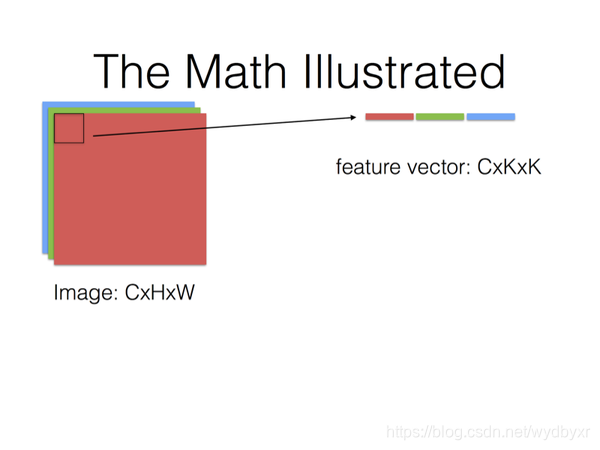
加速的卷积运算
convolution在GPU上如何实现,文中介绍了三种方法
1)最直观的方法是直接实现(即一般的卷积运算)
缺点:这种实现呢需要处理许多的corner case。
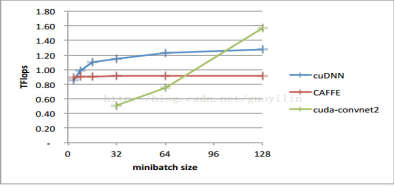
文中介绍cuda-convnet2是实现了该种方法,该种方法在不同取值的卷积参数空间效率不一,比如batch size > 128,效率很高,但是如果batch size < 64, 效率比较低。
2)采用快速傅里叶变换fft/fft convolution
优点:该种方法效率非常高
缺点:由于filter需要扩大到和input一样大小,占用了大量内存,特别是CNN的前几层filter 大小远小于input大小。而且,当striding 参数>1, fft效率也不高。
此时需要将卷积核扩大成和feature map一样的长宽尺寸,这在二者相差较大的时候也是很浪费的。另外,当stride大于1时,数据比较稀疏,采用FFT效果也并不理想。
这是一种加速的2d卷积,matlab中有。 该种方法效率非常高,但是由于filter需要扩大到和input一样大小,占用了大量内存,特别是CNN的前几层filter 大小远小于input大小。第二,当striding 参数>1, fft效率也不高。
实际效果
对于大矩阵,filter2或conv2太慢了,而使用convfft有极大的提速(100 ^ 2和500^2的矩阵进行卷积时,加速为5-10倍。
Signal length 1 second, impulse length 1 second, fs=44100, vectors (one-dimension).
conv 103.8 s
filter 79.4 s
fftfilt 0.38 s
convfft 0.92 s
Signal length 10 seconds, impulse length 1 second
fftfilt 1.28 s
convfft 14.61 s
3)cuDNN convolution
论文采用的是将卷积转化为矩阵乘法的方法,利用NVIDIA的矩阵乘法的特点,做了一些改进。
具体来说就是,计算F(卷积核)对D(输入的feature map)的卷积,并不是将D转化后的二维矩阵直接存到显存里面,而是lazily materialing的方式。就是说,当需要用到这部分数据的时候,直接到D中索引对应的数据,并加载到显存里面进行计算,这样就避免了占用额外显存这一弊端。
因此该方法还需要一个快速从D中索引数据的算法。
对A x B = C, 分块加载A和B从off-chip memory to on-chip caches, 同时计算C的一部分。这样减少了数据传输带来的延迟。对于扩大的input data,我们是在on-chip上转换成扩大的input data,而不是在off-chip上转换。
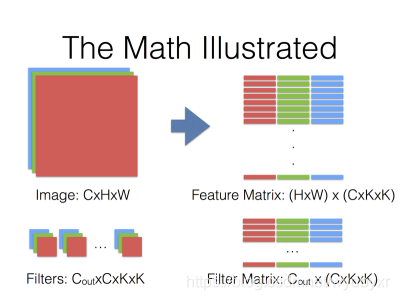
4)caffe中实现的方法(NVIDIA的矩阵乘法)
将卷积操作转换为密集矩阵相乘。将input data组装成大小为CRS x NPQ的矩阵,这使得内存相对原始input data的大小扩大了之多RS(即kernel_size的平方)倍。
这种方法使用扩大临时内存方法换取密集矩阵计算的便利。
卷积核越大,stride越小,显存耗费越高。
参考资料:http://blog.csdn.net/mounty_fsc/article/details/51290446
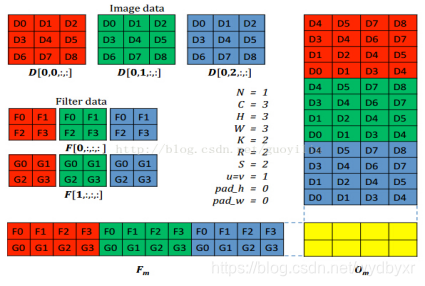
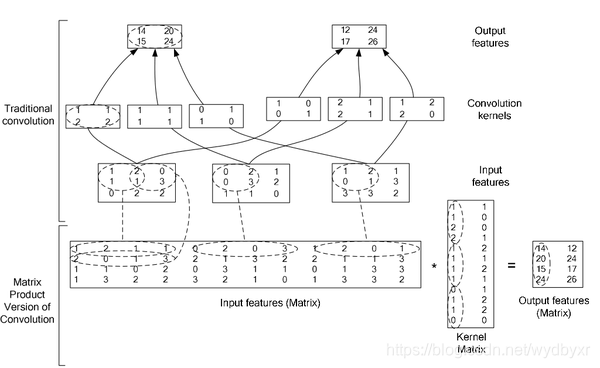
更详细
下图,更详细地介绍NVIDIA的矩阵乘法。
最后,Filter Matrix乘以Feature Matrix的转置,得到输出矩阵Cout x (H x W),就可以解释为输出的三维Blob(Cout x H x W)。