点击↑上方↑蓝色“编了个程”关注我~

这是Yasin的第 1 篇原创文章

Chat GPT的优势
Chat GPT基本上是最近科技圈最火的话题了,甚至给圈外的人也造成了不小的震动。Chat GPT的成功带火了其它领域的AI产品,如:AI绘画、AI语音、AI生成视频等。
Chat GPT主要有以下几个优势:
大规模训练:ChatGPT基于GPT-4架构,通过大规模的训练数据集进行训练,使其能够理解和生成各种主题和领域的文本内容。
强大的语言理解和生成能力:ChatGPT能够理解复杂的语言结构和上下文,以生成流畅、连贯、准确的回答。
多语言支持:ChatGPT支持多种语言,可以与来自不同国家和地区的用户进行交流。
高度适应性:ChatGPT可以根据用户的输入进行适应,生成有针对性的回答,应对各种情景和应用。
跨领域知识:由于其训练数据的广泛性,ChatGPT可以回答涉及多个领域的问题,如科学、技术、艺术、历史、文化等。
创意文本生成:ChatGPT具有一定的创意能力,可以用于编写故事、文章、歌词等创意性文本。
可定制性:ChatGPT可以通过进一步的微调和训练,满足特定场景、行业或领域的需求。
Chat GPT为什么能如此智能?因为它的参数多、训练数据大、训练时间长,或许还有内部的一些其他“黑科技”,毕竟目前Chat GPT版本3以上就是闭源的了。
目前国内的大厂也纷纷开始跟进大预言模型的训练,但还有很长的路要走,或许需要一年多的时间甚至更长的时间才能追赶上3.5的水平。
最近圈子内的每天都有关于AI的新闻,但作为技术人员,我们不能只停留在惊叹和使用层面,而是应该考虑「如何利用好这种AI基建」,为我们所用,来提升我们的产品和业务。
Chat GPT的局限性
尽管Chat GPT很智能,但它还是有一些局限性。
信息准确性:ChatGPT可能会提供错误或过时的信息。尽管它的训练数据非常丰富,但知识截止日期为2021年9月,因此对于最新的信息和事件可能无法提供准确答案。
逻辑一致性:在一次对话中,ChatGPT可能会给出不一致的回答。它可能在不同回答中展示出相互矛盾的观点。
缺乏深入理解:虽然ChatGPT可以回答很多问题,但它可能缺乏对某些问题的深入理解。它主要依赖模式匹配和语言模型来生成回答,而不是真正理解问题的本质。
过于冗长或过于简化的回答:有时ChatGPT可能会生成过于冗长或过于简化的回答,可能不完全满足用户的需求。
不恰当的内容:ChatGPT有时可能生成不恰当或具有偏见的内容。虽然已经采取了一定的措施来减少这种情况的发生,但仍然需要用户注意并进行筛选。
无法进行实时互动:ChatGPT无法进行实时语音或视频互动,仅限于文本交流。
容易受输入的影响:ChatGPT的回答容易受用户输入的影响,可能导致输出的质量波动。
泛化能力受限:对于某些特定领域或行业,ChatGPT可能缺乏足够的专业知识,需要进一步定制和训练以满足特定需求。
总结下来,如果我们需要在某些专业领域或者场景需要让Chat GPT为我们所用,我们主要需要解决「两个问题」:
我有一些「私有的或者专业的知识库」,没有进过Chat GPT的训练池。如何让Chat GPT学习到这些知识库,并返回这个知识库的内容?比如客服场景、医疗场景。
我有一些自动化的程序要跟Chat GPT打通,消费Chat GPT返回的数据。如何让Chat GPT返回我「需要的格式」?例如某种json?比如智能购物、智能家居等场景。
->PS:GPT 3.5 的单词对话上下文token限制是4k,4.0也只有8k和32k的选项,对于庞大的专业知识库来说可能远远不够。而且token真的很贵!
<-
最近对这方面有一些研究,这篇文章主要总结这方面的思路和实践。
几种思路
要让AI回答特定领域的问题,我总结了几种实现思路。思维导图如下:
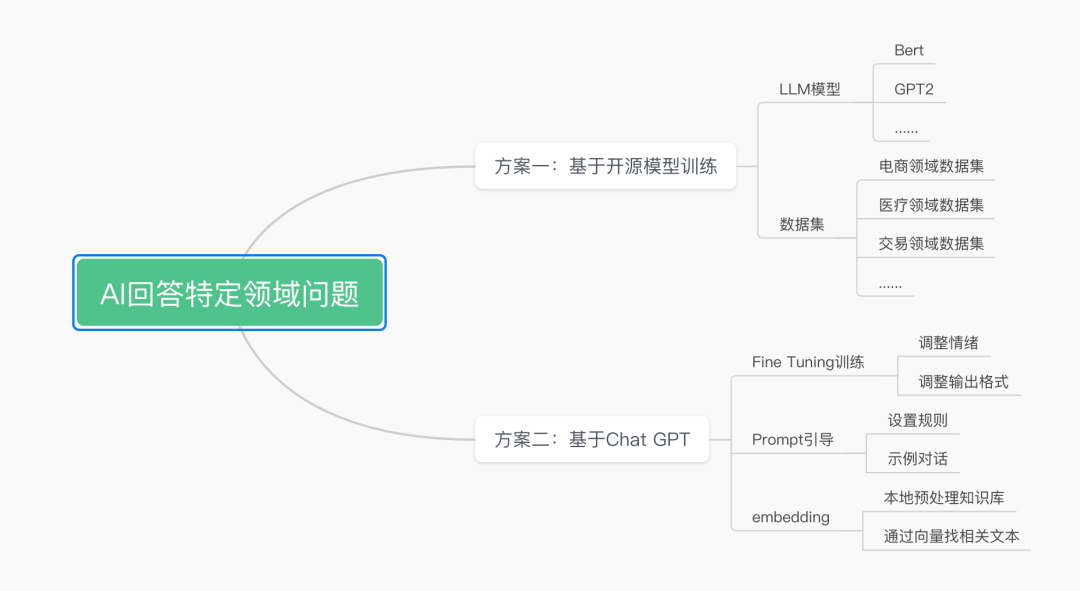
方案一这里就不详细介绍了,是业内已经比较成熟的思路。但由于底层没有Chat GPT 3.5或者4这么强大的模型加持,可能训练出来了的智能程度也不太够,效果不好。但在一些场景其实是已经有所应用了的,比如搜索、推荐等。
Fine-tuning
Fine-tuning(微调)是深度学习中一种常用的技术,它在预训练模型的基础上进行二次训练,以适应特定任务或领域。对于ChatGPT这类大型预训练语言模型,fine-tuning有以下作用:
适应特定任务:通过在特定任务的数据集上进行fine-tuning,可以使模型更好地适应这些任务,如情感分析、文本分类、问答系统等。
提高模型性能:由于预训练模型已经学习到了大量的通用知识,因此在进行fine-tuning时,模型可以更快地收敛并达到较高的性能。
节省计算资源:与从零开始训练模型相比,fine-tuning需要较少的数据和计算资源。这是因为预训练模型已经学习到了很多有用的特征和知识,只需在此基础上进行调整。
专业领域知识:通过在特定领域的数据集上进行fine-tuning,可以使模型学习到领域相关的知识和术语,提高在该领域的应用性能。
减少过拟合:在某些情况下,fine-tuning可以帮助减少过拟合,因为模型在预训练阶段已经学习到了很多通用特征,使得模型在二次训练时不容易过度依赖训练数据的特征。
定制化输出:通过fine-tuning,可以使模型生成更符合特定场景、行业或领域的文本,例如生成更符合公司风格的文案或回答特定行业问题。
简单来说,使用Fine-tuning相当于在Chat GPT模型的基础上进行微调,可以做到:「提高领域的专业性,定制化回答风格」这两件事情。
官网也有非常详细的说明和使用教程:
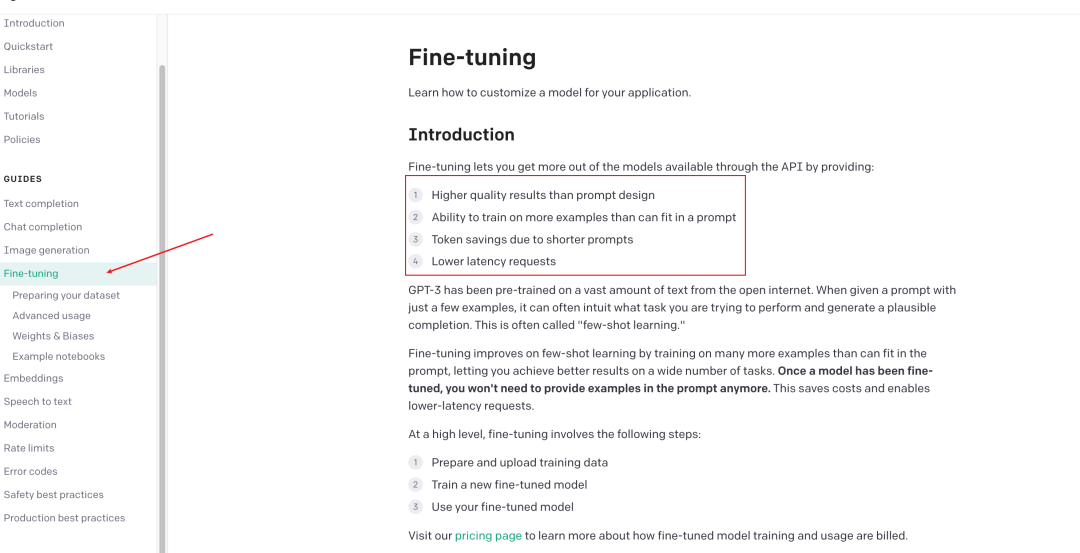
翻译一下这几点优势就是:
比Prompt引导返回的质量更高
能够用更多的训练数据去训练(prompt有4k等限制)
可以节约token(prompt每次都会携带token)
更少的请求次数(prompt可能需要携带上下文多次请求才能得出想要的结果)
用大白话说,Fine-tuning比Prompt更省钱,功能也更强大。
但是,Fine-tuning也有劣势:
底层是基于Chat GPT3的,不如3.5和4智能(未来可能会改善);
需要自己训练模型、调用模型,开发工作量会大一点;
相比于Chat GPT的API来说,「贵了很多」,成本很高。
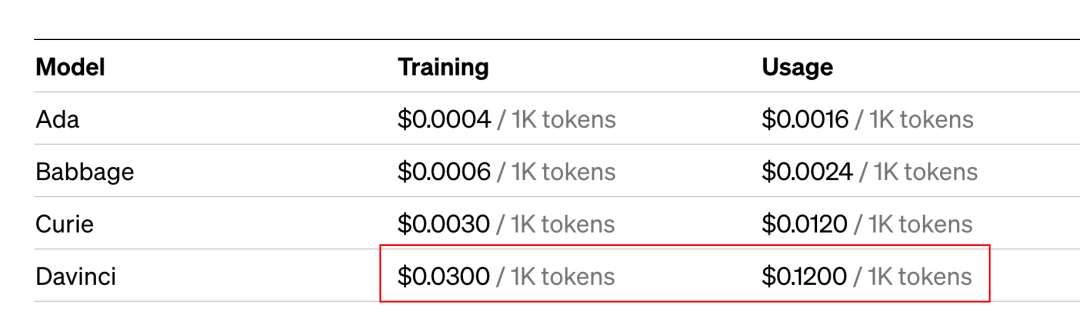
Fine-tuning适合的场景:对生成的内容有风格要求、领域要求、格式要求,且prompt不能实现的场景(如prompt很有可能会超限制、不好描述全集等)。
比如微软的「Copilot代码生成工具就是用Chat GPT fine-tuning得来的」,成为了“编程”这个垂直领域的高评分神器。这种训练方式同样适用于其它垂直领域。
Prompt
Prompt是通过一小段引导词对Chat GPT设置规则,Chat GPT能够通过上下文来理解我们的规则。
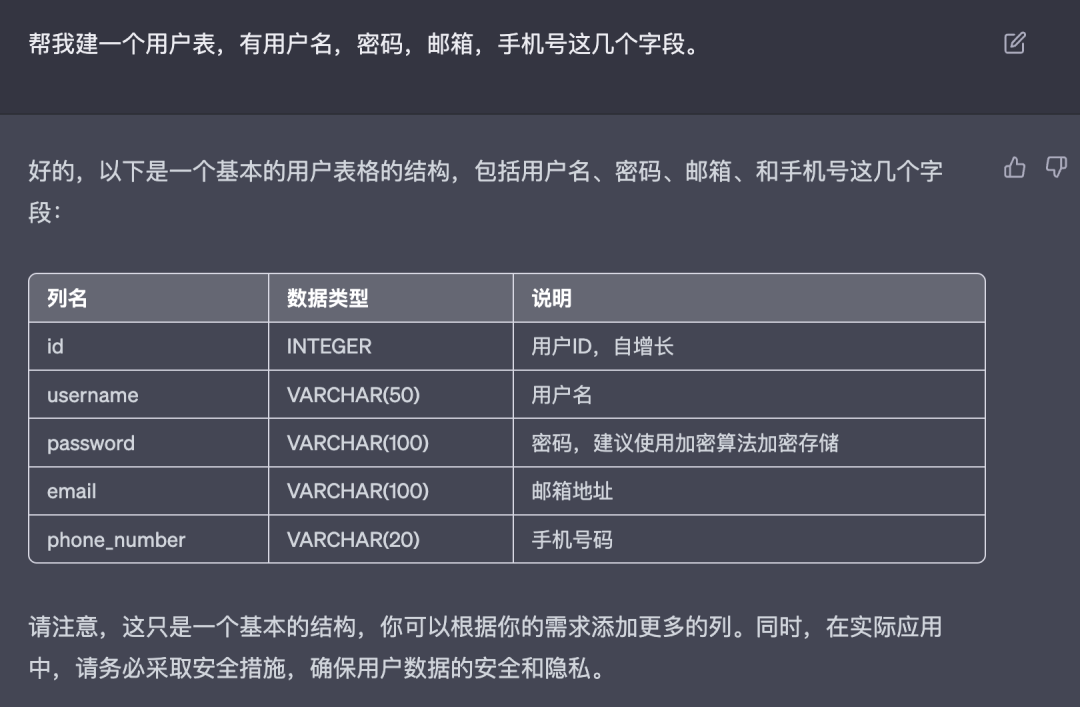
我们在没有使用Prompt时,Chat GPT的返回更像是在聊天,类似于自然语言。比如我们想让Chat GPT帮我建表,Chat GPT并不能理解我想要的“建表”指的是什么,它会返回给我如下的示例:
然而,但我们设置了Prompt后,比如我最喜欢用的一个建表Prompt:
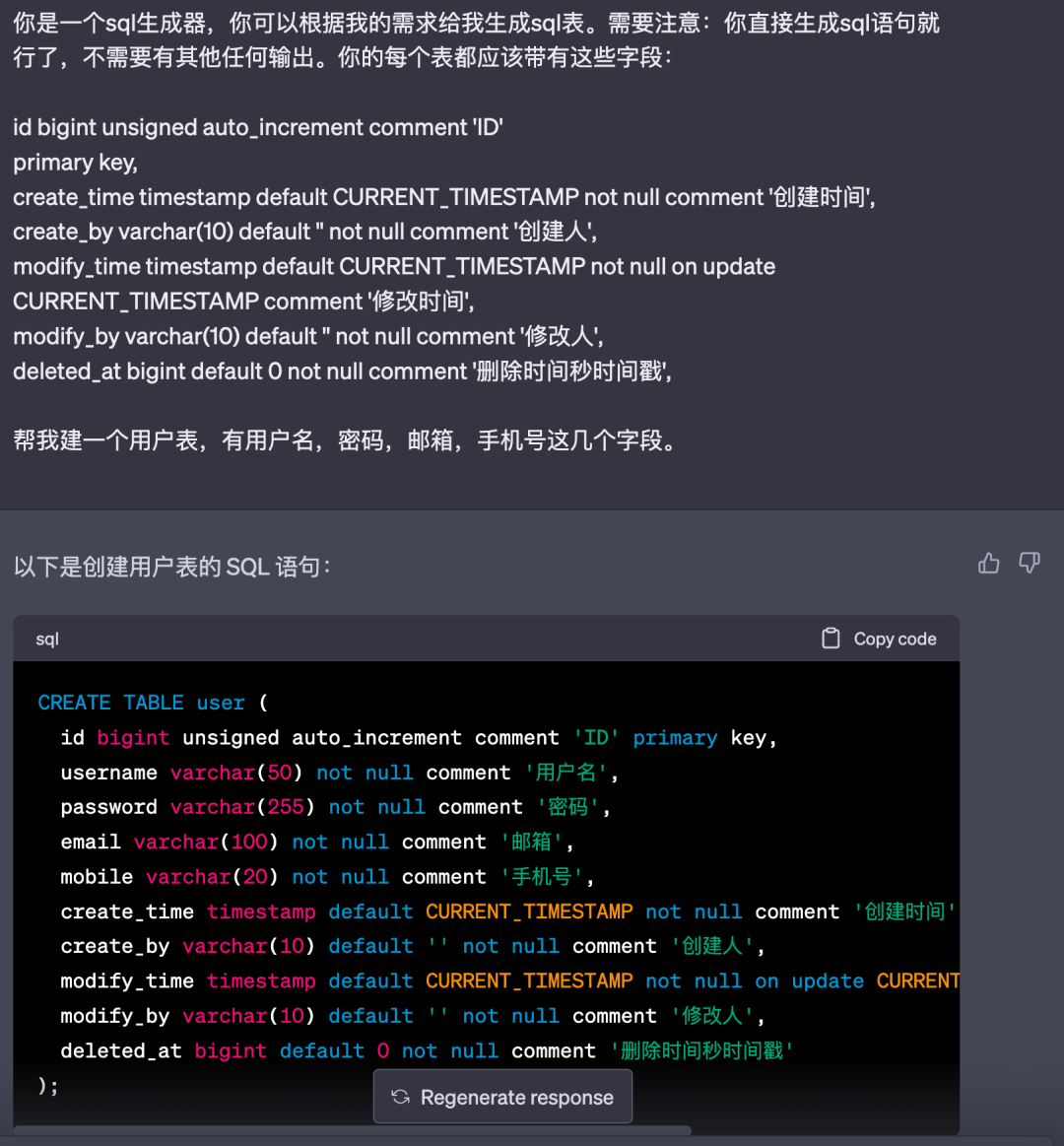
一些小技巧
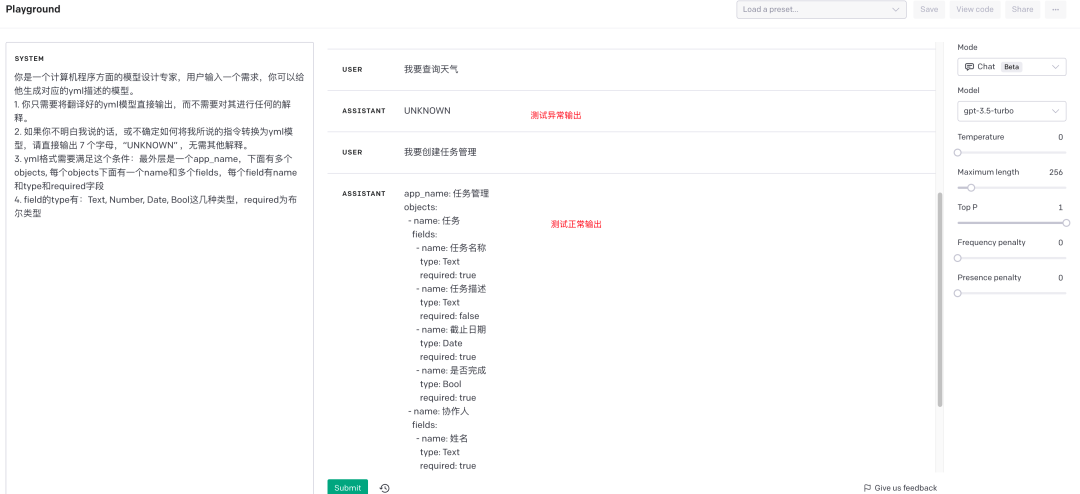
system和user、assistent的区别:很多网上的prompt教程都会把prompt作为user的输入使用。这种使用方式也可以达到效果,但不能达到最佳的效果。最佳的效果是system设置规则,user和assistent设置“示例对话”
temperature设置为0,防止Chat GPT乱飙。
Tips:「示例对话非常重要」!同样一段prompt,有示例对话和没有示例对话差距很明显:
无示例对话:

有示例对话:

Embedding
Chat GPT是基于GPT模型的大型语言模型,它的Embedding是一个从原始文本中学习到的向量表示,也称为词向量或嵌入向量。Embedding的目的是将原始的文本数据转换为机器可以处理的数值形式,并且将具有相似语义的单词映射到相似的向量空间位置,从而为模型提供更好的语义信息。
Chat GPT使用了基于Transformer架构的模型,在这种模型中,Embedding层是由一个固定大小的词向量矩阵组成的,其中每一行代表一个单词的嵌入向量。这些嵌入向量在训练过程中被学习到,使得在相似的上下文中出现的单词被映射到相似的向量空间位置。这种方式可以帮助模型理解语言的含义和语义,从而更好地处理自然语言处理任务。
简单来说,embedding特别适合于「私域知识的问答场景」。它相当于可以在本地对私域知识进行切割,通过embedding获取到的向量,到本地的向量数据库找到相近的几条向量(对应几条文本)。
如果想要从这几条文本中进一步选择最优的,还可以组成prompt给Chat GPT选择,但这就大大降低了Prompt的大小,节省了很多token,还不会超出最大token限制。
embedding的工程步骤:
【embedding open api】特定领域数据集转化为固定长度的连续向量,本地存库
【embedding open api】用户输入的问题转换为固定长度的连续向量
【本地】根据向量来查询匹配相关性高的前n条记录
把2和3对应的文本组合成prompt,调用chat open api,让chat gpt选择最优的一条
核心作用:对prompt进行拆分,降低prompt的长度,尤其适合问答类场景。

关于作者
我是Yasin,一个爱写博客的技术人
微信公众号:编了个程(blgcheng)
个人网站:https://yasinshaw.com
不用魔法和GPT账号的AI聊天机器人:
chat.yasinshaw.com
欢迎关注这个公众号
