note
- 连续特征处理:facebook DLRM模型,对连续值的处理方式是把所有的连续值输入到一个神经网络,然后通过神经网络把它压缩到一个embedding维度大小的一个向量上,然后将Embedding和其他离散特征Embedding Concat起来,再做后面根据它的模型去做不同的计算;同时离散化(转为类别变量)然后送入embedding是常见操作。
- 分布式并行训练:数据并行;多卡切分;CPU的内存来存embedding,然后用GPU来存MLP等。
- 本文概况:
- 怎样去结合数据设计更好的模型,让模型更有针对性。
- 如何进一步提升训练效率,包括怎样去利用更多的数据,以及增快模型迭代效率。
- 怎样去增强数据处理、选择、模型调优的自动化的程度,从而解放业务或者算法同学,更多地去关注模型数据、算法和策略。
文章目录
一、CTR模型
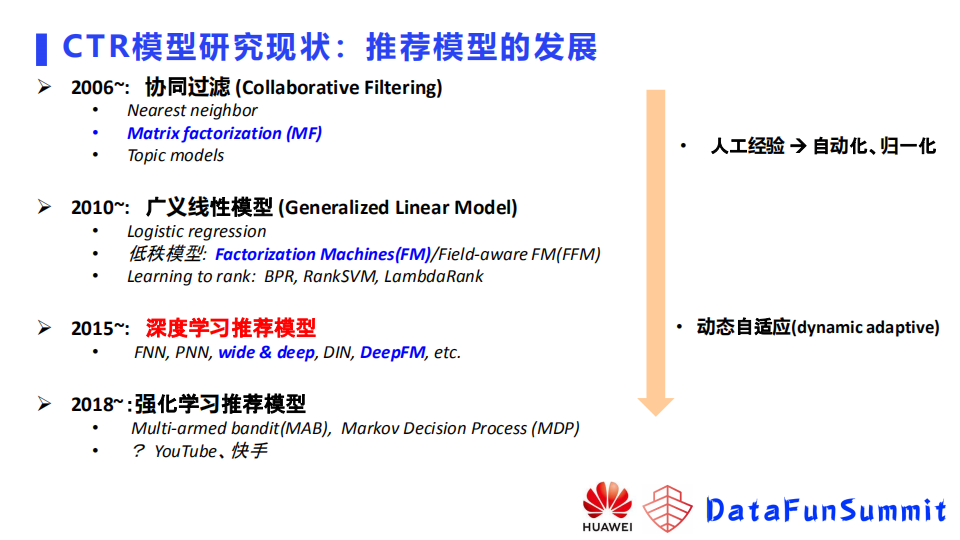
推广搜领域中CTR点击率预估模型的发展历史如下图,逐渐从人工经验向自动化,深度学习模型的归一化,业界期望用自适应模型解决业务问题。
2021年IJCAI一篇综述,张伟楠和华为诺亚方舟实验室的论文,将深度学习CTR模型分类:
- 基于组合特征挖掘的模型;
- 针对用户行为的模型;
- 自动架构搜索的模型。
1.1 用户行为挖掘
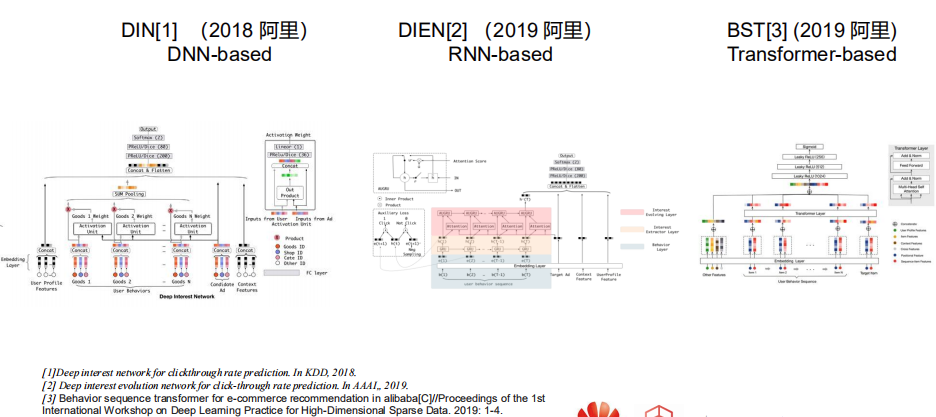
- 阿里妈妈17年的DIN,用dnn里的pooling将用户历史行为建模
- 19年阿里妈妈在DIN上增加RNN形成DIEN,规避了DIN这种将过去历史行为都等同看待的劣势,拟合序列关系
- 19年阿里BST加入transformer
1.2 组合特征挖掘
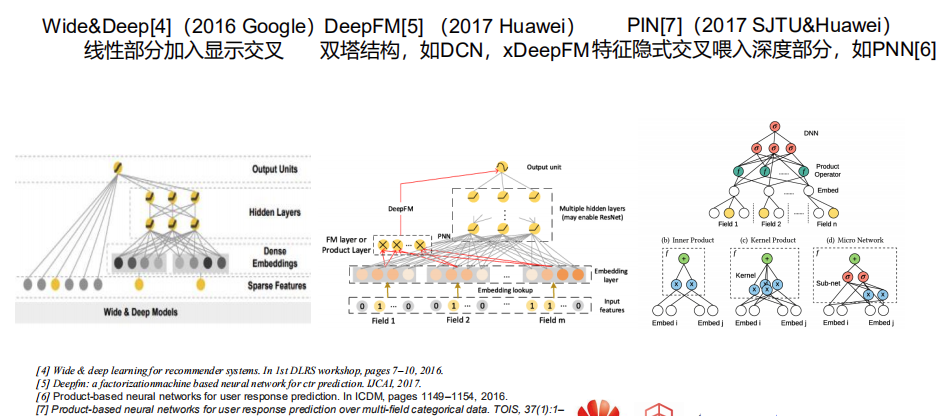
- wide&deep的wide特征之间笛卡尔积相乘后构建出新特征,加入到线性部分;当下次组合特征出现时,直接把它的权重取出做预测
- deepfm这种双塔范式,后面也衍生DCN、xDeepFM等,建模特征之间的组合关系
- PNN网络,利用分解模式构建组合特征后,还会把输出喂入MLP,拟合特征之间关系
1.3 高效利用数据
- 组合特征建模:
- 显式的交互特征喂入深度模型可以带来提升(CAN)
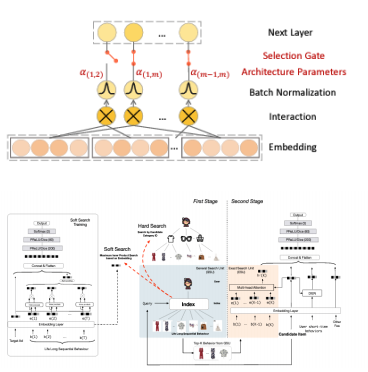
- 模型需要筛选交叉特征重要性(华为诺亚方舟2020年发的AutoFIS,针对交叉特征加了一组参数,用来自动去学哪些特征重要,哪些特征不重要。通过第一阶段的搜索,筛选出重要特征,把不重要的去掉,再重新输入到模型,这样做效果有明显提升。)
- 用户行为建模:
- 针对行为数据加入检索模块SIM或者UBR
- 如上图所示,用户的行为进来之后,通过一个行为建模的模块,比如RNN或者是transformer,就会得到一个用户的embedding,再和其他的特征一起注入到模型去做预测。这里的检索基于一个target,即预测目标,去对用户的行为做了一个筛选或者加权。基于这样的操作,模型会有很明显的提升。

1.4 处理大embedding
- 思路一:怎样把embedding变小,也就是将embedding压缩;
- twitter在Recsys2021发表的double hash,把特征分为高频和低频,因为高频特征相对占比娇小,给每个高频特征分配一个独立的embedding(所占空间不大),对于低频特征使用double hash压缩,减少冲突
- 百度在sigmod2021基于int16训练embedding参数,即基于低比特参数模型训练
- 探索类工作:谷歌在kdd2021上发的DHE模型, 去掉了embedding table
- 思路二:怎么用更新的分布式架构去更高效更低成本的去训练大embedding。
- 用的最多,基于GPU这种Horovod去数据同步
- 腾讯发表于SIGIR2020的DES通过模型结合硬件设计了一个分布式的方案。英伟达提出基于cude直接写了一个HugeCTR。
二、连续值处理(Continuous Feature)
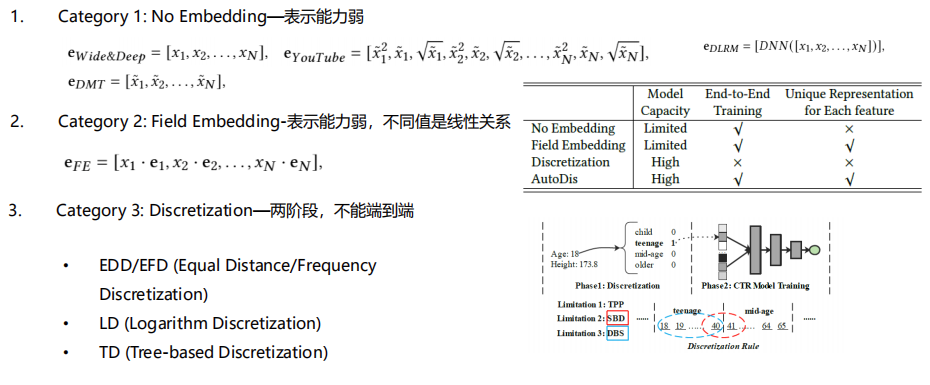
- 第一种方法,No Embedding。
- 第一个是wide&Deep,在它的介绍里面,使用的是原始值,
- 另外一个是谷歌的YouTubeNet,它会对原始值做平方开根号这些变换。
- 另一个是facebook DLRM模型,对连续值的处理方式是把所有的连续值输入到一个神经网络,然后通过神经网络把它压缩到一个embedding维度大小的一个向量上,然后将Embedding和其他离散特征Embedding Concat起来,再做后面根据它的模型去做不同的计算。
- 京东的DMT模型,他们的网络是使用了归一化的输出,这种方法表示能力比较弱,因为它这里其实没有对原始的延续特征做一个很好的表示。
- 第二种处理连续值的方法是Field Embedding;
- 每个域有一个Embedding。某个域的Embedding是该域的一个连续值,乘上它的域的Embedding。这类方法的问题是表示能力比较弱,然后不同值之间是一个线性的关系。
- 第三类的方法就是离散化。离散化可以有很多方法,比方说等频、等距和取log,或者基于树的模型去做一个预训练。但这类方法有两个问题:
- 首先,就是它是两阶段的,离散化的过程不能端到端优化;
- 另外,有一些边界的问题,如下图所示的例子,一个年龄特征,假设我们按40,41来分,40以下的我们称之为青年,41以上的成为中年,其实40和41,它们是很接近的年龄,但是因为我们的离散化的方法,把它分到两个不同的桶里面,可能学到的Embedding是差异比较大的Embedding。
更多参考:华为提出的一个连续值Embedding的方法AutoDis。看线上效果,在点击率及eCPM这两个指标上都是有一个百分位的提升。
三、交叉特征建模(Interaction Modelling)
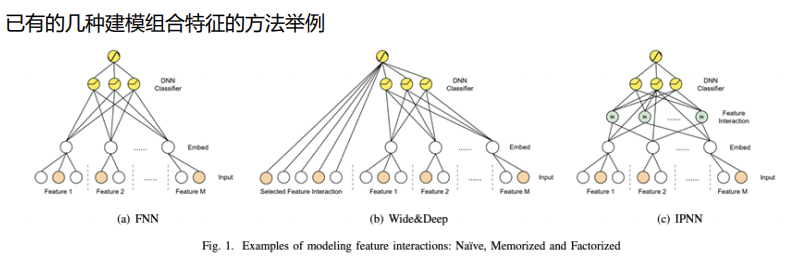
- 第一类像FNN模型,即不建模,每个特征有一个embedding,所有的特征embedding后concat拼接输入网络,后面网络自己去学,想学到什么就是什么。
- 第二类像wide&deep模型,这里统称为基于记忆的方法,就是去显示的构造组合特征,特征做交叉做笛卡尔积,然后把新构造的特征输入模型。模型就会记住这个特征,这个信号就比较强。
- 第三类方法就是基于分解的方法,例如IPNN模型,对不同的域之间的交叉关系,通过乘法的方式去做建模,得到的乘法结果会和原始embedding一起喂入到后面的MLP,然后来再次去做一个组合。不同的特征之间是不是都应该组合,或者说怎么去组合,如果我们去试的话,需要去做很多实验,能不能自动判断特征是不是要组合,以及它们之间应该用哪种组合这种关系去学到呢。
更多参考:华为提出的OptInter交叉特征建模。在Criteo、Avazu、iPinYou等经典CTR数据集效果不错。
四、大Embedding模型训练(Distributed Training)
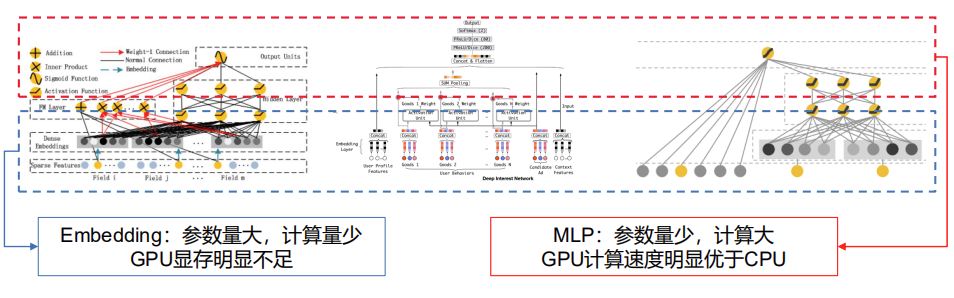
推荐模型一般两部分:参数embedding(参数量大,计算量较少,但是GPU显存一般存不下,如上面有的模型几百个G,V100有32个G,土豪忽略);MLP参数量较少,计算量较大。
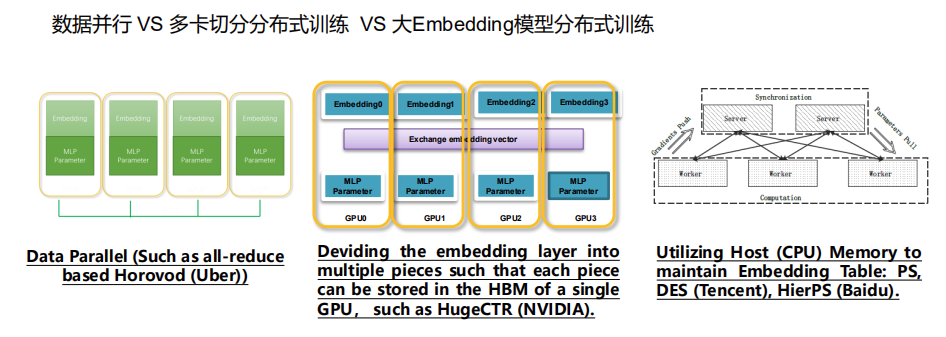
高维稀疏特征导致embedding较大。较常用的并行训练方法:
- 第一类是数据并行,例如基于all-reduce的Horovod,这种方式在每个GPU卡中存一份完整的模型副本,需要把模型都能存得下,我们模型如果变得大,GPU显存不足以存下完整模型,即使模型可以存得下,比方说有十几G几十G,基于这样一个大小的模型,它在做通信的时候,它的通信的时延很可能比它计算带来的时间的减少还要来得多,也就是说你增加节点不一定带来性能的一个提升。
- 第二类是NVIDIA提出的,之前他们的方案还是一个多卡切分的方案,但现在已经支持了一个CPU的embedding的一个存储,他们这个方法把embedding切成多份,然后在每个卡的显存里面存一部分,MLP在每个节点都存一个完整的模型。embeding通过一个all to all的通信, MLP通过all-reduce通信,这个方案有一个问题就是当它的模型很大时需要的GPU卡很多,从而它的成本也会很高。
- 第三类方法是使用CPU的内存来存embedding,然后用GPU来存MLP。CPU负责存储,MLP来负责前项以及反向的梯度的计算。对于这种方法,如果我们采用同步训练的话,它有一个问题就是因为embedding是存在CPU侧的,需要从CPU去传输到GPU,梯度需要从GPU回传到CPU,他们之间通信的时延是很高的。
Reference
[1] 郭慧丰博士. 华为技术分享.点击率预测模型Embedding层的学习和训练