Bart 训练和预测的逻辑是不一样的,那么它们的逻辑是怎么区分的?
训练的时候
- 并行
因为要根据之前的序列得到后续的序列,于是可以采取并行训练的方式。比如说,我们的目标序列长度是N,那么并行训练就是搞一个N*N 的矩阵,但是这个矩阵是一个下三角的矩阵,这样就可以解决生成当前词看见后续词的问题了。
是通过下面这个方法得到decoder_attention_mask,
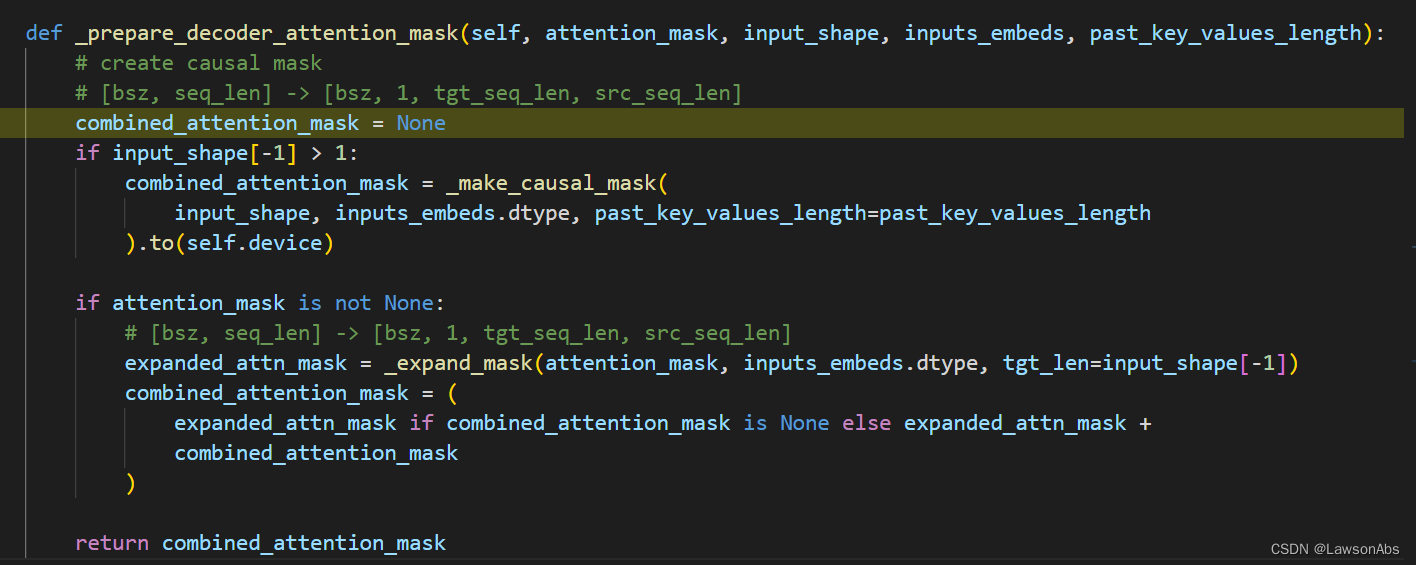
详细说说下面几个参数:
input_shape: 维度信息是 [bsz,tgt_len],
inputs_embeds
past_key_values_length
程序会进入第一个if逻辑,进入到 _make_causal_mask() 中
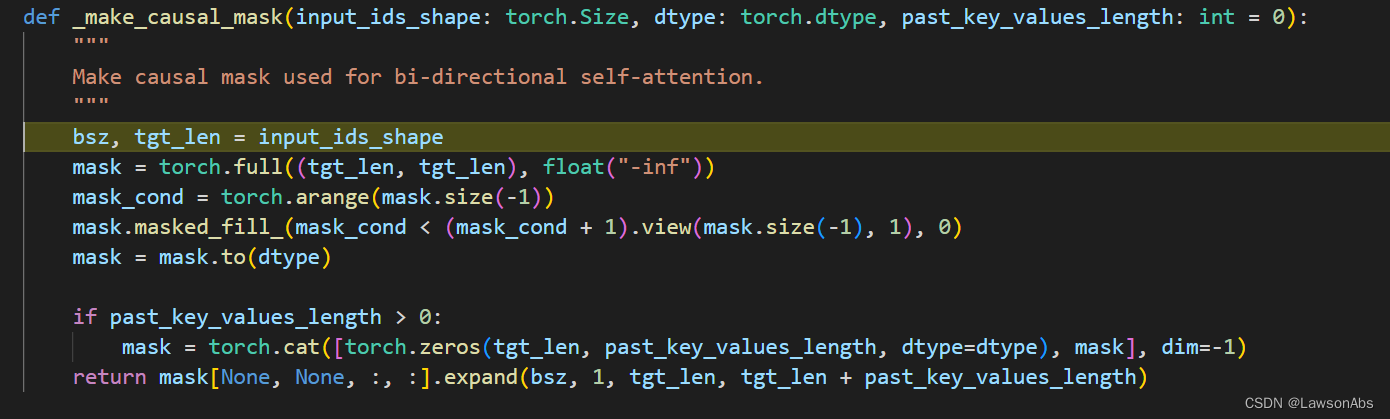
full()函数会得到一个指定初始化值的矩阵。
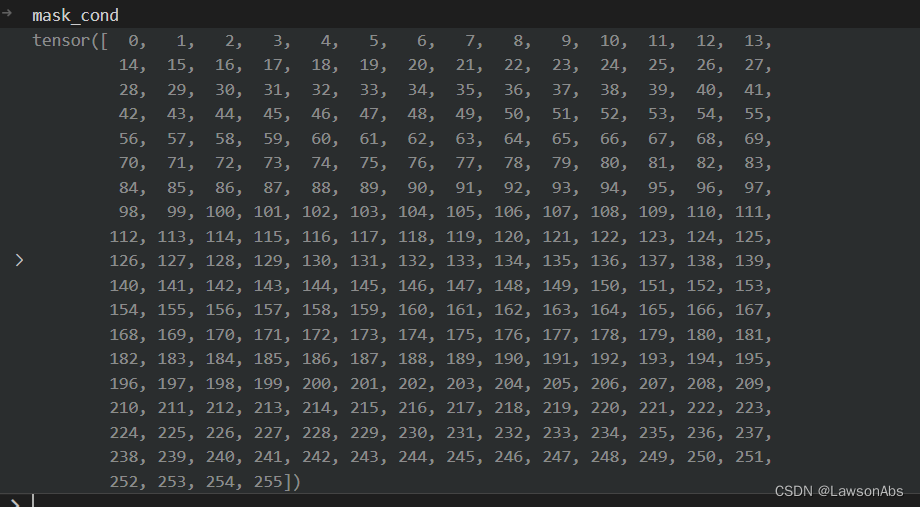
arange()函数会初始化一个从0到 mask.size(-1) 的值,在本代码中就是一个如下的序列:
再经过一次的比较运算就得到了mask矩阵:
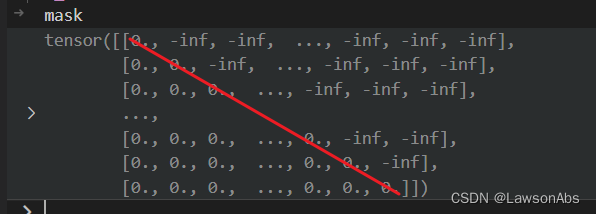
得到这个mask矩阵之后,需要根据bsz进行扩展一下,扩展的函数就是expand。最后得到的combined_attention_mask,为啥这个combined_attention_mask 为啥需要 past_key_value_length ?
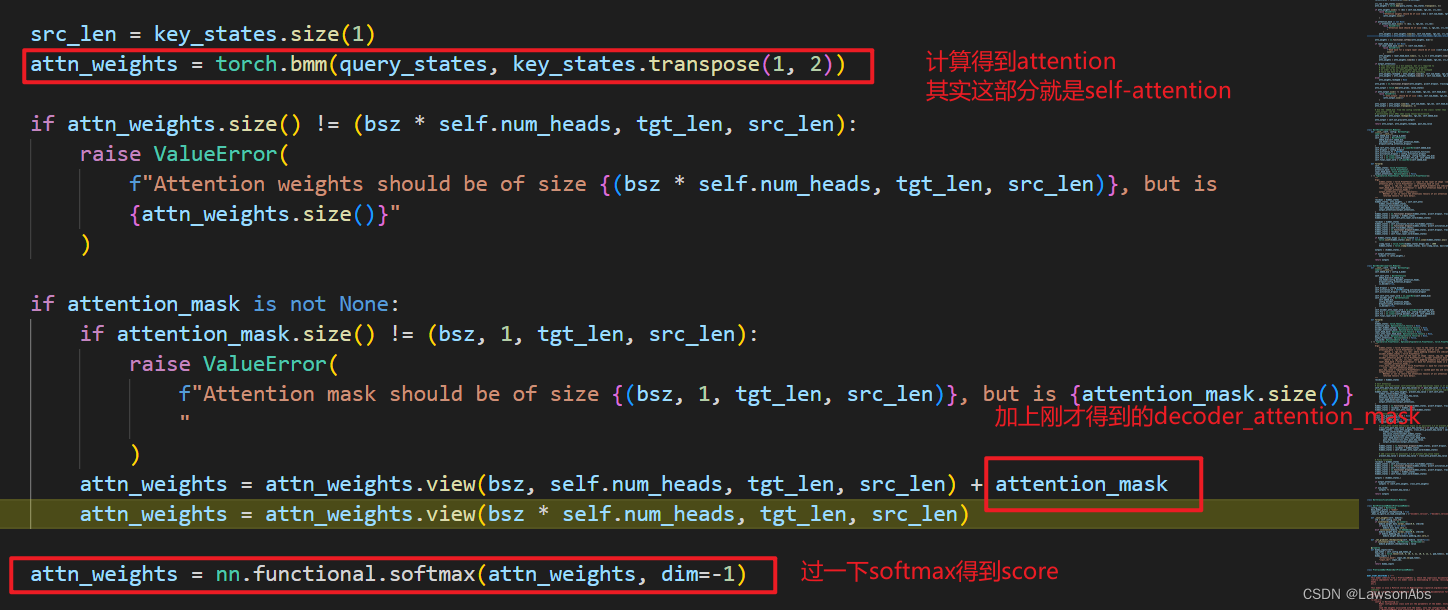
在得到这个 attention_mask 之后,就送入到decoder的第一层self-attention 中,计算得到每个位置的输出向量:
inference的时候
因为inference的时候是自回归的,无法并行。
bart的词表

decoder 中传入的 encoder_attention_mask 是什么作用?
如下图所示
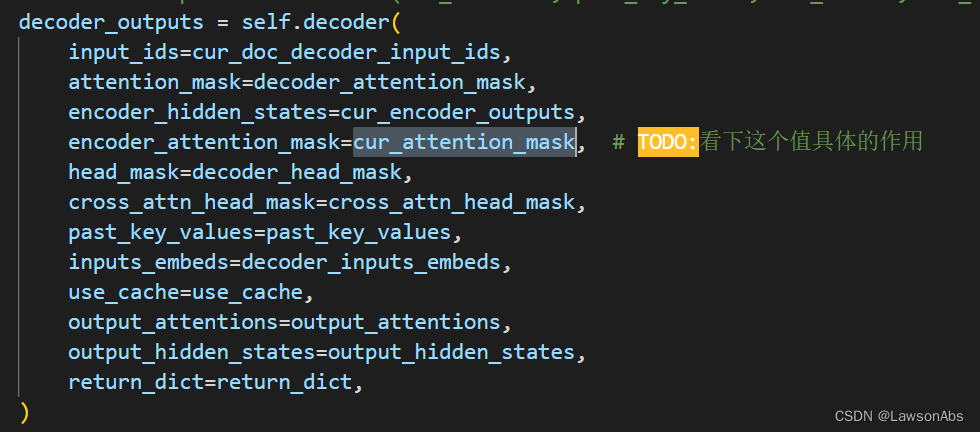
我们先看看后续的代码是怎么用这个变量的。
在decoder的代码中,将encoder_attention_mask 变成了 [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len] 这个维度。
这个是交给cross-attention 使用。
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
#这个是self attention 计算得到的结果
hidden_states=hidden_states,
# 这个是encoder 的结果,tensor 维度是 (bsz,seq_len, hidden_dim),这个值是用于后面计算key value 的
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
layer_head_mask=cross_attn_layer_head_mask,
past_key_value=cross_attn_past_key_value,
output_attentions=output_attentions,
)
