背景:

近年来,深度学习研究和产业化得到迅猛发展。随着移动端算力提升,实时性需求,以及用户数据隐私方面的考量,导致越来越多的推理任务从云端转移到移动端。移动平台上深度学习推理需要解决硬件平台、驱动、编译优化、模型压缩、算子算法优化和部署等问题。许多企业正在开发面向移动端的开源深度学习框架,如小米MACE、腾讯优图NCNN/TNN、阿里MNN和谷歌TensorFlow Lite等。现有的推理平台通常存在与第三方库和硬件平台驱动相关的适配、模型验证,数据交互等问题,导致其优化、部署、维护和升级繁琐。
对于移动端的图形图像类AI应用,由于计算能力、低功耗、I/O带宽、内存架构和访问方式等限制,现有的推理框架很难满足产品对实时性、性能和功耗的严格要求。为满足移动端图形图像后处理高效AI推理的需求,提高效能并降低成本,我们在《面向AI图形的轻量深度学习推理引擎 ShaderNN》[1]一文介绍了基于OpenGL 后端的GPU Shader的高效推理引擎ShaderNN一期项目,在这篇文章中,我们将介绍ShaderNN 2.0提供的新增功能,主要技术特性(高性能,轻量性,通用性和易扩展)、性能功耗优势以及一些典型的应用场景。
目前主流移动端处理器的性能提升,除了得益于CPU主频提升和多核化以外,更多是通过配置多核GPU硬件作为图形渲染和图像处理加速器,例如ARM Mali GPU,Qualcomm Adreno GPU和Apple A15。主流移动端推理框架也基本都提供了基于GPU的推理加速,其中广泛采用的GPU编程接口有OpenGL、Vulkan和OpenCL。移动端主流的图形及图像处理类应用主要是基于OpenGL 或 Vulkan 图形栈开发的。推理框架如果采用其他加速方案,如NPU/DSP、OpenCL,在与上述应用进行整合时,面临的主要问题就是数据交互方面的开销。ShaderNN 一期推理框架基于OpenGL,可以直接处理OpenGL texture并输出OpenGL texture。Vulkan作为新一代的图形栈,是一个跨平台的底层图形和计算API,而OpenGL是一套更高级的图形API。下面是Vulkan相对于OpenGL的几个优势:
-
更低的开销:Vulkan设计的目标是提供更低的CPU开销和更高的多线程性能。它允许开发人员更好地控制硬件资源,如显存和线程,从而减少驱动程序的开销,提高应用程序的性能。
-
显式控制:Vulkan要求开发人员更加显式地管理图形渲染管线和资源。这种显式控制使开发人员能够更好地优化和管理资源,以适应不同的硬件平台。
-
支持多线程:Vulkan支持多线程渲染,允许开发人员更好地利用多核处理器。这可以提高图形和计算任务的性能,并实现更好的并行处理。
-
更好的内存管理:Vulkan提供了更灵活的内存管理机制,使开发人员能够更好地控制内存分配和使用。这使得开发人员可以更有效地管理显存,减少内存碎片化,并优化应用程序的性能。
-
更好的异步支持:Vulkan允许开发人员在不同的任务之间进行更好的异步处理。这使得开发人员可以更好地利用GPU的计算能力,同时执行多个任务,提高应用程序的性能和效率。
总的来说,Vulkan相对于OpenGL提供了更低的开销、更好的多线程支持、更灵活的内存管理和更好的异步处理能力。这些特性使得Vulkan在需要更高性能和更底层控制的图形图像应用程序中成为更好的选择。Vulkan还推出一些高性能特性如光线追踪扩展等的原生支持,受到越来越多的软件和硬件厂商的欢迎和支持,被应用于最新的游戏、图形图像等应用。为满足越来越多的移动端基于Vulkan应用的AI后处理的需求,它同样需要一款轻量、可定制、可与应用Vulkan渲染管线无缝衔接的推理引擎。面向这一需求,我们在一期ShaderNN 1.0 的基础上,添加了Vulkan 后端的支持,推出了首个支持OpenGL 和 Vulkan全图形栈 Shader 2.0移动端推理引擎,并于近期发布了开源的预览版。
一、ShaderNN 2.0 流程图
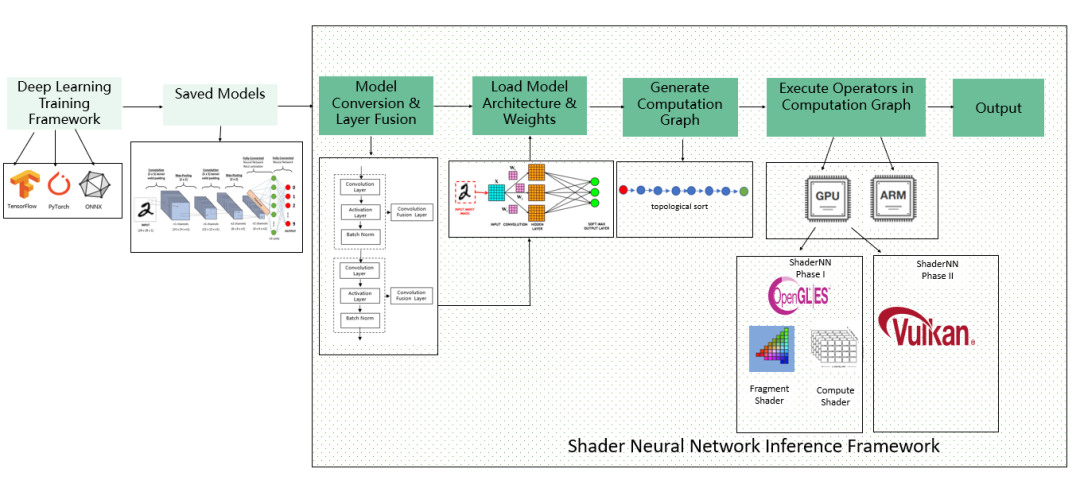
图1: ShaderNN 工作流程图
如图1所示,ShaderNN 整个工作流程可以分为模型转换和层融合优化、网络模型和权重加载解析、计算图生成、计算图算子的执行、推理预测返回相关结果。在编译阶段和运行阶段进行优化,推理引擎分别进行了优化。编译的优化包括Shader的编译和缓存优化,等效算子替换与融合等。在运行阶段,ShaderNN通过卷积优化、纹理重用、CPU和GPU 内存重用、数据结构布局优化、缓存及向量化优化以提升效能。
TensorFlow、或者PyTorch训练后导出的ONNX格式的模型,通过ShaderNN转换工具转换成ShaderNN支持的 JSON模型格式。在转换过程中,模型转换器解耦模型结构和权重,解析算子并做层间融合优化。在加载模结构和权重以后,推理引擎通过拓扑排序生成计算图。除少数算子通过CPU来实现以外,大多数算子交由GPU Shader来执行,在1.0中我们通过OpenGL后端的 Compute Shader 或者 Fragment Shader 来实现,在 2.0 中添加了Vulkan后端的 Compute Shader实现。
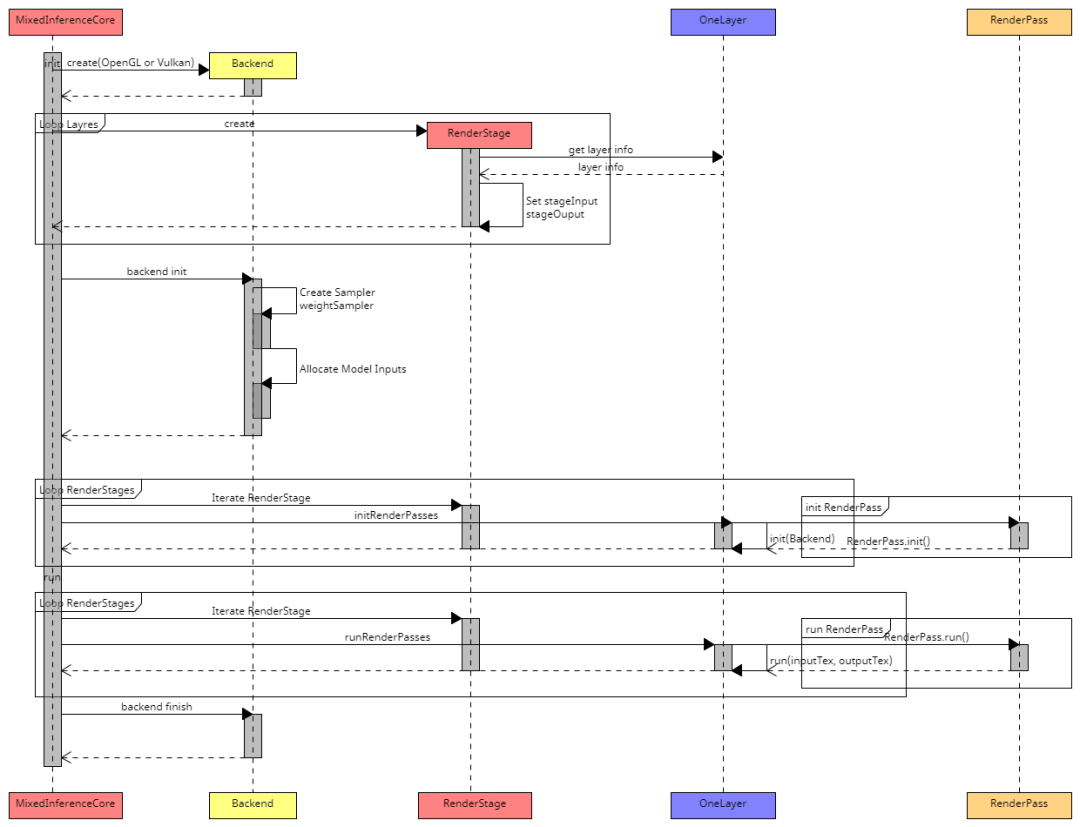
图2: ShaderNN 算法时序图
引擎的核心在MixedInferenceCore,它支持OpenGL和Vulkan后端,负责推理算子的具体实现。计算图的输入直接来自应用的图形纹理(texture),它的输出也是纹理,可供应用直接渲染。计算图上的每一个节点对应网络模型的一个Layer,每个Layer通过一个render stage 来计算。针对compute shader 和 fragment shader的管线不同,对于OpenGL fragment shader,每个render stage 包含一个或多个render pass,对于OpenGL 和 Vulkan compute shader,一个render stage 包含一个或多个render pass。Render pass最后的结果直接输出到纹理(texture)。
二、ShaderNN的创新
-
使用基于纹理的输入/输出,提供与实时图形管道或图像处理应用程序的高效、零拷贝集成,从而节省 CPU 和 GPU 之间昂贵的数据传输和格式转换,这对于移动平台上的实时应用程序至关重要。
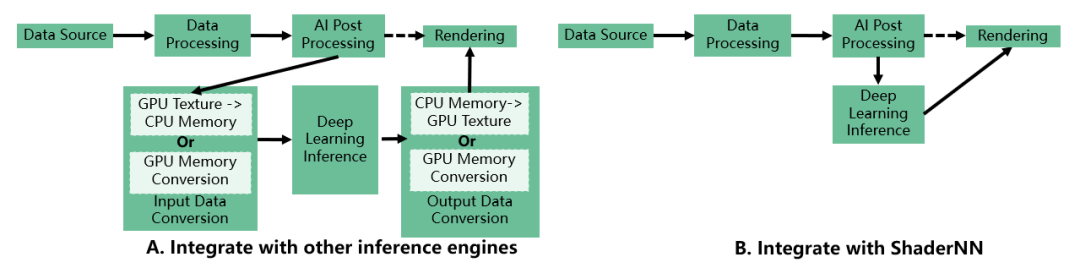
图3:ShaderNN同其它推理引擎同图形图像管线集成的对比
图3对比了ShaderNN和其它推理引擎与现有管线集成的不同,其它推理引擎通常提供了称为 Tensor 或 Mat 的通用数据结构作为输入和输出的格式,无法使用广泛用于图形和图像应用程序的纹理作为输入输出,需要进行格式转换或者GPU到CPU的来回转换,对于图像图像类的大输入的实时应用,这部分的开销是相当大的。而ShaderNN以原生纹理作为输入输出没有这部分开销,大大的提升了整体的性能。
2.首个支持基于 OpenGL 后端Fragment Shader推理实现,对于输入尺寸大、网络层次简单的网络如超分、降噪网络等相对其它推理引擎有显著的优势。
3.基于原生 OpenGL ES 和 Vulkan 构建,可轻松与图形渲染管线集成,最大限度地利用计算资源,适用于对实时性要求高渲染、图像/视频和游戏 AI 应用。
4.支持Compute Shader 和 Fragment Shader的混合实现,并能够对不同的模型层选择不同Shader以进行性能优化。方便用户定制新的算子。
5.纯GPU shader实现,无需依赖第三方库,可在不同GPU硬件平台上使用,可定制,方便优化、集成、部署和升级。
三、 性能和功耗
在《面向AI图形的轻量深度学习推理引擎 ShaderNN》[1]一文中,我们在4款手机同TensorFlow Lite OpenGL 后端对4个CNN常用网络进行了单次推理时间和功耗上进行了对比。在推理时间上,在Spatial Denoise和ESPCN方面优于 TensorFlow Lite 75%-90%;Resnet18 和 YOLO V3 Tiny模型在部分处理器芯片上优于TensorFlow Lite 50%。在功耗方面,Spatial Denoise、ESPCN、Resnet18 和 YOLO V3 Tiny对比时,可节省高达 80%、70%、55% 和 51%。
对于ShaderNN 2.0 里添加的Vulkan后端,我们和同样支持Vulkan后端的MNN推理引擎,分别在两款联发科和两款高通平台(见图4)上, 挑选了Resnet18, Spatial Denoise,Style Transfer, ESPCN 4种CNN常用模型, 进行了单次推理时间和功耗上进行了对比。

图4: 测试用移动平台
1、ShaderNN Vulkan 后端和 MNN Vulkan 后端性能对比
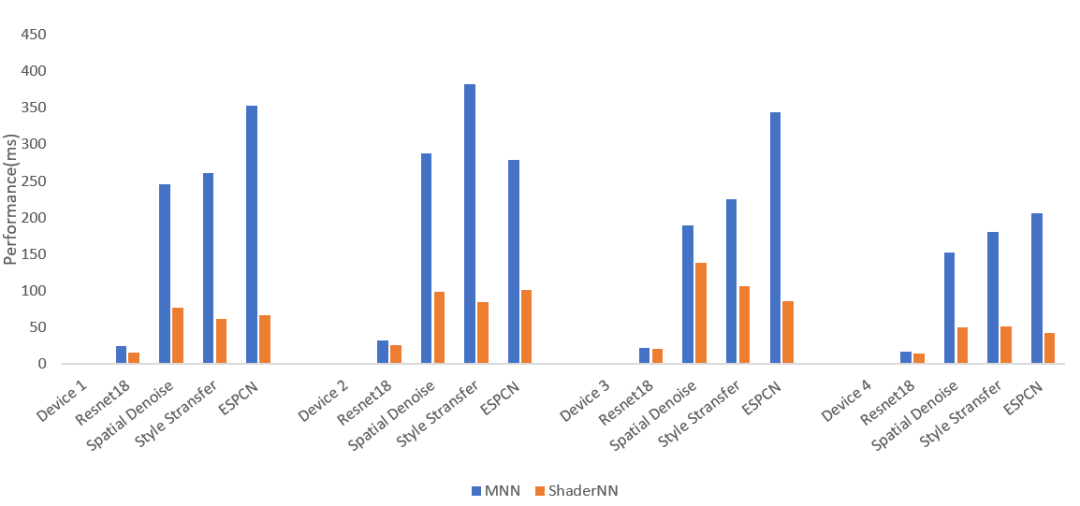
图5: 性能对比
从图5性能对比上看,在高通及MTK特定芯片组上表现优异,在Spatial Denoise和ESPCN等任务上的性能比MNN提高了50%-80%,在Resnet18和Style Transfer等任务上性能提高了6%-60%。
2、ShaderNN Vulkan 后端和 MNN Vulkan 后端功耗对比
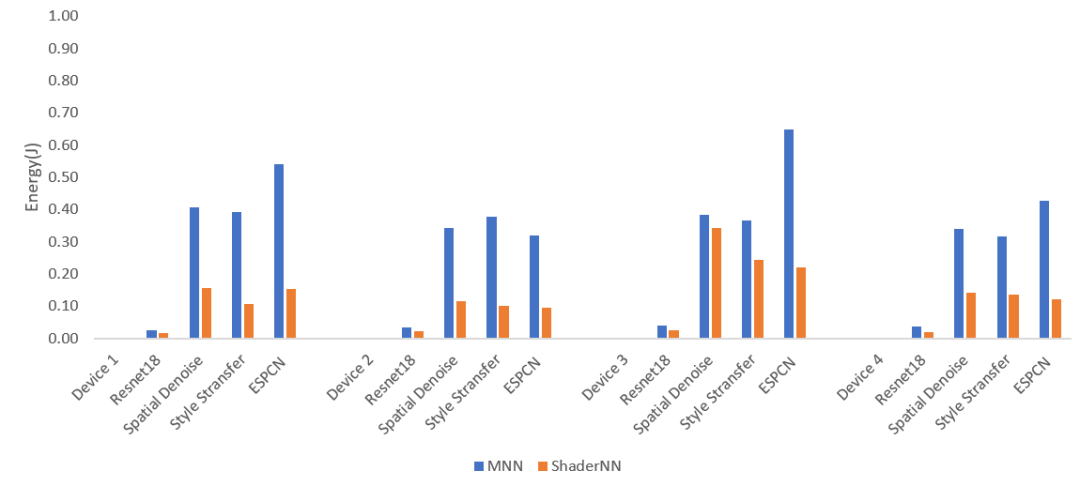
图6: 功耗对比
从图6功耗对比上看,在执行Spatial Denoise、ESPCN、Resnet18和Style Transfer等推理任务时,ShaderNN Vulkan后端相对MNN可以分别节省高达60%、70%、45%和70%的能量消耗。
四、 ShaderNN的典型场景
从上面性能和功耗功耗对比可以看出,ShaderNN擅长图形、图像类的应用。ShaderNN 2.0针对图形类应用场景,例如光线追踪降噪、游戏深度学习超采样MNSS,进行了适配和管线优化。同时,通过添加新的算子,ShaderNN 也能支持AIGC类的应用,如 Stable Diffusion。
移动端实时风格迁移应用:
在《面向AI图形的轻量深度学习推理引擎 ShaderNN》[1]一文中我们展示了风格迁移的Android Demo App,这个App 通过一个实时管线展示如何整合ShaderNN推理引擎到Android App,以及运行Style Transfer模型来处理从手机相机获取的实时视频流,并输出风格迁移后的视频流。在该应用中, 所有的数据都在GPU端处理,没有额外的数据传输和处理消耗。


图7: ShaderNN 风格迁移应用
移动端光线追踪降噪应用:
光线追踪(Path Tracing)是一种用于逼真渲染图像的算法。它模拟光线从相机出发,经过场景中的物体,最终到达光源的路径。通过追踪每条光线的路径并计算光线与物体的交点和光的传播,可以生成高质量、逼真的图像。和传统的光栅化渲染相比,光线追踪引入的计算量会成倍增加。光线追踪采用一种随机蒙特卡洛采样的方法,因此生成的图像受到采样噪声的影响。离线渲染主要采用多次采样的方式来降低噪声,然而,在移动端实时渲染中,低采样带来的噪声尤为明显,该问题只能通过降噪后处理来改善。
Intel推出了基于autoencoder结构的深度学习模型 Intel Open Image Denoise (OIDN)(https://github.com/OpenImageDenoise/oidn)。OIDN以反照率 (albedo), 第一次反射的法线 (first bounce normals) 和噪声数据 (noisy RGB image) 作为输入,通过深度学习模型进行降噪,在PC端已取得良好的效果。ShaderNN 2.0添加了多输入的支持,将这一模型应用到移动端图形渲染管线中。图8描述了降噪模型的基本流程,图9中展示了降噪模型中实时输入和输出效果。
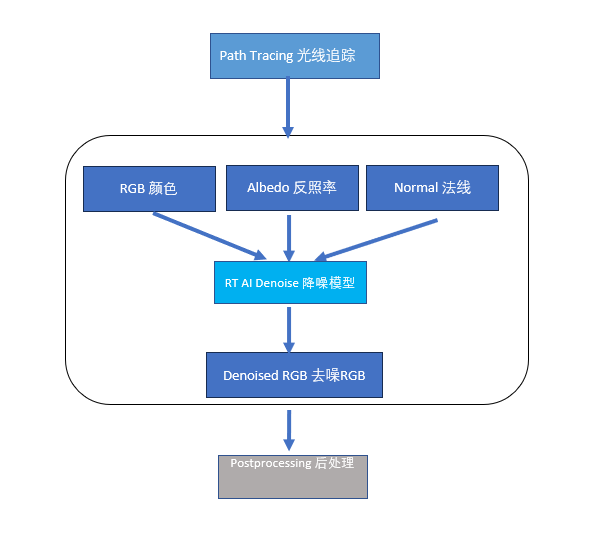
图8:光线追踪降噪模块

图9:ShaderNN 光线追踪降噪效果
移动端游戏的深度学习超级采样应用:
深度学习超采样DLSS(Deep Learning Super Sampling)是由NVIDIA开发的一种图像重建技术,旨在通过较低分辨率渲染结果和深度学习模型来构建高分辨率图像,以达到提高图像质量和性能的目的。通过ShaderNN这个开源项目,我们与浙江大学合作,开发实现了移动端实时深度学习超采样模型[3],并通过ShaderNN推理加速,首次在移动端实现游戏实时超采样。目前主流的DLSS模型都通过子采样技术获取更多像素细节,以及历史帧和运动矢量矫正后的temporal时态信息,来重建新的高分辨率图像。当前帧构建推理的输出结果又会反馈给超采样模型,作为下一帧构建的模型输入。基于ShaderNN,移动端DLSS模型推理针对移动端进行了大量的性能优化,既满足了实时性需求,又改善了游戏画面质量,尤其是在边缘和细节部分。图10描述了移动端DLSS模型的基本流程,图11中可以看到模型的实际输出效果。
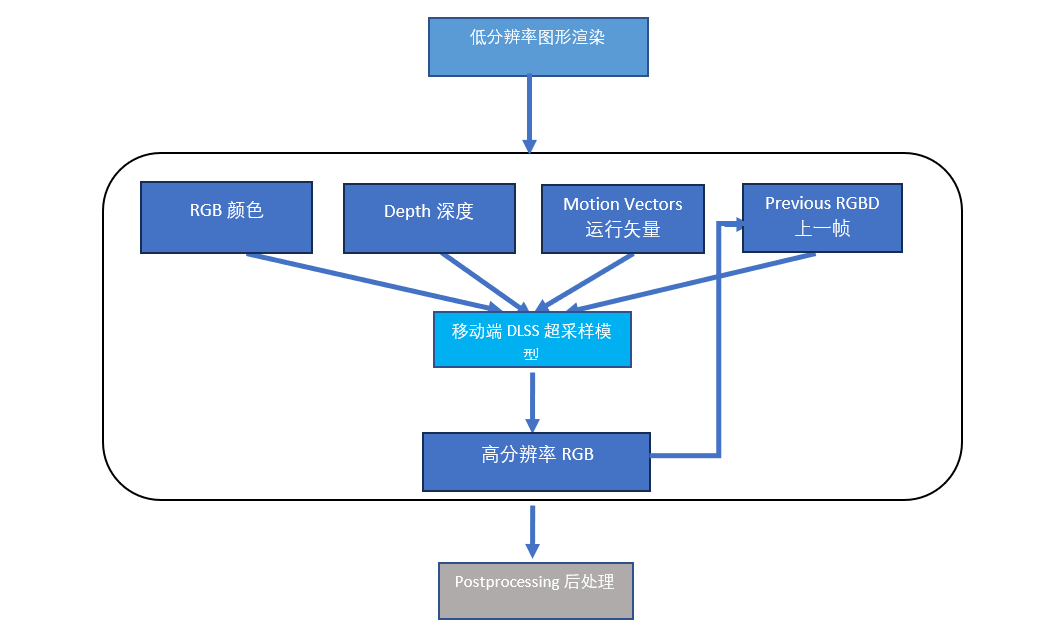
图10:移动端深度学习超采样模块

图11:ShaderNN 运行移动端深度学习超采样效果
移动端Stable Diffusion应用:
文字生成图像领域最前沿的Stable Diffusion模型包含CLIP Text Encoder, UNet, VAE 三个部分,我们尝试在ShaderNN2.0中运行Stable Diffusion模型https://huggingface.co/lambdalabs/miniSD-diffusers,并且部署到移动端。图12展示了运行效果。

图12:ShaderNN AIGC应用Stable Diffusion
五、规划和展望
基于OpenGL后端的ShaderNN 1.0作为开源项目发布后,ShaderNN 2.0添加了基于Vulkan后端的支持,支持移动端全图形栈的AI应用,支持图形图像领域的最新应用,如风格迁移、Ray Tracing Denoising (光追降噪)、游戏的深度学习超级采样、Stable Diffusion等,展现ShaderNN在与图形图像类应用进行深度耦合方面的优势。
我们下一步希望通过开源社区能吸引更多的开发者参与进来,覆盖更多的场景,持续优化算子和模型,以便更多的应用可以实际落地到产品中,致力于共同打造一个具有特色的基于OpenGL、Vulkan的全图形栈的移动推理引擎。
GitHub开源地址 (Apache2.0开源许可)
https://github.com/inferenceengine/shadernn
参考文献:
1. 面向AI图形的轻量深度学习推理引擎 ShaderNN,https://zhuanlan.zhihu.com/p/579051507
2.Justin Johnson, Alexandre Alahi, and Li Fei-Fei. 2016. Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision. Springer, 694–711
3. Sipeng Yang, Yunlu Zhao, Yuzhe Luo, He Wang, Hongyu Sun, Chen Li, Binghuang Cai, Xiaogang Jin,"MNSS: Neural Supersampling Framework for Real-Time Rendering on Mobile Devices", IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, Citation information: DOI 10.1109/TVCG.2023.3259141
本文作者:Qiang Qiu, Hongyu Sun, Yuzhong Yan, OPPO Computing & Graphics Research Institute

长按关注内核工匠微信
Linux内核黑科技| 技术文章| 精选教程