

-
论文地址:https://drive.google.com/file/d/10iR5hKwFqAKhL3umx8muOWSRm7hs5FqX/view
-
项目地址:https://github.com/LAION-AI/Open-Assistant
-
数据集地址:https://huggingface.co/datasets/OpenAssistant/oasst1
-
体验地址:https://open-assistant.io/chat
-
观看公告视频:https://youtu.be/ddG2fM9i4Kk
OpenAssistant介绍
最近火爆的ChatGPT使用如下图三个步骤训练得到,分别是:1)使用人类标注的数据训练SFT模型;2)对模型输出进行排序训练RM模型;3)使用RM模型微调SFT模型;
下图论文来自《Training language models to follow instructions
with human feedback》

通过监督微调(SFT)、人类反馈强化学习 (RLHF)大大减少了有效利用LLMs能力所需的技能和领域知识,然而,RLHF需要依赖高质量的人工反馈数据,这种数据的创建成本很高,而且往往是专有的。为了让大型语言模型民主化,LAION AI 等机构的研究者收集了大量基于文本的输入和反馈,创建了一个专门训练语言模型或其他 AI 应用的多样化和独特数据集 OpenAssistant Conversations。
该数据集是一个由13500 名志愿者人工生成、人工注释的助理式对话语料库,覆盖了广泛的主题和写作风格,由 161443 条消息组成,分布在 66497 个会话树中,使用 35 种不同的语言,有461292个质量评级标注。对于任何希望创建 SOTA 指令模型的开发者而言,它都是一个非常宝贵的工具。并且任何人都可以免费访问整个数据集。
此外,为了证明 OpenAssistant Conversations 数据集的有效性,该研究还提出了一个基于聊天的助手 OpenAssistant,它基于Pythia和LLaMA微调而来,其可以理解任务、与第三方系统交互、动态检索信息。可以说这是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。
结果显示,OpenAssistant 的回复比 GPT-3.5-turbo (ChatGPT) 更受欢迎。
OpenAssistant数据格式
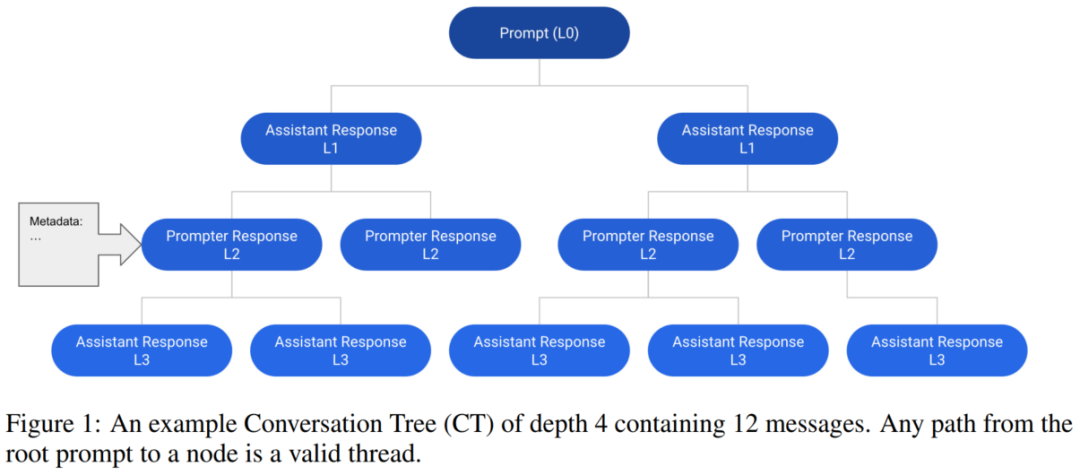
基本数据结构是会话树(CT),每个Node表示一个对话中的信息。一个 CT 的根节点代表一个初始提示,由提示者给出。为了避免混淆,研究人员把对话的角色称为提示者和助手。
下面是一个例子:
OpenAssistant数据收集
这些数据是通过一个web-app应用程序界面(https://open-assistant.io/)收集的,该界面通过将整个流程分为五个独立的步骤来完成:提示、标记提示、作为提示者或助手添加回复信息、标记回复、以及对助手的回复进行排名。
单步收集
为减少用户流失造成的数据丢失,数据收集分为多个单元,并确保每个工作单元都被捕获以供利用。用户可以从一系列任务选择或随机采样(根据当前要求加权)。任务类型包括创建提示,以助手身份回复、以提示者身份回复、标记提示或回复以及提示者或助理答复进行排序。
创建提示
每个新的会话树需要用户指定初始化Prompt,这里类似彩票系统一样,是从固定数量的Prompt中进行选择。
以助手身份回复
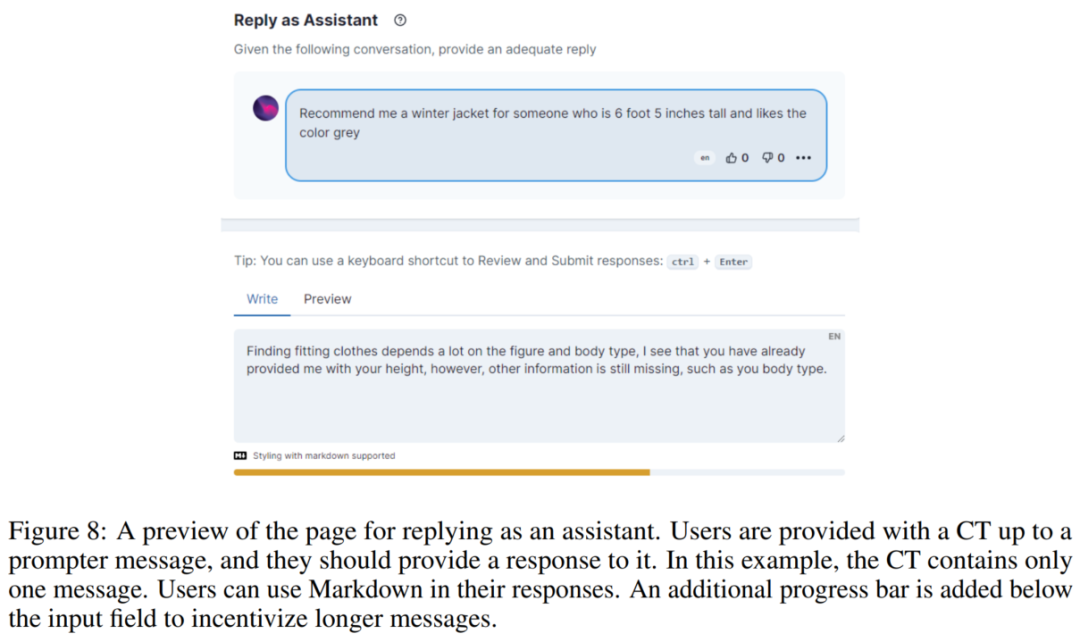
以提示者身份回复
作为提示者回复的任务并不严格质量要求,但强调多样性的重要性,以适应各种用例。提示回复的例子可能包括要求澄清、修改原文意图,提出后续问题,或完全改变谈话方向。
标记提示或回复

提示者或助理答复进行排序

OpenAssistant数据语言分布
主要以英语和西班牙语为主:

OpenAssistant信息分布
实验验证
指令微调
为了评估和证明 OpenAssistant Conversations 数据集的有效性,研究者专注于基于 Pythia 和 LLaMA 的微调语言模型。其中 Pythia 是一个具有宽松开源许可的 SOTA 语言模型,而 LLaMA 是一个具有定制非商业许可的强大语言模型。
对此,研究者发布了一系列微调语言模型,包括指令微调的 Pythia-12B、LLaMA-13B 和 LLaMA-30B,这是他们迄今最大的模型。研究者将分析重心放在了具有开源属性的 Pythia-12B 模型上,使得它可以被广泛访问并适用于各种应用程序。
为了评估 Pythia-12B 的性能,研究者展开了一项用户偏好研究,将其输出与 OpenAI 的 gpt-3.5-turbo 模型进行比较。目前已经有 7,042 项比较,结果发现 Pythia-12B 对 gpt-3.5-turbo 的胜率为 48.3%,表明经过微调的 Pythia 模型是非常具有竞争力的大语言模型。
偏好建模
除了指令微调模型之外,研究者还发布了基于 Pythia-1.4B 和 Pythia-12B 的经过训练的奖励模型。利用在真实世界数据上训练的奖励模型可以为用户输入带来更准确和自适应的响应,这对于开发高效且对用户友好的 AI 助手至关重要。
研究者还计划发布经过人类反馈强化学习(RLHF)训练的 LLaMA-30B,这种方法可以显著提升模型性能和适应性。不过,基于 RLHF 方法的模型开发与训练正在进行中,需要进一步努力确保成功地整合进来。
有毒信息
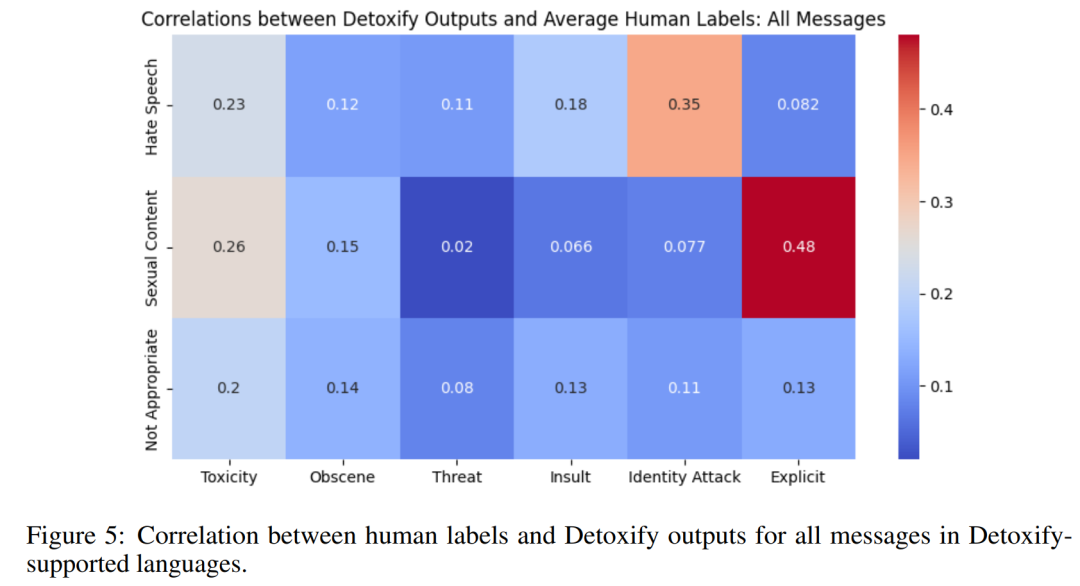
研究者采取基于 Detoxify 的毒性检测方法来获得六个不同类别的自动评级,分别是有毒、色情、威胁、侮辱、攻击性、露骨言论。使用自动毒性评级,研究者系统地评估了人工指定毒性标签(如仇恨言论、不恰当和色情)的级别。并且基于 115,153 条消息样本,他们计算了自动与人工注释毒性标签之间的相关性,如下图 5 所示。

OpenAssistant训练配置
数据格式
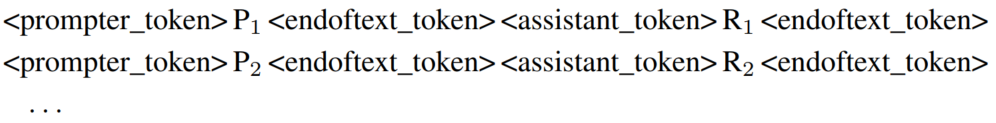
监督微调SFT
mask掉Prompts的token,只预测助手回复的token
奖励模型RM
使用一个线性层替换掉语言模型的head得到一个score,这个score作为会话最好一个回复的score,损失函数如下:

强化学习PPO
使用https://github.com/CarperAI/trlx训练PPO算法
更多训练细节
https://github.com/LAION-AI/Open-Assistant/tree/main/model/model_training
局限性
主观偏见和文化偏见
数据标注人员来自不同的背景,有各种各样的兴趣,但在性别和年龄有偏向性。具体来说,89.1%的标注人员是平均在26岁的男性。这可能会在数据集中无意引入偏见,因为事实上必然会反映标注人员的价值观、观点和兴趣。
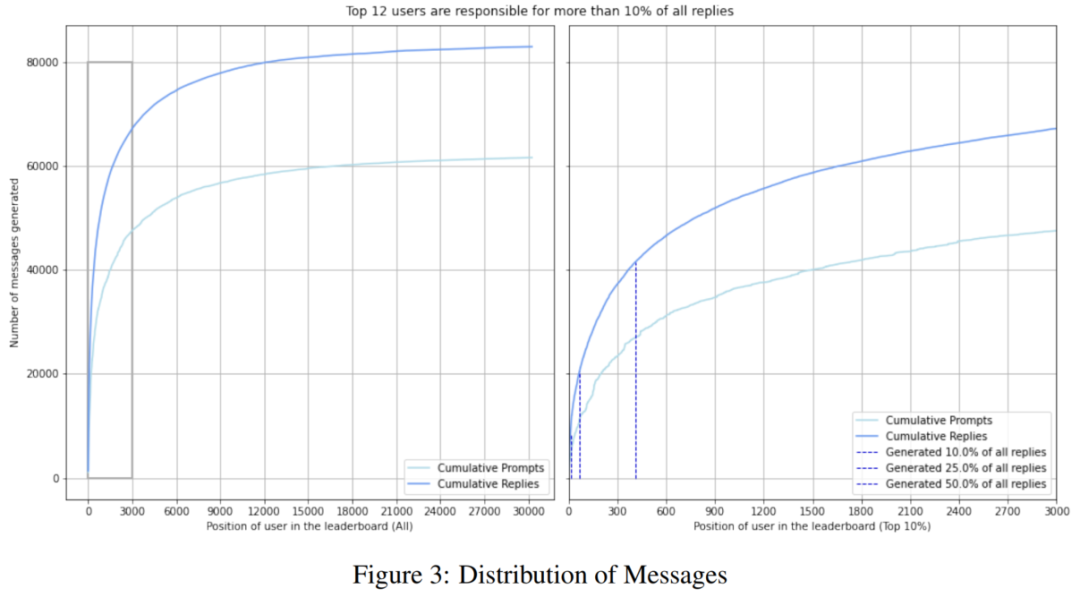
贡献分配不均
数据集受益于大量用户,但他们的参与程度差异很大。参与度越高的用户贡献的标注数量越多,这导致他们的价值观和兴趣代表性在数据集中越高。
可能的不安全内容
尽管采取了一些检测和消除数据集中的有害内容,但并不能保证系统的万无一失,因此主张在学术研究中使用LLM,并敦促研究人员在将这些模型应用于下游任务时,要仔细考虑安全性和偏差影响。
OpenAssistant与GPT3.5对比
我们来看几组 OpenAssistant 与 GPT-3.5 的生成结果比较。比如“单词 barn 的词源 / 起源是什么?”可以看到,OpenAssistant 解释地更详细、全面。

再比如输入“你现在是一个普通的人类。请介绍一下你自己并告诉我一些你的日常生活。”OpenAssistant 代入了普通人类的角色,GPT-3.5 显然没有,还是以 AI 语言模型自居。

最后输入“如何创建一个成功的 YouTube 频道,从开发一个利基市场到创建内容以建立一个社区并货币化频道?”OpenAssistant 的回答相对而言更有条理性。
