卷积层的数据shape和普通层的数据shape差别:
针对一般图像数据shape: Npq,图像就是二维浮点数据,N为数据个数,p,q为图像的维度。
卷积层的中间层数据shape: Npq*r,r为channels。
数据的shape必须非常清楚,因为假如自己处理卷积层就需要用到shape
卷积层实现
1、卷积层自身多了 Kernel 这个属性并因此带来了诸如 Stride、Padding 等属性,不过与此同时、卷积层之间没有权值矩阵,
2、卷积层和普通层的shape属性记录的东西不同,具体而言:
普通层的shape记录着上个 Layer 和该 Layer 所含神经元的个数
卷积层的shape记录着上个卷积层的输出和该卷积层的 Kernel 的信息(注意卷积层的上一层必定还是卷积层)
3、卷积填充有2种方式,tesorflow支持两种方式:一是不填充VALID,二是全部填充SAME,没有部分填充的方式,假如需要实现部分填充,就需要在数据预处理填充0,然后使用VALID方式卷积。
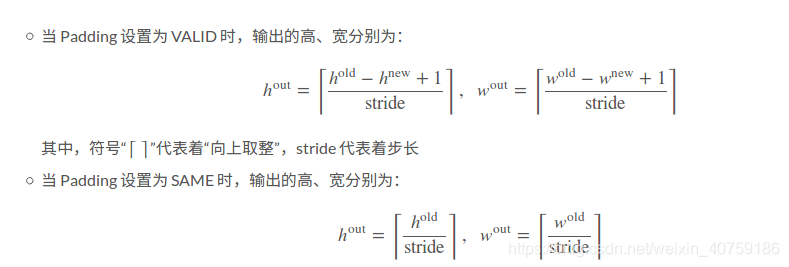
padding 可以为VALID,可以为SAME,也可以为int整型数,为int整型数时就是自填充数据。
class ConvLayer(Layer):
"""
初始化结构
self.shape:记录着上个卷积层的输出和该Layer的Kernel的信息,具体而言:
self.shape[0] = 上个卷积层的输出的形状(频道数×高×宽)
常简记为self.shape[0] =(c,h_old,w_old)
self.shape[1] = 该卷积层Kernel的信息(Kernel数×高×宽)
常简记为self.shape[1] =(f,h_new,w_new)
self.stride、self.padding:记录Stride、Padding的属性
self.parent:记录父层的属性
"""
def __init__(self, shape, stride=1, padding="SAME", parent=None):
if parent is not None:
_parent = parent.root if parent.is_sub_layer else parent
shape = _parent.shape
Layer.__init__(self, shape)
self.stride = stride
# 利用Tensorflow里面对Padding功能的封装、定义self.padding属性
if isinstance(padding, str):
# "VALID"意味着输出的高、宽会受Kernel的高、宽影响,具体公式后面会说
if padding.upper() == "VALID":
self.padding = 0
self.pad_flag = "VALID"
# "SAME"意味着输出的高、宽与Kernel的高、宽无关、只受Stride的影响
else:
self.padding = self.pad_flag = "SAME"
# 如果输入了一个整数、那么就按照VALID情形设置Padding相关的属性
else:
self.padding = int(padding)
self.pad_flag = "VALID"
self.parent = parent
if len(shape) == 1:
self.n_channels = self.n_filters = self.out_h = self.out_w = None
else:
self.feed_shape(shape)
# 定义一个处理shape属性的方法
def feed_shape(self, shape):
self.shape = shape
self.n_channels, height, width = shape[0]
self.n_filters, filter_height, filter_width = shape[1]
# 根据Padding的相关信息、计算输出的高、宽
if self.pad_flag == "VALID":
self.out_h = ceil((height - filter_height + 1) / self.stride)
self.out_w = ceil((width - filter_width + 1) / self.stride)
else:
self.out_h = ceil(height / self.stride)
self.out_w = ceil(width / self.stride)
class ConvLayerMeta(type):
def __new__(mcs, *args, **kwargs):
name, bases, attr = args[:3]
# 规定继承的顺序为ConvLayer→Layer
conv_layer, layer = bases
def __init__(self, shape, stride=1, padding="SAME"):
conv_layer.__init__(self, shape, stride, padding)
# 利用Tensorflow的相应函数定义计算卷积的方法
def _conv(self, x, w):
return tf.nn.conv2d(x, w, strides=[self.stride] * 4, padding=self.pad_flag)
# 依次进行卷积、激活的步骤
def _activate(self, x, w, bias, predict):
res = self._conv(x, w) + bias
return layer._activate(self, res, predict)
# 在正式进行前向传导算法之前、先要利用Tensorflow相应函数进行Padding
def activate(self, x, w, bias=None, predict=False):
if self.pad_flag == "VALID" and self.padding > 0:
_pad = [self.padding] * 2
x = tf.pad(x, [[0, 0], _pad, _pad, [0, 0]], "CONSTANT")
return _activate(self, x, w, bias, predict)
# 将打包好的类返回
for key, value in locals().items():
if str(value).find("function") >= 0:
attr[key] = value
return type(name, bases, attr)
class ConvReLU(ConvLayer, ReLU, metaclass=ConvLayerMeta):
pass
实现池化层
对于最常见的两种池化——极大池化和平均池化,Kernel 个数从数值上来说与输出频道个数一致,所以对于池化层的实现而言、我们应该直接用输入频道数来赋值 Kernel 数,因为池化不会改变数据的频道数。
class ConvPoolLayer(ConvLayer):
def feed_shape(self, shape):
shape = (shape[0], (shape[0][0], *shape[1]))
ConvLayer.feed_shape(self, shape)
def activate(self, x, w, bias=None, predict=False):
pool_height, pool_width = self.shape[1][1:]
# 处理Padding
if self.pad_flag == "VALID" and self.padding > 0:
_pad = [self.padding] * 2
x = tf.pad(x, [[0, 0], _pad, _pad, [0, 0]], "CONSTANT")
# 利用self._activate方法进行池化
return self._activate(None)(
x, ksize=[1, pool_height, pool_width, 1],
strides=[1, self.stride, self.stride, 1], padding=self.pad_flag)
def _activate(self, x, *args):
pass
# 实现极大池化
class MaxPool(ConvPoolLayer):
def _activate(self, x, *args):
return tf.nn.max_pool
# 实现平均池化
class AvgPool(ConvPoolLayer):
def _activate(self, x, *args):
return tf.nn.avg_pool
实现 CNN 中的特殊层结构
在 CNN 中同样有着 Dropout 和 Normalize 这两种特殊层结构,CNN 则通常是N×p×q×r的、其中r是当前数据的频道数。将 CNN 中r个频道的数据放在一起并视为 NN 中的一个神经元,这样做的话就能通过简易的封装来直接利用上我们对 NN 定义的特殊层结构。
# 定义作为封装的元类
class ConvSubLayerMeta(type):
def __new__(mcs, *args, **kwargs):
name, bases, attr = args[:3]
conv_layer, sub_layer = bases
def __init__(self, parent, shape, *_args, **_kwargs):
conv_layer.__init__(self, None, parent=parent)
# 与池化层类似、特殊层输出数据的形状应保持与输入数据的形状一致
self.out_h, self.out_w = parent.out_h, parent.out_w
sub_layer.__init__(self, parent, shape, *_args, **_kwargs)
self.shape = ((shape[0][0], self.out_h, self.out_w), shape[0])
# 如果是CNN中的Normalize、则要提前初始化好γ、β
if name == "ConvNorm":
self.tf_gamma = tf.Variable(tf.ones(self.n_filters), name="norm_scale")
self.tf_beta = tf.Variable(tf.zeros(self.n_filters), name="norm_beta")
# 利用NN中的特殊层结构的相应方法获得结果
def _activate(self, x, predict):
return sub_layer._activate(self, x, predict)
def activate(self, x, w, bias=None, predict=False):
return _activate(self, x, predict)
# 将打包好的类返回
for key, value in locals().items():
if str(value).find("function") >= 0 or str(value).find("property"):
attr[key] = value
return type(name, bases, attr)
# 定义CNN中的Dropout,注意继承顺序
class ConvDrop(ConvLayer, Dropout, metaclass=ConvSubLayerMeta):
pass
# 定义CNN中的Normalize,注意继承顺序
class ConvNorm(ConvLayer, Normalize, metaclass=ConvSubLayerMeta):
pass
实现 LayerFactory
集合所有的layer,这样就可以通过字符串索引到对应的layer
class LayerFactory:
# 使用一个字典记录下所有的Root Layer
available_root_layers = {
"Tanh": Tanh, "Sigmoid": Sigmoid,
"ELU": ELU, "ReLU": ReLU, "Softplus": Softplus,
"Identical": Identical,
"CrossEntropy": CrossEntropy, "MSE": MSE,
"ConvTanh": ConvTanh, "ConvSigmoid": ConvSigmoid,
"ConvELU": ConvELU, "ConvReLU": ConvReLU, "ConvSoftplus": ConvSoftplus,
"ConvIdentical": ConvIdentical,
"MaxPool": MaxPool, "AvgPool": AvgPool
}
# 使用一个字典记录下所有特殊层
available_special_layers = {
"Dropout": Dropout,
"Normalize": Normalize,
"ConvDrop": ConvDrop,
"ConvNorm": ConvNorm
}
# 使用一个字典记录下所有特殊层的默认参数
special_layer_default_params = {
"Dropout": (0.5,),
"Normalize": ("Identical", 1e-8, 0.9),
"ConvDrop": (0.5,),
"ConvNorm": ("Identical", 1e-8, 0.9)
}
# 定义根据“名字”获取(Root)Layer的方法
def get_root_layer_by_name(self, name, *args, **kwargs):
# 根据字典判断输入的名字是否是Root Layer的名字
if name in self.available_root_layers:
# 若是、则返回相应的Root Layer
layer = self.available_root_layers[name]
return layer(*args, **kwargs)
# 否则返回None
return None
# 定义根据“名字”获取(任何)Layer的方法
def get_layer_by_name(self, name, parent, current_dimension, *args, **kwargs):
# 先看输入的是否是Root Layer
_layer = self.get_root_layer_by_name(name, *args, **kwargs)
# 若是、直接返回相应的Root Layer
if _layer:
return _layer, None
# 否则就根据父层和相应字典进行初始化后、返回相应的特殊层
_current, _next = parent.shape[1], current_dimension
layer_param = self.special_layer_default_params[name]
_layer = self.available_special_layers[name]
if args or kwargs:
_layer = _layer(parent, (_current, _next), *args, **kwargs)
else:
_layer = _layer(parent, (_current, _next), *layer_param)
return _layer, (_current, _next)
网络结构
class NN(ClassifierBase):
def __init__(self):
super(NN, self).__init__()
self._layers = []
self._optimizer = None
self._current_dimension = 0
self._available_metrics = {
key: value for key, value in zip(["acc", "f1-score"], [NN.acc, NN.f1_score])
}
self.verbose = 0
self._metrics, self._metric_names, self._logs = [], [], {}
self._layer_factory = LayerFactory()
# 定义Tensorflow中的相应变量
self._tfx = self._tfy = None # 记录每个Batch的样本、标签的属性
self._tf_weights, self._tf_bias = [], [] # 记录w、b的属性
self._cost = self._y_pred = None # 记录损失值、输出值的属性
self._train_step = None # 记录“参数更新步骤”的属性
self._sess = tf.Session() # 记录Tensorflow Session的属性
# 利用Tensorflow相应函数初始化参数
@staticmethod
def _get_w(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name="w")
@staticmethod
def _get_b(shape):
return tf.Variable(np.zeros(shape, dtype=np.float32) + 0.1, name="b")
# 做一个初始化参数的封装,要注意兼容CNN
def _add_params(self, shape, conv_channel=None, fc_shape=None, apply_bias=True):
# 如果是FC的话、就要根据铺平后数据的形状来初始化数据
if fc_shape is not None:
w_shape = (fc_shape, shape[1])
b_shape = shape[1],
# 如果是卷积层的话、就要定义Kernel而非权值矩阵
elif conv_channel is not None:
if len(shape[1]) <= 2:
w_shape = shape[1][0], shape[1][1], conv_channel, conv_channel
else:
w_shape = (shape[1][1], shape[1][2], conv_channel, shape[1][0])
b_shape = shape[1][0],
# 其余情况和普通NN无异
else:
w_shape = shape
b_shape = shape[1],
self._tf_weights.append(self._get_w(w_shape))
if apply_bias:
self._tf_bias.append(self._get_b(b_shape))
else:
self._tf_bias.append(None)
# 由于特殊层不会用到w和b、所以要定义一个生成占位符的方法
def _add_param_placeholder(self):
self._tf_weights.append(tf.constant([.0]))
self._tf_bias.append(tf.constant([.0]))