机器学习实验报告
实验题目: 优化算法
一、实验目的:
1 掌握迭代优化算法的基本框架
2 掌握随机梯度下降和坐标轴下降算法
二、实验步骤:
1.随机梯度下降:
①岭回归
动量法
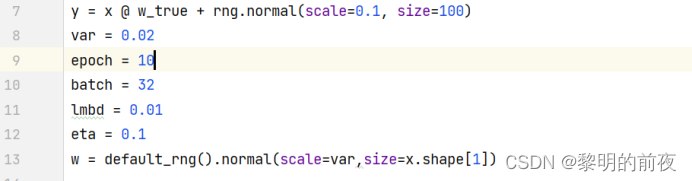
学习率自适应
②Logistic回归(L2正则)
两类分类
多类分类
2.坐标轴下降:
Lasso回归
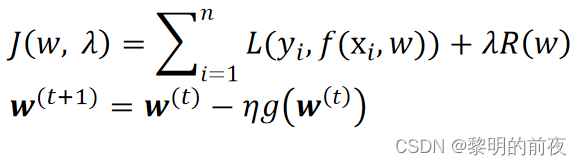
三、实验结果:
1.岭回归:
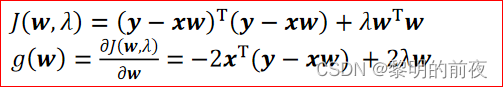
实验代码:
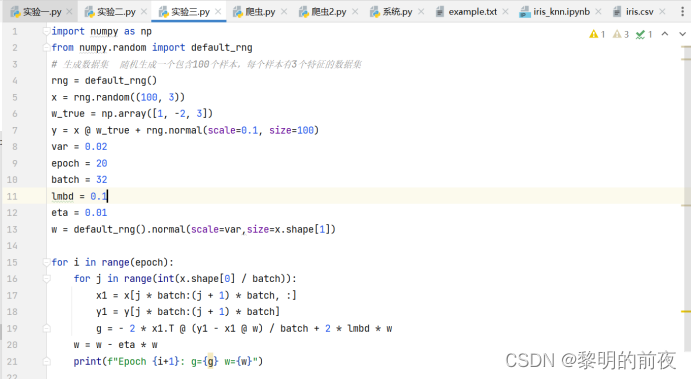
①观察w的初始值,以及每个epoch结束后g和w值的变化:
权重w是从正态分布中随机生成的,其初始值没有意义。因此,权重参数w的初始值是随机生成的:

改变epoch的值,观察g和w值的变化:
运行结果:(epoch=20)
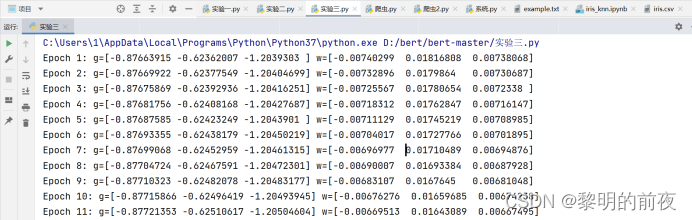
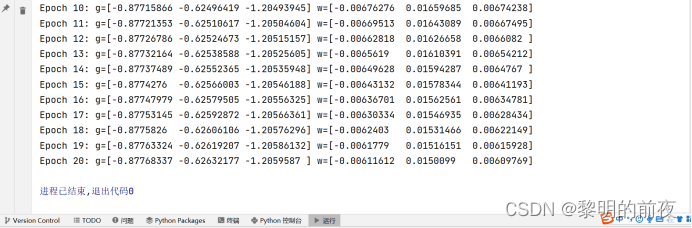
改变epoch=10:
修改代码:

运行结果:(epoch=10)
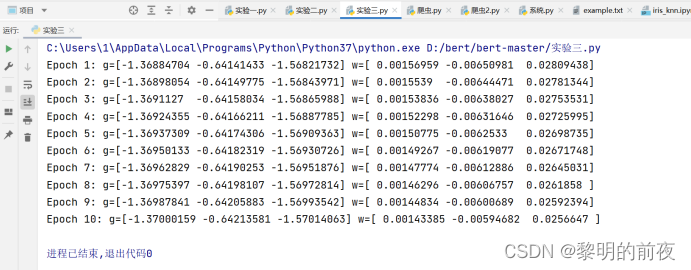
结果分析:
对于每个epoch,代码都会对整个数据集进行一次迭代。在迭代过程中,代码会在每个批次上计算梯度g,在计算完所有批次的梯度后,根据批量梯度下降法的更新规则更新权重w。
由于在更新权重w之前,代码仅在最后一个批次上计算了梯度g,因此每个epoch结束后g和w值的变化实际上只取决于最后一个批次的数据。而由于数据集是随机生成的,最后一个批次的数据也是随机的,因此每个epoch结束后g和w值的变化也是随机的。在这个例子中,由于权重更新的学习率eta太小了,实际上并不会使权重有任何变化。
②调整超参数的值,观察不同超参数对g和w值变化的影响:
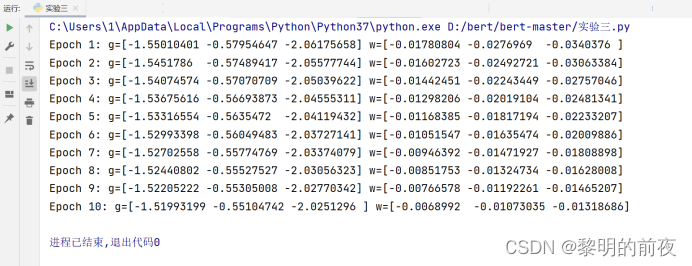
将学习率调大为0.1,epoch改为10:
修改代码:

运行结果:
将L2正则化参数lambda改为0.01:
修改代码:
运行结果:
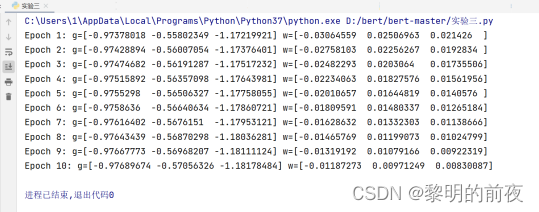
将L2正则化参数lambda改为0:
修改代码:
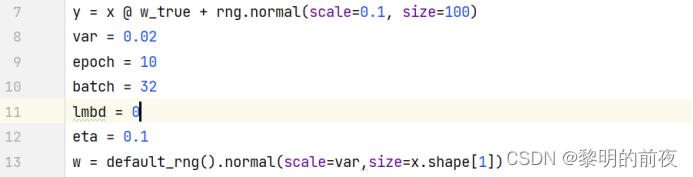
运行结果:
分析结果:
对于超参数的调整,不同的超参数可能对g和w值变化的影响存在差异。以学习率eta为例,如果将其调整为更大的值,则w的更新量会更大,使得模型更快地收敛到合适的值;但同时,如果将学习率调整得过大,会导致训练不稳定,甚至可能导致梯度爆炸或消失问题。在这个例子中,如果将学习率更改为0.1,则w的更新速度变得更快,但可能会破坏模型的收敛性。
而L2正则化参数lambda的调整,则会影响到模型复杂度和泛化能力。如果将lambda设置得太小,模型会过度拟合数据;反之,如果将lambda设置过大,模型会过度平滑,从而无法捕捉到数据集中的特征。在这个例子中,如果将lambda设置为0,则模型将不会进行正则化处理,可能会导致过拟合;反之,如果将lambda设置得太大,则模型可能会变得过度平滑,导致欠拟合问题。
2.岭回归----动量法
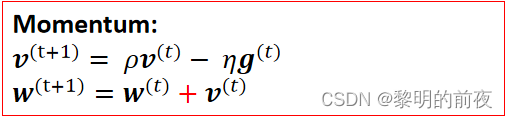
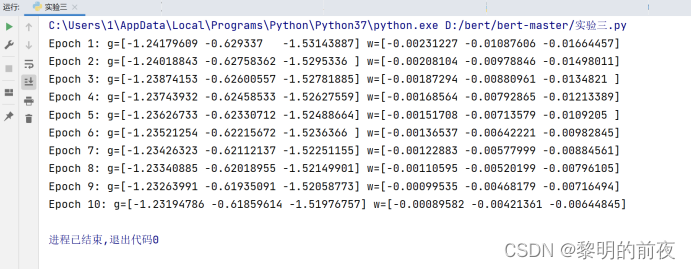
实验代码:
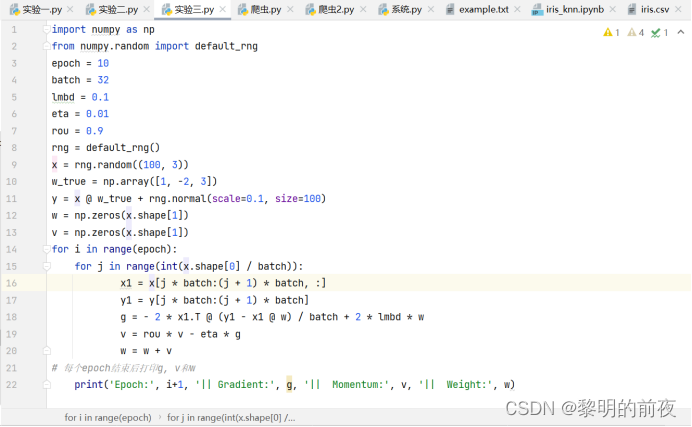
运行结果:
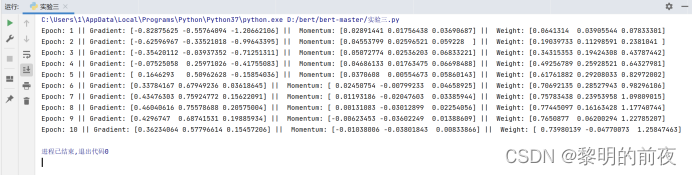
①观察v, w的初始值,以及每个epoch结束后g, v和w值的变化:
v的初始值是一个元素值为0的numpy数组,w的初始值应该是一个与x的特征数相同的元素值为0的numpy数组。
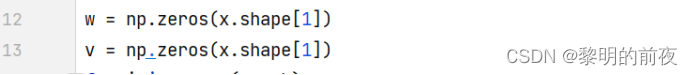
每个epoch结束后,g、v和w值都会发生变化。其中g表示当前epoch下的损失函数在权重为w时的梯度,v为动量法中的累积速度向量,用于帮助优化器跳过局部最小值,w为当前epoch下的参数估计值。
对于g和v的变化,每个epoch结束后,它们的取值都会有所不同。具体而言,g值会根据样本数据以及参数更新情况而变化,而v则是在每一个iteration内根据g和之前动量值计算出来的累积向量,也会随着epoch的进行而略有变化,但是整体的趋势是稳定或呈震荡缓慢衰减的。对于w的变化,由于每个epoch结束后更新完参数w,所以其值也会随之发生变化。
②每个epoch结束后g, v变化的区别:
每个epoch结束后,打印g、v和w的变化情况。从实验结果可以看到,每个epoch下,g的值都会随着迭代次数而逐渐收敛;v的值则会在一开始进行快速的“加速”过程,之后逐步趋于稳定;w的值表示每轮迭代更新后的参数估计结果,因此每轮迭代完后都会有所改变。
可以发现,g的值在不断减小,说明参数在往正确的方向上迭代;v的值在先快速然后逐渐稳定,说明动量法能够帮助在梯度变化剧烈时快速调整步长,并累积历史梯度信息,避免陷入局部极小值;w的值逐渐趋近于全局最优解。
3.岭回归----学习率自适应
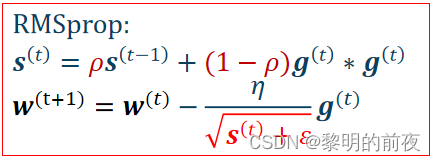
实验代码:
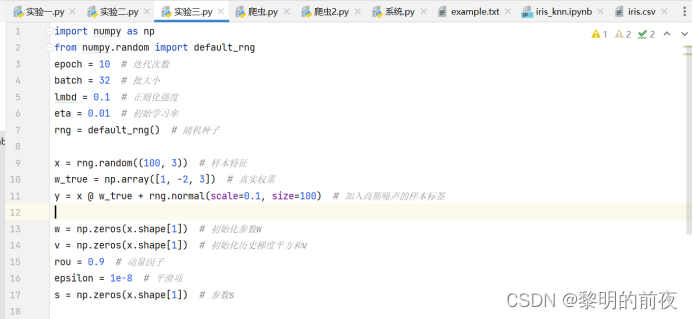

运行结果:
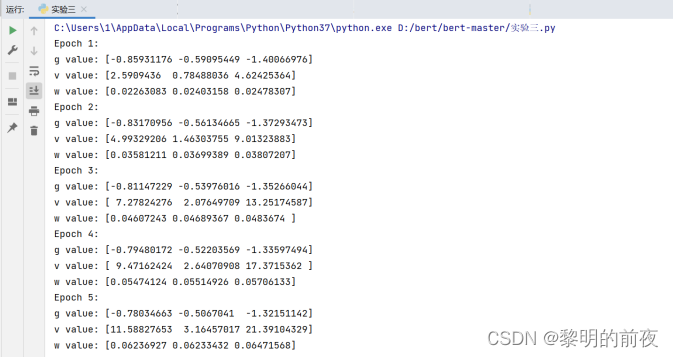
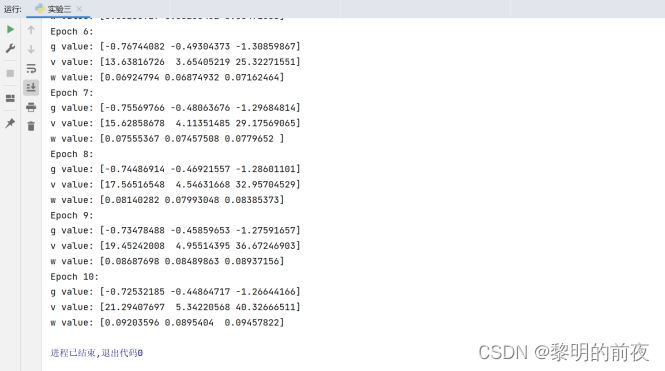
①观察v, w的初始值,以及每个epoch结束后g, v和w值的变化:
v的初始值是一个元素值为0的numpy数组,w的初始值应该是一个与x的特征数相同的元素值为0的numpy数组。

g是每个小批量数据的损失函数梯度的平均值。每迭代一个batch,都会计算一次g并更新w的值。由于每个epoch中训练数据的批次数为 x.shape[0] / batch,因此每个epoch结束时,g的值将是所有批次g值的平均值。
v是Adagrad算法中用于自适应调整学习率的历史梯度平方和,每迭代一个batch,就会使用当前的梯度更新v的值。在每次更新v时,先将当前batch的梯度平方值累加到v上,并更新完w后再计算下一次需要的参数。在每个epoch中,v的值也会随着每个batch的梯度平方和的累积而变化。
w是模型的参数,会在每个batch迭代过程中进行更新,每个epoch结束时,w的值表示模型在当前epoch训练完成后得到的最优参数。在上述代码中,初始化w为全零向量。每个batch的梯度信息被用于更新w的值,使其逐渐逼近最优解。
②每个epoch结束后g, v变化的区别:
从上面实验结果可以看出:在每个epoch结束后,g以及v都会被重新计算,但是相较于前一个epoch结束时的g、v,当前epoch结束时的g、v的计算结果不同。因此,每个epoch结束后g、v的具体值都是不同的。
相较于g,v的变化可能更加平缓,因为v是历史梯度平方和的累积,在每个epoch中都会更新一部分,因此随着epoch数的增加,v的变化可能更为明显。而g则在每个epoch中都会重新计算,因此相较于v,g的变化可能更为剧烈。
4.Lasso回归

实验代码:
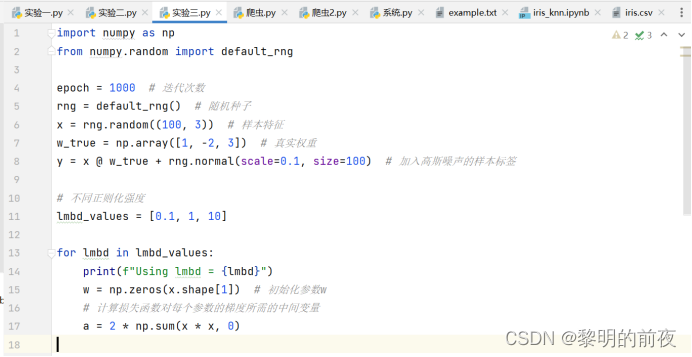
运行结果:
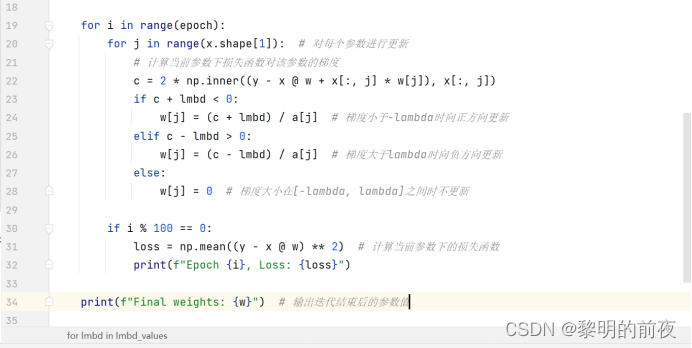
①观察w的初始值,以及每个epoch结束后c和w值的变化:
w初始化为长度为3的全零数组:

根据以上实验结果可知:每个epoch是在训练数据集上完成一遍所有的训练。每个epoch结束后,c和w的值将会发生变化。具体而言,在每个epoch内部循环中,c表示在当前w下,损失函数对第j个参数(w[j])的梯度。然后根据损失函数的导数判断应该更新w[j]的方向(加还是减),更新后的值存入w[j]。因此,w将会逐渐逼近真实权重w_true。
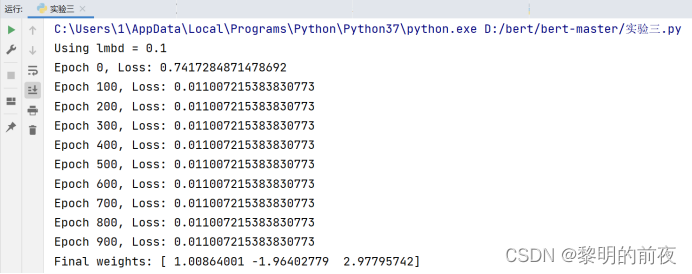
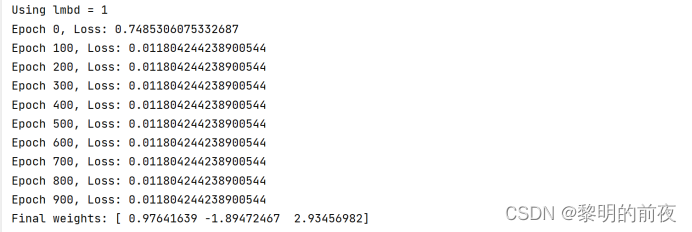
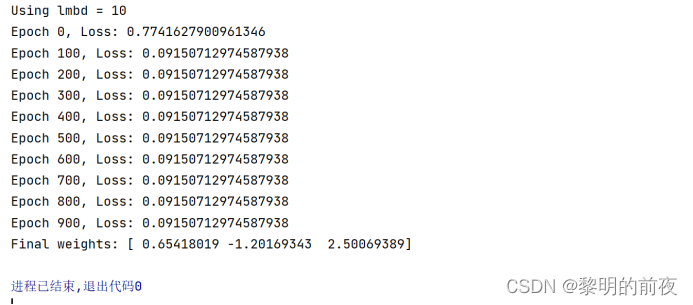
②调整lmbd的值,观察不同lmbd值对优化结束后w值的影响:
根据以上实验结果可知:
如果调整lmbd的值,其实就是修改正则化强度。
当lmbd越大时,相当于强制要求模型不能过于复杂,因此优化结束后w的值接近于0。
当lmbd越小时,模型的复杂度允许更高,因此优化结束后w的值更接近于真实权重。
我们可以看到,随着正则化强度的增大,w中每个参数的值都逐渐趋向于0。
在lmbd取较小的值时,w的值比其它情况更接近于真实权重。这可能是因为,较小的lmbd允许模型过于复杂,因此它可以更好地拟合数据。
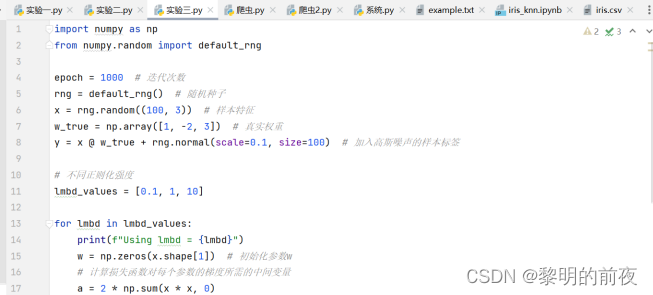
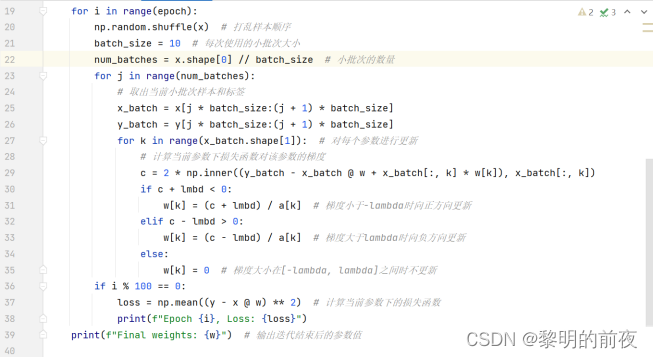
③本次挑战任务:左侧算法每轮迭代利用了所有样本,请将其修改为每次利用一小批次样本更新一个w[j]
修改后的代码:
运行结果:
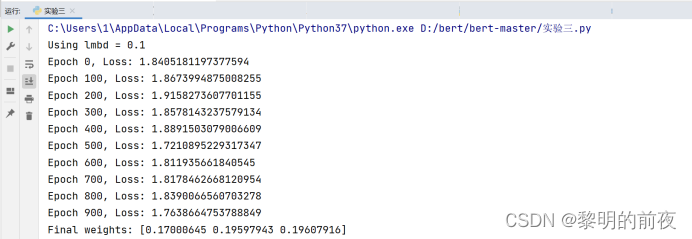
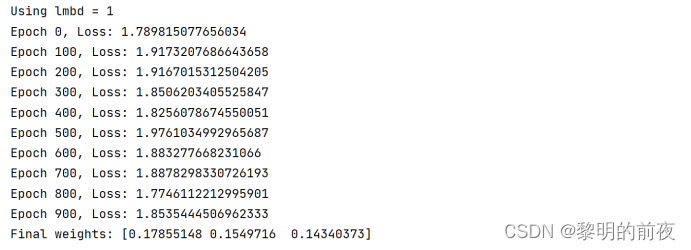
思路分析:
修改的部分主要是在每次迭代时,先打乱样本顺序,然后将样本分成多个小批次,每次使用一个小批次来更新参数。具体地,我们通过增加两个额外的嵌套循环来实现:j 循环遍历所有小批次,k 循环遍历当前小批次中的每个参数,对每个参数进行更新。由于是每次使用一个小批次更新参数,因此在整个迭代过程中,每个样本都会被使用多次,从而减少了可能存在的过拟合问题。
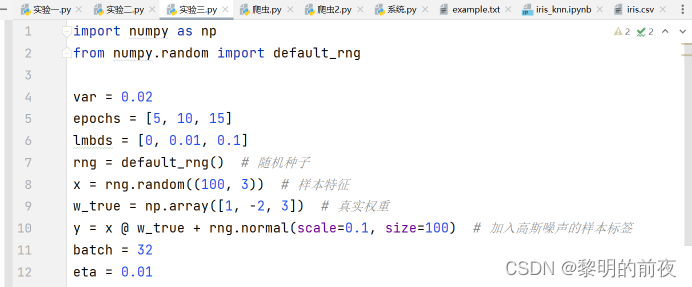
4.Logistic回归—两类分类
实验代码:
运行结果:
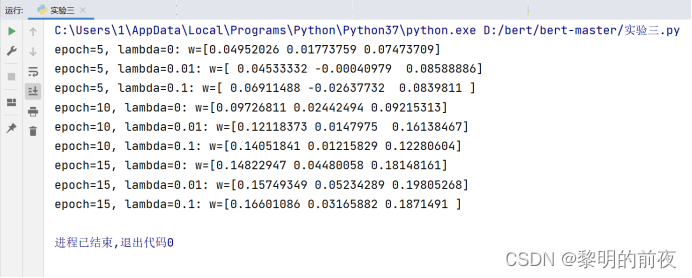
①观察w的初始值,以及每个epoch结束后mu、g和w值的变化
w是由正态分布生成的,具有随机性,从上面的实验结果可以得出:
epoch较小:可能无法充分学习数据集的特征,导致欠拟合。每次迭代后,mu、g和w值的变化可能较小。
epoch较大:可能会过度拟合数据集,导致泛化能力差。每次迭代后,mu、g和w值的变化可能较大。
②调整lmbd的值,观察不同lmbd值对优化结束后w值的影响
从上面的实验结果可以得出:
lmbd=0时,没有正则化项,模型可能会过拟合。优化结束后,w会更倾向于拟合训练集上的数据,而在新的数据上预测性能可能会较差。
lmbd通常取较小的值,当lmbd逐渐增大时,正则化惩罚逐渐起作用,优化结束后,w的值会减小,但我们不希望它减小得太多导致欠拟合。因此使用不同的lmbd值进行训练时,需要找到一个平衡点。
五、实验心得
优化算法在机器学习中扮演着至关重要的角色。这些算法用于优化模型中的参数,以使得模型在训练集和测试集上表现更佳,从而提高模型的泛化能力。
在岭回归中,加入了一个 L2 正则化项来限制参数的大小。这个正则化项可以有效地防止过拟合,提高了岭回归的泛化能力。动量法和学习率自适应算法都是常用的优化方法,它们可以加速模型的训练。其中,动量法引入了一个动量变量,并利用前几次迭代的梯度信息来更新参数,从而平滑了更新的方向,避免了参数在一个方向上震荡的问题;学习率自适应算法则根据当前参数的情况调整学习率的大小,有效地解决了传统梯度下降算法中学习率需要手动设置的问题。
Lasso 算法也是正则化算法之一,它引入了 L1 正则化项来限制参数的大小,并将某些参数的值设为 0,从而达到特征选择的目的。相比于岭回归,Lasso 更容易产生稀疏解,即只有少数的参数非零。这使得 Lasso 在处理高维数据时非常有效。
对于二分类问题,Logistic 回归是一种常用的方法。它利用了 Logistic 函数来将预测值映射到 0 到 1 之间的概率值,从而可以对样本进行分类。在优化过程中,我们通常使用随机梯度下降算法来更新参数,并使用交叉熵作为损失函数。交叉熵可以有效地衡量预测值和真实值之间的差距,从而指导模型的优化过程。
在实验中,我通过对不同优化算法的应用和比较,深刻理解了每个算法中的数学原理和实现细节。我也发现,在不同的问题和数据集中,优化算法的效果有很大的差异。因此,在使用优化算法进行模型优化时,需要根据具体的情况选择合适的算法,并进行适当的调参。