论文链接Ten Quick Tips for Harnessing the Power of ChatGPT/GPT-4 in Computational Biology | Papers With Code
之前在paper with code上比较火的一篇文章,最近要给生科的学长学姐们个分享所以把这个翻了翻,原文自认为废话比较多,于是选了点有用部分的放这给大家学习。
虽然我们主要关注的是当前的ChatGPT/GPT-4模型,但我们相信这些技巧将与该技术的未来迭代以及其他llm(如Meta的LLaMa和Google的Bard)仍会保持相关。
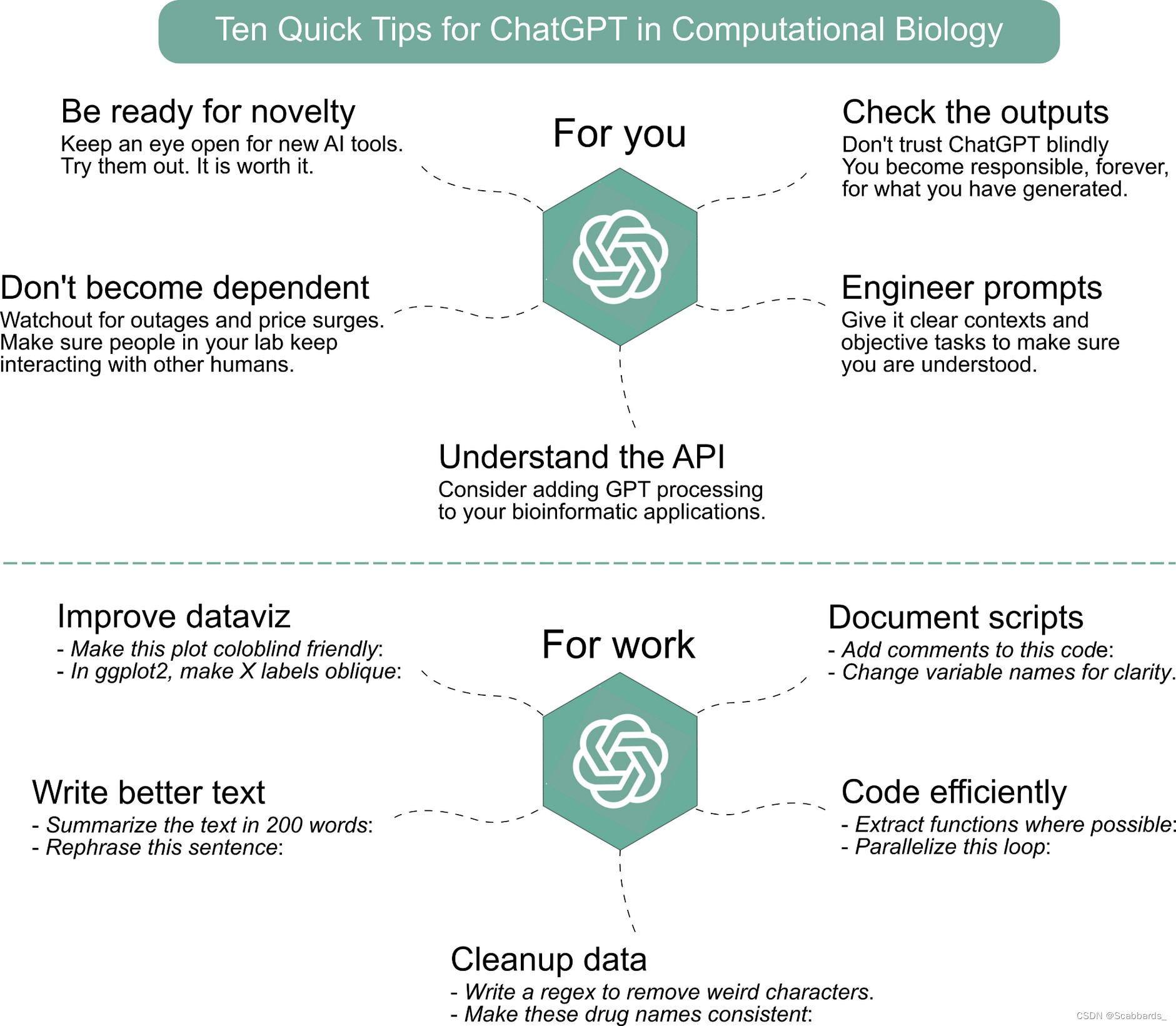
技巧1 :拥抱科技,准备迎接新鲜事物
没啥好说的,下一个
技巧2:提升代码可读性,以及为函数编写文档
简单的提示,如“在此代码中添加解释性注释(Add explanatory comments to this code):”或“为清晰起见重命名变量(Rename the variables for clarity):”,已经可以为代码的未来读者提供了很多的方便。ChatGPT还可以通过在R中生成完整的roxygen2语法和在python中生成完整的文档字符串,从变量名和代码逻辑推断其含义,从而为函数编写文档。开始编写文档的提示示例可以是“Render roxygen2 documentation for the function:”。
技巧3:更高效地写代码
此外,ChatGPT还可以进行多种功能重构。提示如“提取函数以提高清晰度(Extract functions for increased clarity):”或“重写并优化此for循环(Re-write and optimize this for loop):”可以提高代码的模块化,甚至节省计算资源。重构时,重要的是要建立良好的测试以防止引入bug[12]。虽然ChatGPT也可以帮助您设置测试基础设施(提示类似于“为以下函数编写单元测试并帮助我实现它(Write a unit test for the following function and help me implement it)”),但重要的是要仔细检查它生成的内容,以确保它覆盖了它应该覆盖的内容。
在使用ChatGPT和实现完整的LLM应用程序之间的一个折衷方案是通过插件将ChatGPT添加到集成开发环境(ide)中。
例如,目前可以在Visual Studio Code (VSCode)中使用GPT-3.5和GPT-4,并且有开源插件 https://github.com/gencay/vscode-chatgpt

对于使用R和RStudio的生物信息学家,可以选择gptstudioGitHub - MichelNivard/gptstudio: GPT RStudio addins that enable GPT assisted coding, writing & analysis
然而,在该篇论文发布的几个月后又推出了copilot,这个一键绑,不需要api key只需要学生验证,所以更方便。 GitHub Copilot · Your AI pair programmer · GitHub
技巧4:增强数据清洗
数据和元数据有各种格式,虽然ChatGPT不会识别异常值或修复丢失的数据,但它可以为大多数常见任务提供工具建议并提供代码片段。它也可以与Excel合作,提供指导和编写宏。
ChatGPT在处理包含自然语言条目的数据集时最有用。如果你管理一个数据库或重新分析公共数据集,你可能不得不处理提交者输入的不一致的数据。虽然目前的工具不能一致地将数据匹配到唯一标识符(如数据库或本体提供的标识符),但它可以增加更多的一致性,并促进手动或自动生物配置步骤。一个清晰的应用程序是编写正则表达式,提示如“write me regex for R/python/Excel with A pattern that will extract {} from{}”。
ChatGPT可以极大地帮助直接规范化标签,并执行类似人类的复杂自然语言清理,就像在开放字段公式中发现的那样。对于小型数据集,您可以直接在ChatGPT界面中清理数据,并使用诸如“充当表并向该数据集添加一个具有一致标签的新列(Act as a table. Add a new column with consistent labels to this dataset):"之类的提示。对于较大的应用程序,可以使用附加组件,例如Google Sheets的GPT(ChatGPT for Google Sheets and Docs),或者甚至编写直接使用API的代码(参见技巧9)。
技巧5:用ChatGPT来增强数据可视化
数据可视化是计算生物学研究的重要组成部分
ChatGPT可以是一个有价值的工具,帮助创建有效和信息丰富的图形。这个工具的一个显著功能是它精通流行的可视化库,如ggplot2和matplotlib,例如“创建一个log10 Y轴的ggplot2小提琴图(Create a ggplot2 violin plot with a log10 Y axis)”。这种专业知识使它能够帮助用户克服语法挑战,建议新的可视化技术,并增强现有的图形。
虽然我们可能很快就能得到关于图像的直接反馈,但我们仍然可以利用GPT-4解析绘图代码的能力,并在需要改进的地方获得有价值的指导。例如,ChatGPT可以帮助您为图形选择合适的颜色,使色盲人士更容易访问图形,并建议改进可视化布局的方法。一个提示的实际例子,它可以导致你的视觉效果有意义的改进,如“改变我的代码让图形对色盲更友好(Change my code to make the plot color-blind friendly):”
技巧6:用聊天技巧提高你的写作水平
在计算生物学中,清晰有效的沟通尤为重要,专家必须能够用数学家、生物学家和计算机科学家都能理解的语言,将复杂的想法传达给具有不同科学背景的同事。ChatGPT提高了文本的清晰度,通过提供新的思路排序方式,如提示“给我提供以下句子的不同版本(Provide me some different versions of the following sentence):”。
ChatGPT还可以帮助重新格式化文本和总结思想,例如提示“将此文本总结为200字的会议摘要(“Summarize this text in a 200-word conference abstract):”。虽然它很少会产生一个你完全喜欢的输出,但它可以打破最初的障碍,帮助克服写作障碍。它还可以通过从自然语言创建项目符号列表并将项目符号列表转换为最终格式来帮助概述文件,从论文到教学计划。
不管你在什么地方使用ChatGPT(或其他语言模型)作为写作工具来提高你的写作,一定要公开它的用法,以防止任何误解。
关于将聊天机器人作为写作辅助工具的道德使用,特别是在出版手稿的背景下,负责任的使用指南正在出现。我们建议研究人员当把ChatGPT用于可发表研究时熟悉讨论,并在使用时查看出版商的指导方针。
技巧7:确保理解或知道如何测试它生成的内容
对于计算编程的初学者来说,不存在的函数或库的建议可能是一个重大障碍,并加强了对人工干预的需求。因此,学习开发人员提供的教程和与之相关的出版物非常重要。当使用ChatGPT来帮助语法时,重要的是只寻求那些你已经学习过并能理解的语法的帮助——或者至少测试一下结果。
技巧8:学习提示工程/设计的基础知识
提示工程/设计包括制作有效沟通的提示、示例、人物角色和目标,以生成适合您目标的响应模板。设置评估指标也很重要,以便在可用token的限制内为模型提供更明确的结果。
一个很好的提示例子是:“ChatGPT,我想了解GATK工具在生物信息学中的使用。您能否简要介绍一下GATK,它的主要应用,以及生物信息学领域常用的GATK套件中的一些流行工具?请包括与这些工具相关的任何优点和限制。(ChatGPT, I'd like to learn about the use of GATK tools in
bioinformatics. Could you provide a brief overview of GATK, its main applications, and some
popular tools within the GATK suite that are commonly used in the field of bioinformatics?
Please include any advantages and limitations associated with these tools.)”这个提示是有效的,因为它清楚地说明了上下文(生物信息学),指定了主题(GATK工具),概述了所需的信息(概述、应用、流行工具、优势和局限性),并为人工智能提供了一个简洁而集中的问题。
通过提供更多的上下文、细节和具体的目标,好的例子更有可能从ChatGPT中产生相关的和信息丰富的响应,而坏的例子可能导致不太令人满意的结果。在细化的第一个输出之后添加新参数是一种开放的可能性,但是必须谨慎,因为随着对话变得更长、更微妙和更复杂,丢失上下文的风险也会增加。因此,在初始交互中必须优先考虑特异性、客观性和完整性,以减轻错误理解的可能性
技巧9:考虑使用GPT API扩展应用程序
您可以使用API来改进用户友好应用程序的接口,允许用户使用人类语言与您的软件交互,并让GPT将其转换为可执行代码。该API也可以成为您自己工作流中的pipeline的一部分。例如,在文本挖掘和标记化pipeline中,它可用于从文本数据库中提取实体,或根据所需的停止词对文本进行总结。
微调包括对调节系统创造力的四个参数的操作:温度、top_p、frequency_penalty和presence_penalty。温度和top_p参数控制了输出的大胆度和非确定性程度,高值降低了响应在内容和意义上的重复性。frequency_penalty和presence_penalty参数调节输出中记号(单词)重复的可能性,这些参数的值越高,重复的记号就越少。
请注意,再现性是不保证的。然而,微调可能会产生更简洁、更少重复和更简洁的输出。
当输入的文本比web提示框允许的文本大时(约4000个字符),该API也可以提供帮助。可以使用GPT解析大型文档,方法包括LangChain GitHub - hwchase17/langchain: ⚡ Building applications with LLMs through composability ⚡,它能够修改来自不同来源的大量文档,供模型访问,并以更有组织的方式促进响应。
技巧10:不要过于依赖GPT
感觉也是凑数的,不管了
作者为了跟踪这些工具在生物信息学中的新的、创造性的用途,我们建立了一个GitHub存储库,以对相关内容进行众筹GitHub - csbl-br/awesome-compbio-chatgpt: An awesome repository of community-curated applications of ChatGPT and other LLMs im computational biology