SENET介绍
SENET是在论文《Squeeze-and-Excitation Networks》中提出来的,应用在图像处理上的。主要思想:通过建模channel之间的关系来矫正channel的特征,以此提升神经网络的表征能力。(原文:adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels。在图像中,一个channel可以先当于图像的一种特征。)特征矫正是使用全局的信息去加强有用的特征,淡化无用的特征。(原文:use global information to selectively emphasise informative features and suppress less useful ones)

图1展示了整个senet架构。C/C'是channel个数。 Ftr是一个transformation结构,比如:一个卷积操作、inception、resnet。
senet首先分为两步,首先是squeeze,然后是excitation。
squeeze是压缩每个channel的特征作为该channel的descriptor,采用的方法是均值池化,对channel里面的特征求均值:

excitation操作是捕捉channel之间关系:
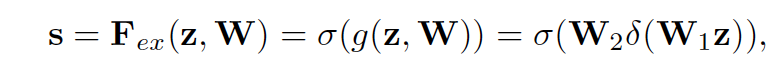
论文使用的是一个gate网络,通过两层神经网络学习每个channel的权重,激活函数依次选为ReLU和Sigmoid。 W1=RCr×C 有维度递减的作用,将C维的特征进行压缩,充分捕捉channel之间的关系。 W2=RC×Cr还原维度。gate网络输出s是C维的向量,每个值是对应的channel的权重。输入的特征最后会乘上对应的权重,无用的特征会被趋近于0:


senet可以作为一个基础的神经网络组件。图1是作为一个普通CNN层的组件。图2中展示了如果如何将senet放在inception和resnet中。
个人感觉,senet有点像self-attention,通过自身的信息学习attention权重。
GateNet
首先:『attention』和『gate』本质上的区别是什么?
其实就是单体attention或者多提attention
言归正传,这篇博客将要介绍新浪微博张俊林大佬团队提出的GateNet模型,
两种类型:embedding层Gate(Feature Embedding Gate)和 隐藏层Gate(Hidden Gate)。
embedding层Gate(Feature Embedding Gate)
顾名思义,embedding层Gate就是把Gate网络施加在embedding层,
具体又可以分为两种:bit-wise和vector-wise。
bit-wise就是每一个特征的embedding向量的每一个元素(bit)都会有一个对应的Gate参数,
而vector-wise则是一个embedding向量只有一个Gate参数。

假设样本有两个特征,每个特征embedding维度取3,
用个图来形象的对比下bit-wise和vector-wise的gate的区别:
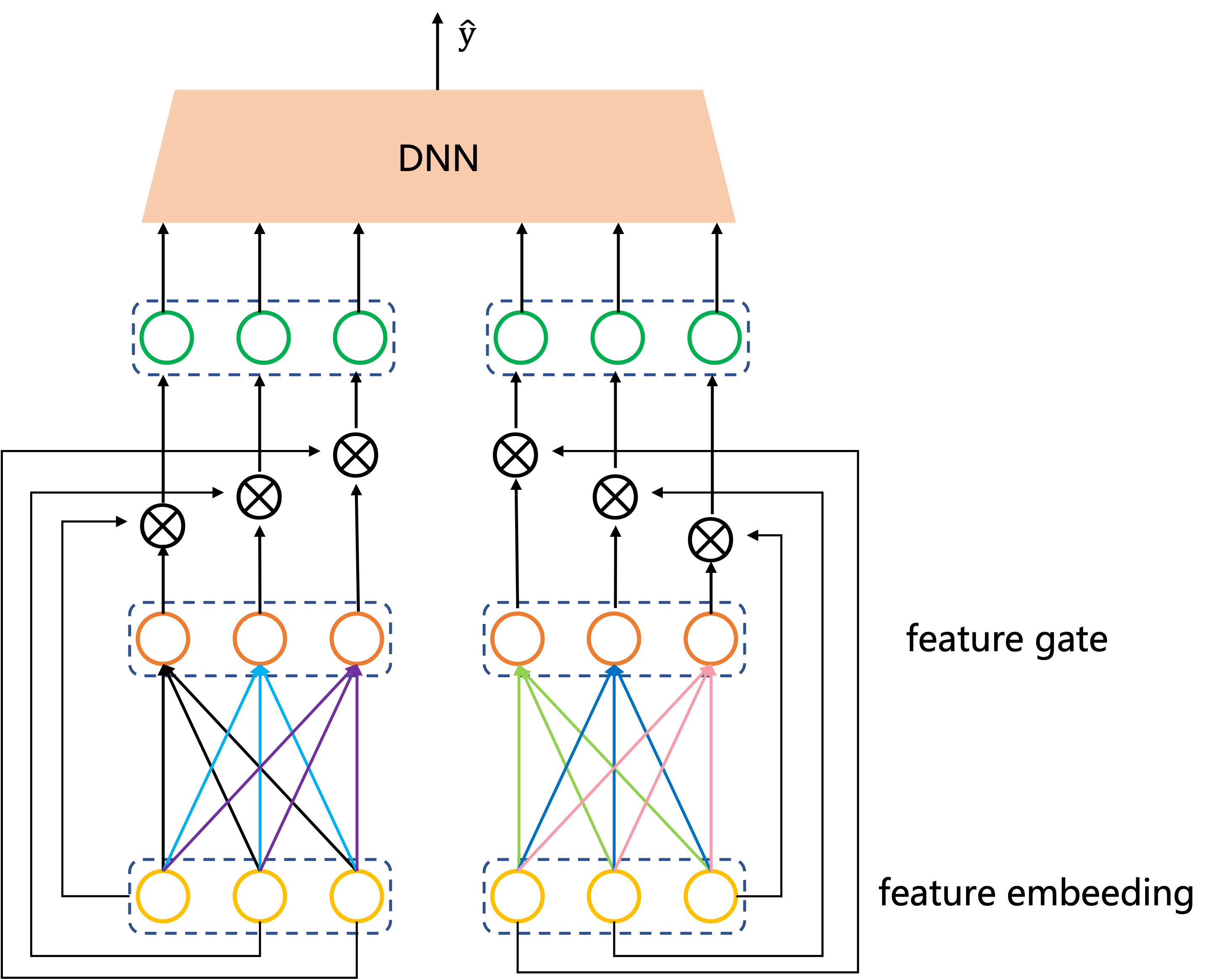
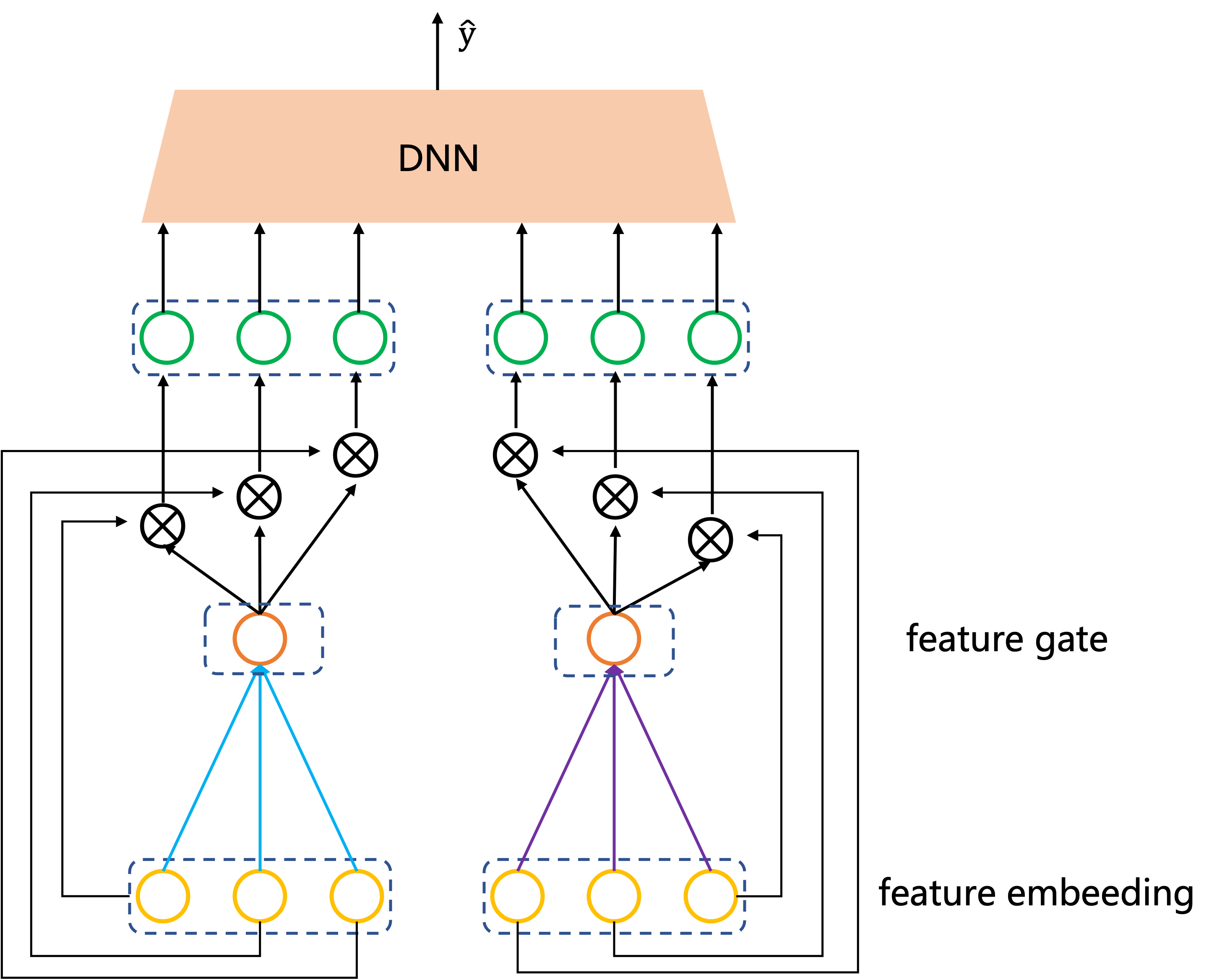
值得一提的是,论文中关于gate网络参数是否共享提出了两个概念:
field private: 所谓field private就是每个特征都有自己的一个gate(这意味着gate数量等于特征个数),
这些gate之间参数不共享,都是独立的。图1、图2中gate的方式就是这种。
field sharing: 与field private相反,不同特征共享一个gate,只需要一个gate即可。
优点就是参数大大减少,缺点也是因为参数大大减少了,性能不如field private。
通过论文中给出的实验表明,field private方式的模型效果要好于field sharing方式。
隐藏层Gate(Hidden Gate)
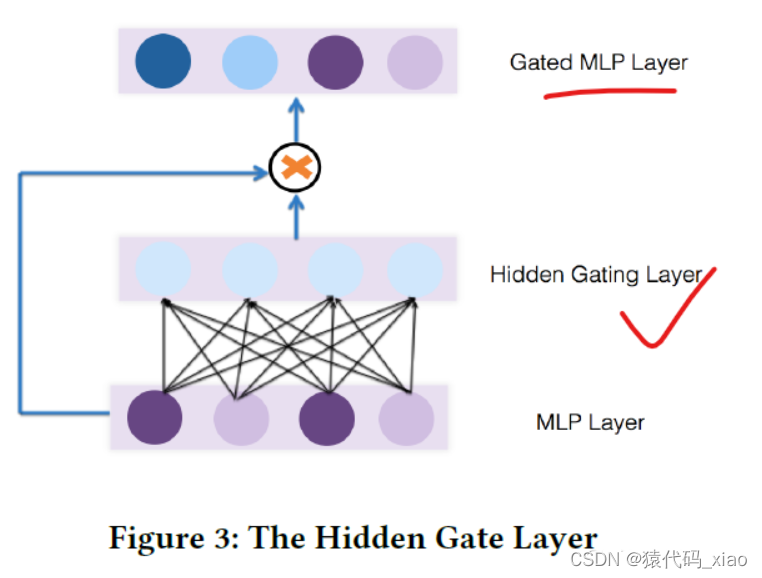
另外一种施加Gate网络的地方就是MLP的隐藏层,
计算步骤公式直接看1.1中bit-wise就可以。
GateNet论文实验结论:
论文中做了大量的实验来验证了几个问题(只基于论文的实验结论,具体业务场景可能结论不一样,大家参考下就可以)
问题1:gate参数field private方式与field sharing方式那个效果好?
实验结果表明,field private方式的模型效果优于field sharing方式。
问题2:gate施加方式 bit-wise与vector-wise哪个效果好?
在Criteo数据集上,bit-wise的效果比vector-wise的好,但在ICME数据集上得不到这样的结论。
问题3:gate施加在embedding层和隐藏层哪个效果好?
论文中没有给出结论,但从给出的数据来看在隐藏层的比在embedding层效果好。
此外,两种方式都用的话,相比较只用一种,效果提升不大。
问题4:gate网络用哪个激活函数好?
embedding层是linear,隐藏层是tanh。
自己实践中一些结论
我们自己的场景下(多任务下,ctcvr)实践结果来看,有几个结论仅供参考:
gate作用在embedding层与输入层之间效果比作用在隐藏层之间好。
gate使用bit-wise效果好于vector-wise。
gate网络的激活函数sigmoid无论在收敛性和auc增益上都要显著好于其它的激活函数。