主要是用来测试Vitis-AI量化前后的pb模型的mAP的,以此来预估量化损失
核心代码在https://github.com/Xilinx/Vitis-AI-Tutorials/tree/1.2/Design_Tutorials/07-ml-edge-YOLOv3/files/core可以找到
但是我不知道怎么准备测试所需的文件以及格式,我就写下我自己准备的过程吧。
1 准备一些测试图片放到一个文件夹里,使用下面的代码提取出图片名
#!/usr/bin/python
#coding:utf-8
import os
path_imgs = './test_dir/'#存放图片的文件夹
for files in os.listdir(path_imgs):
print(files)
img_path = path_imgs+ files
with open("test_dir.txt", "a") as f:#保存图片名字的txt
f.write(str(img_path) + '\n')
将图片名写在test_dir.txt里面
2 运行tf_prediction.py得到检测结果
这里需要用到pb文件权重(我的博客写了如何获取pb模型)和上一步得到的test_dir.txt,将检测结果写在detec_result.txt文件中。得到的结果是这样的

3 获取map
这里麻烦的是需要按照代码来准备需要的格式文件,上一步可以看出detec_result.txt内容格式为
image_name class_label score xmin ymin xmax ymax
我们要自己准备一个如下格式的groundtruth.txt的文本
image_name class_label xmin ymin xmax ymax
voc数据集的groundtruth内容是这样的
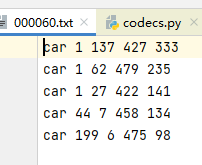
所以说只需要将image_name 与这些内容对应就好了,我写了一个脚本(写的很烂,好在功能可以实现)
import os
def hebing():
path_imgs = './img/'#存放图片的文件夹
groundtruth = r'input/ground-truth'#存放groundytruth文本的文件夹
list2 = [] # 图片名
for i in os.listdir(path_imgs):
list2.append(i.split('.')[0])
num = 0
for i in list2:
for filename in os.listdir(groundtruth ):
# print(r'E:\AI\ship/{0}'.format(filename))
path = os.path.join(groundtruth , filename)
f = open(path, 'r')
lines = f.readlines() # 内容
for k in lines:
img_path = list2[num] + ' ' + k#拼接图片名 + groundtruth中的内同
print(img_path)
with open("test_dir.txt", "a") as f:
f.write(str(img_path))
num = num + 1
continue
continue
hebing()
运行完就得到了这样的结果
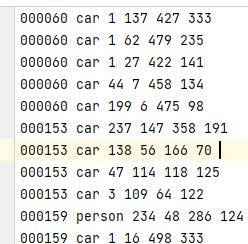
4 最后只需要运行evaluation.py就好了
结果是这样的

这个权重是我随便训练了十几轮的结果,图片我也只取了前200张,所以mAP比较低。