系列文章目录
基础学习——关于卷积层的记录
基础学习——nn.Unfold 批量切片、F.conv2d 指定卷积核二维卷积操作、nn.Conv2d卷积层
基础学习——读txt数据、字符串转list或数组、画PR曲线、画Loss曲线
文章目录
前言
老是忘有些模块的具体作用,记录一下。
一、功能层
1、池化层
池化层夹在连续的卷积层中间,用于 压缩数据和参数的量,在构建卷积神经网络时,往往会用在卷积层之后,通过池化来降低卷积层输出的特征维度,有效减少网络参数的同时还可以防止过拟合现象。
下图为最大池化,平均池化也类似。

2、nn.BatchNorm2d()
作用:卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定。
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
num_features:一般输入参数为batch_size×num_features×height×width,即为其中特征的数量
eps:分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5
momentum:一个用于运行过程中均值和方差的一个估计参数
affine:当设为true时,会给定可以学习的系数矩阵gamma和beta
3、全连接层
全连接层是神经网络中的一种常见层,也称为密集层(Dense Layer)。它将上一层的所有神经元都连接到当前层的所有神经元上,因此被称为全连接。在全连接层中,每个输入神经元都与输出层的所有神经元相连,并对输出层中的每个神经元产生影响。
全连接层的优点是可以表达出非常复杂的函数,适用于识别复杂的模式和特征。然而,全连接层中的参数数量很多,因此容易出现过拟合的问题。此外,全连接层在输入数据存在位置关系的情况下,无法对空间信息进行有效的编码和处理。倒数第二列的向量就是全连接层。

4、softmax层
softmax层是神经网络中常用的一种激活函数,通常用于多分类问题。在神经网络的输出层中,通过softmax函数将每个输出节点的值映射到0到1之间,并且归一化,使得所有输出节点的值之和为1,表示每个类别的概率分布。
softmax函数的数学表达式为:
y i = e x i ∑ j = 1 n e x j y_i = \frac{e^{x_i}}{\sum_{j=1}^{n}{e^{x_j}}} yi=∑j=1nexjexi
其中, x i x_i xi表示输入节点i的值, n n n表示输出节点的总数, y i y_i yi表示第i个输出节点的输出值。softmax函数将每个输入节点的值通过指数函数映射到非负数,然后再将所有节点的值相加作为分母,并将每个节点的指数值除以分母,得到每个节点的输出值。
softmax层在深度学习中广泛应用于分类问题,例如图像分类、自然语言处理中的情感分类、命名实体识别等。
二、卷积层
1、普通卷积
浅层:从输入图像中提取不同方面的特征,比如水平,垂直 ,边缘或对角线。
深层:通过浅层特征的组合,提取更加抽象的高层语义特征或全局特征。


2、空洞卷积
空洞卷积(Dilated Convolution)是一种卷积神经网络中的操作,也被称为扩张卷积。它的作用是在不增加参数和计算量的情况下,增加神经网络的感受野(Receptive field),从而提高网络的性能。
在传统的卷积操作中,每个卷积核都会与相邻的像素进行卷积运算,而在空洞卷积中,卷积核会跳过一些像素点而只与部分像素点进行卷积运算,这样就能够扩大感受野。具体来说,空洞卷积通过在卷积核内部插入一些间隔点,使得卷积核在进行卷积时能够跳过这些间隔点,从而实现感受野的扩张。
常见的空洞卷积有两种:一种是一维空洞卷积,一种是二维空洞卷积。在实际应用中,空洞卷积常用于图像分割、语义分割等领域。

3、多尺度卷积
多尺度卷积是一种卷积神经网络(CNN)中的技术,它可以在不同的尺度下对输入数据进行卷积操作,从而提取不同层次的特征。在多尺度卷积中,通常会使用不同大小的卷积核来对同一层的输入数据进行卷积操作,这样就可以捕捉到不同尺度的特征信息。
例如,在图像识别任务中,多尺度卷积可以对输入的图像进行不同尺度的卷积操作,从而可以捕捉到不同尺度的物体特征,如小物体、中等大小的物体和大物体的特征。这样可以使模型更加全面地了解输入图像的特征,从而提高识别准确率。
多尺度卷积在许多应用中都有广泛的应用,如图像处理、语音识别、自然语言处理等。缺点:下图左图计算量太大,改进后的右图插入1×1的卷积降通道,减少了计算量。
SKNet模块可以自适应的决定哪个分支的信息更重要。
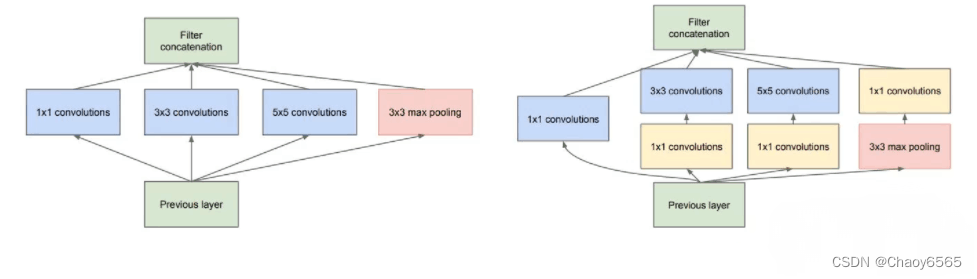
4、分组卷积
分组卷积是指在卷积层中,将输入的特征图分成若干个组,每个组内的特征图只与该组内的卷积核进行卷积操作,最终将各组的结果拼接在一起得到输出特征图。这种操作可以减少参数数量和计算量,因为组内的特征图共享同一个卷积核,减少了需要学习的参数数量。同时,分组卷积也可以提高模型的并行计算能力,因为各组的卷积操作可以在不同的计算设备上进行。
下图为普通卷积:

下图为分组卷积:计算之后再拼接起来

缺点:信息流通不通畅
5、深度可分离卷积
深度可分离卷积是一种卷积神经网络中的特殊卷积类型,其核心思想是将卷积操作拆分成深度卷积和空间卷积两个步骤进行处理。具体而言,深度可分离卷积首先使用一个只涉及深度方向跨度的卷积核进行深度卷积,然后再使用一个普通的卷积核进行空间卷积。这样可以大大减少卷积操作的总量,从而提高计算效率,同时也有助于缓解过拟合问题。深度可分离卷积在一些轻量级的神经网络中应用得比较广泛,例如MobileNetV1等。
深度可分离卷积主要事先通过逐层卷积得到每个层的特征层如下
逐层卷积:

然后再通过逐点卷积(1*1的卷积层)进行合并
逐点卷积:

6、形变卷积
形变卷积(deformable convolution)是一种卷积神经网络中的卷积操作,它可以在输入特征图中根据学习到的偏移量进行形变并且对相应位置的像素进行卷积计算。
传统的卷积操作只能在固定的空间位置进行计算,而形变卷积可以根据实际情况对输入特征图进行形变,从而更好地适应目标的形状和姿态。形变卷积的计算过程类似于传统卷积,但是在卷积核的计算过程中,每个位置的权重不再是固定的,而是根据学习到的偏移量来进行计算。这使得形变卷积能够更好地适应目标的形状和姿态,并且在目标检测、语义分割等任务中取得了良好的效果。
普通卷积和形变卷积的计算公式:

也就是形变卷积比普通卷积多了一个偏移量。
示例:
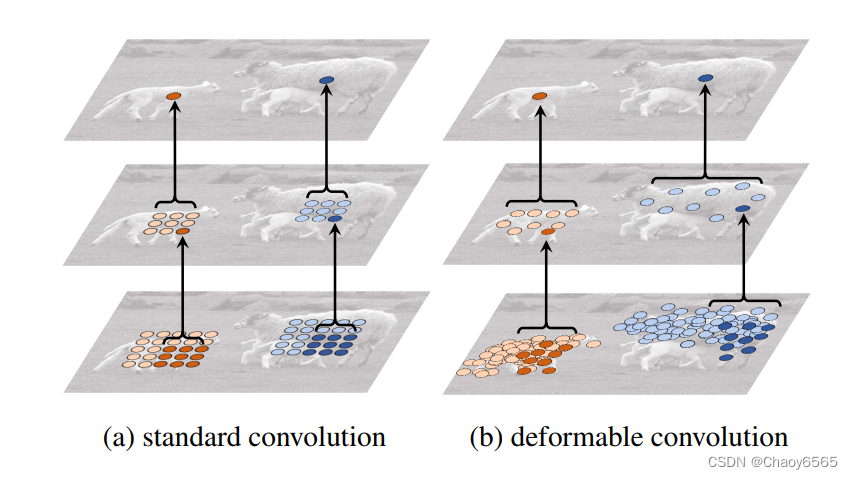
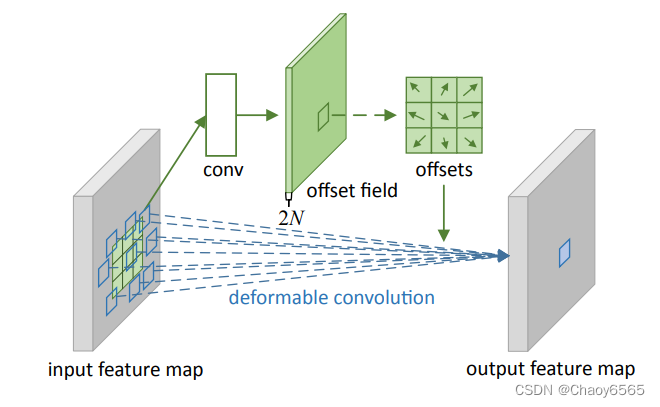
上图为可变形卷积示意图。可以看到offsets(偏移)是额外使用一个卷积来生成的,与最终要做卷积操作那个卷积不是同一个 。图示N为卷积核区域大小,例如3*3大小的卷积核,N=9,图中绿色过程为卷积学习偏移的过程,其中offset field的通道大小为2N,表示卷积核分别学习x方向与y方向的偏移量。在input feature map上普通卷积操作对应卷积采样区域是一个卷积核大小的正方形(绿框),而可变形卷积对应的卷积采样区域为一些蓝框表示的点,这就是可变形卷积与普通卷积的区别。
代码直接调用就好。
import torch
from torch import nn
class DeformConv2d(nn.Module):
def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, bias=None, modulation=False):
"""
Args:
modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2).
"""
super(DeformConv2d, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.zero_padding = nn.ZeroPad2d(padding)
self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)
self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_backward_hook(self._set_lr)
self.modulation = modulation
if modulation:
self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.m_conv.weight, 0)
self.m_conv.register_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
offset = self.p_conv(x)
if self.modulation:
m = torch.sigmoid(self.m_conv(x))
dtype = offset.data.type()
ks = self.kernel_size
N = offset.size(1) // 2
if self.padding:
x = self.zero_padding(x)
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
# modulation
if self.modulation:
m = m.contiguous().permute(0, 2, 3, 1)
m = m.unsqueeze(dim=1)
m = torch.cat([m for _ in range(x_offset.size(1))], dim=1)
x_offset *= m
x_offset = self._reshape_x_offset(x_offset, ks)
out = self.conv(x_offset)
return out
def _get_p_n(self, N, dtype):
p_n_x, p_n_y = torch.meshgrid(
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1))
# (2N, 1)
p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)
p_n = p_n.view(1, 2*N, 1, 1).type(dtype)
return p_n
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(1, h*self.stride+1, self.stride),
torch.arange(1, w*self.stride+1, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1)//2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, c, h, w, N = x_offset.size()
x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)
x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)
return x_offset
7、递归残差卷积层
还没弄明白!