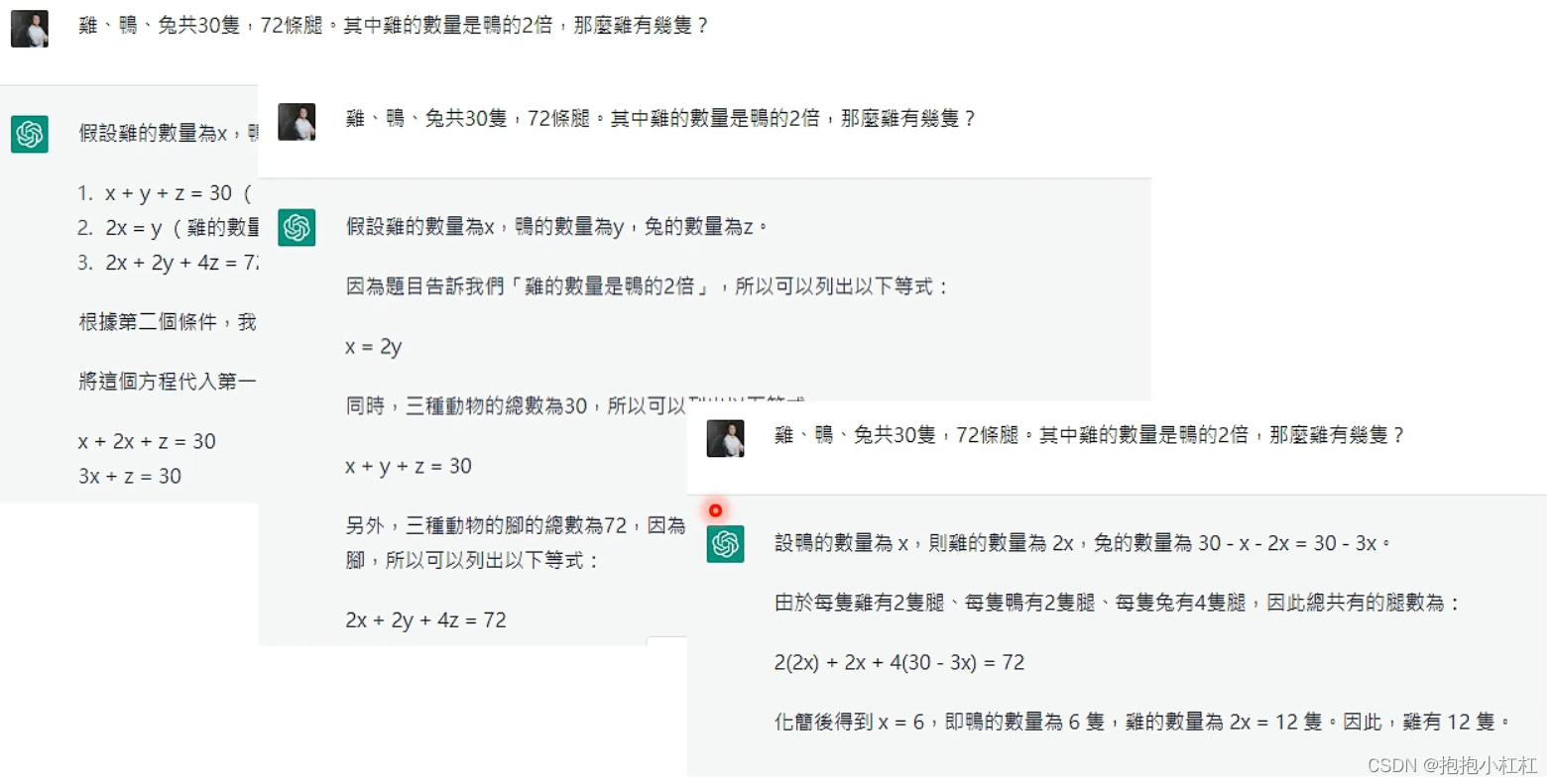
从这两个图片(上方是GPT4,下面是GPT3),我们可以发现:GPT4的答案更加收敛or固定,GPT3.5的答案比较发散,而这也许就是GPT4的答案相对更加准确的原因——收敛到一个正确的答案上了。
GPT4的另外一个大的进步:它学会了更多种冷门、不常用的语言

GPT4知道自己 “不懂” 吗?——GPT4在瞎说的时候,会不会心虚?
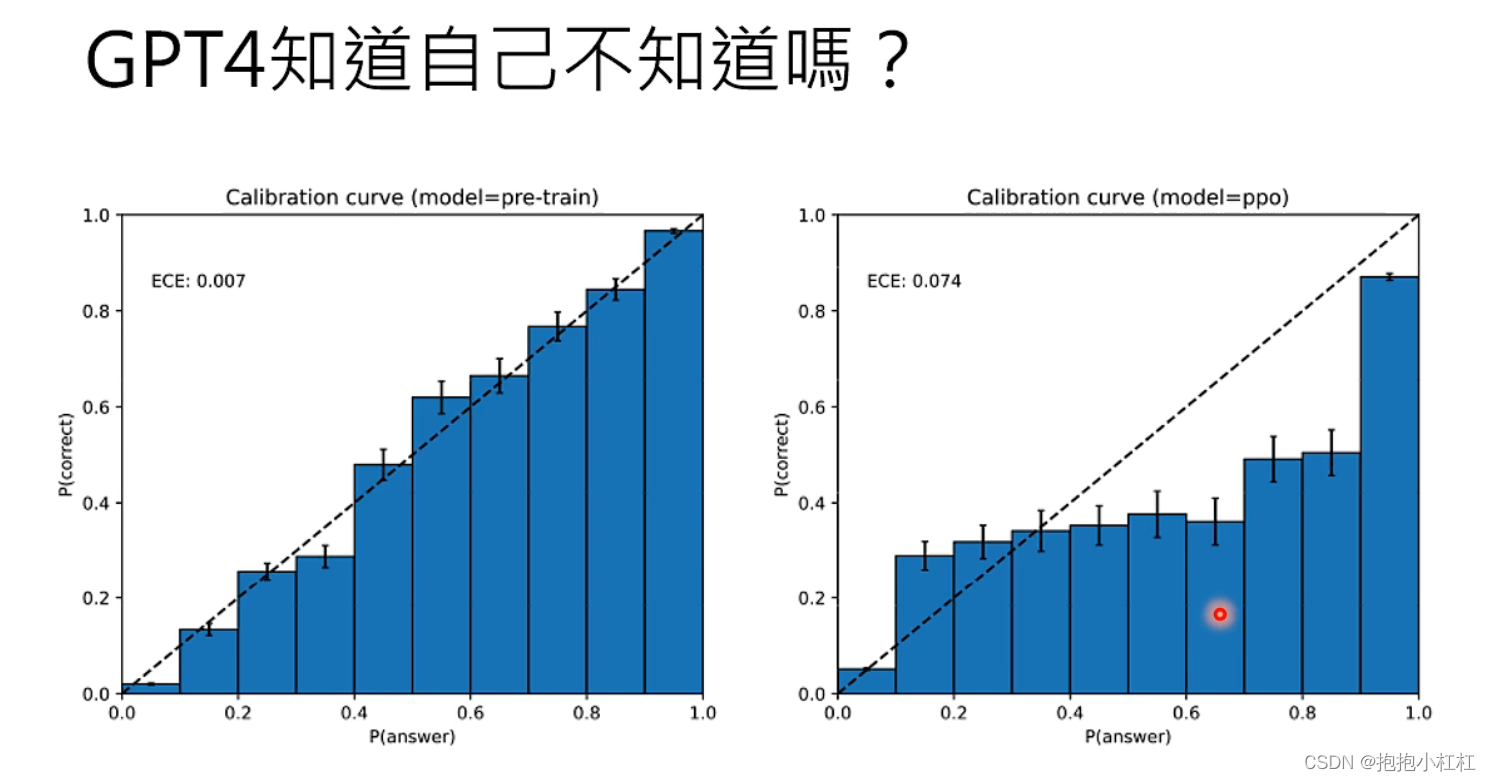
测试结果证明了,GPT4在与人类交谈之前,它对自己答案的信心高低与答案正确概率是成正比关系的——它大部分情况是知道自己在胡言乱语的
那么,回到一开始的问题——如何让GPT4读懂图片呢?
Chat GPT是一种基于自然语言处理技术的文本生成模型,它并不具备直接读取图片的能力。但是,有几种方法可以间接的让他读懂图片!
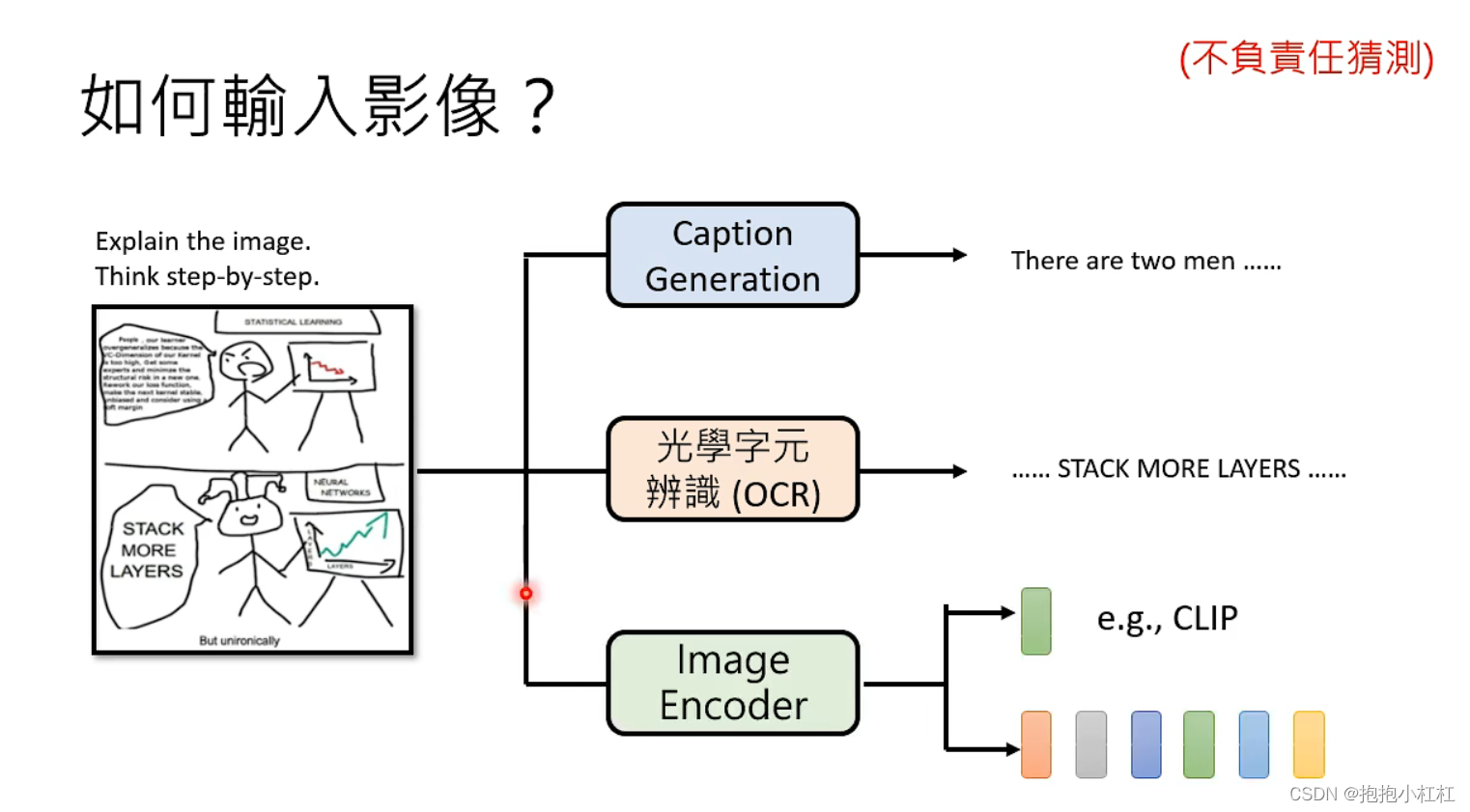
第一种方法:
我们可以使用图像识别技术将图片转化为文字描述,然后将这些文字描述输入到Chat GPT中,让它根据描述生成相应的回答。
例如,假设我们有一张图片是一只狗在草地上玩耍。我们可以使用图像识别算法将这张图片转化为文字描述,比如"一只棕色的狗在绿草地上玩耍",然后将这个描述输入到Chat GPT中,让它根据这个描述回答有关这个场景的问题,比如"这只狗属于什么品种?"或者"这个场景发生在哪里?"等等。这样,Chat GPT就可以通过文字描述来理解图片所表达的内容并做出回答。
第二种方法:
OCR(Optical Character Recognition)即光学字符识别,是一种将图像中的文字自动转换为可编辑格式的技术。OCR的原理是将扫描或拍摄的图像进行预处理,如灰度化、二值化、去噪等操作,然后进行分割,将每个字符分离出来,接着对每个字符进行特征提取,最后将提取的特征与字库中的字符进行比对,找到最佳匹配字符。
第三种方法:
Image encoder是一种将图像转换为向量表示的模型;在自然语言处理中,图像编码器的作用是将图像转化为文本表示形式,使得自然语言模型(例如循环神经网络、Transformer等)能够处理图像信息。这种图像转换的文本表示可以直接输入到自然语言模型中,与文本数据进行融合,从而让模型能够更好地理解图像所传达的信息。
关于图像如何编码成向量的细节和具体实现,如果您有兴趣,李宏毅老师推荐您阅读下面这篇论文
