本文介绍序列标注/信息抽取任务。
我写了个信息抽取经典论文的石墨文档,但是我发现现在公开发布需要会员了,请大家加我V给我赞助一笔会员费,让我能够公开文档:
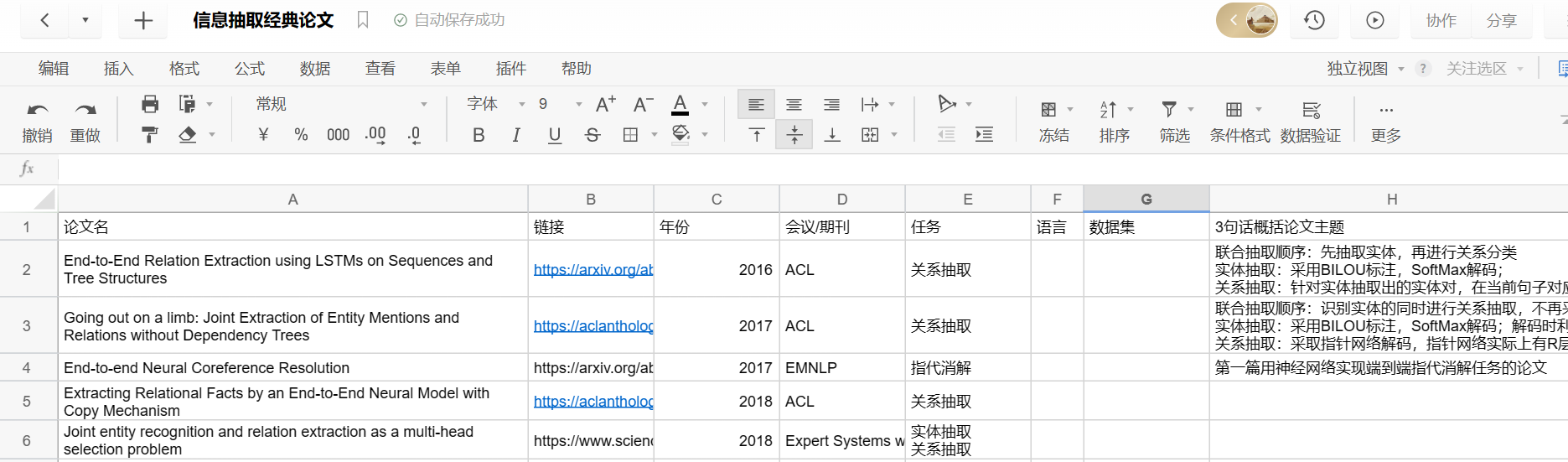
最近更新时间:2023.5.30
最早更新时间:2023.4.20
1. 任务定义和分类
- 什么是序列标注任务?
回答来自ChatGPT:
序列标注是自然语言处理中的一类任务,它涉及对自然语言文本进行标注,即对文本中的每个词或子词分配一个标签或类别。序列标注任务通常包括命名实体识别 (NER)、词性标注 (POS)、语块分析 (Chunking)、词义消歧 (WSD) 等,这些任务都可以被看作是将输入序列中的每个元素映射到输出序列中的每个元素的过程。
在序列标注任务中,输入通常是一个单词序列或字符序列,而输出则是一个标签序列,标签序列与输入序列一一对应,其中每个标签表示与输入序列中对应的元素的类别或属性。例如,在命名实体识别任务中,输入是一段文本,输出是该文本中每个实体的类别(如人名、地名等),对应于输入序列中每个词或子词。
序列标注任务是自然语言处理中的重要问题,它们广泛应用于信息提取、机器翻译、问答系统、自动摘要、情感分析等多个领域。 - 什么是信息抽取任务?
回答来自ChatGPT:
信息抽取(Information Extraction, IE)是自然语言处理领域中的一项任务,旨在从文本中自动识别和提取特定类型的结构化信息,例如实体、关系和事件等。
通常情况下,信息抽取任务包括实体识别、关系抽取和事件抽取三个子任务:
实体识别:识别文本中具有特定含义的命名实体,如人名、地名、组织机构名等。
关系抽取:在文本中识别并提取实体之间的语义关系,如“X是Y的父亲”、“X与Y是夫妻关系”等。
事件抽取:从文本中抽取事件,并识别出事件的组成要素,如触发词、事件类型、参与者、时间等。
信息抽取任务广泛应用于信息检索、知识图谱构建、自然语言问答等领域。 - 信息抽取任务和序列标注任务有什么关系?
回答来自ChatGPT:
信息抽取任务和序列标注任务有一定的关系,因为信息抽取可以看作是序列标注任务的一种特殊情况。在信息抽取任务中,我们需要从给定的文本中抽取出特定的信息,比如实体、关系等。而在序列标注任务中,我们需要将给定的文本进行标注,比如命名实体识别中,我们需要标注出文本中的人名、地名、组织机构名等实体。
在信息抽取任务中,我们可以将需要抽取的信息看作是序列标注任务中的实体,我们可以用相应的标签来标注这些实体的位置和类型,然后使用相应的模型进行抽取。因此,序列标注任务可以被视为信息抽取任务的一种简化形式。 - 序列标注任务,有什么除信息抽取任务之外的典型任务?
回答改自ChatGPT:
除了信息抽取任务,序列标注任务还有很多典型任务,比如词性标注、命名实体识别、分句、分词等等。这些任务都需要对输入序列中的每个单元进行标注,以便后续的自然语言处理任务能够更好地理解和处理这些文本数据。序列标注任务在自然语言处理中应用广泛,是很多文本处理任务的基础。 - 常见序列标注任务:实体抽取 简介
回答来自ChatGPT:
实体抽取是自然语言处理中的一项重要任务,指从文本中抽取出具有特定意义的实体,例如人名、组织机构、地名、时间、日期、货币、百分比等等。实体抽取任务通常可以分为两个子任务:命名实体识别(Named Entity Recognition, NER)和实体链接(Entity Linking, EL)。
NER 是指在给定的文本中,自动识别和分类出命名实体,即将文本中的实体识别出来,并将其分类为人名、组织机构、地名、时间、日期、货币、百分比等标准实体类型。NER 可以应用于很多领域,比如信息提取、问答系统、机器翻译等,是自然语言处理中的重要任务之一。
EL 是指将文本中的实体链接到现实世界中的知识库中。例如,一个文本中提到了“北京”,实体链接任务就是将这个“北京”链接到现实世界中对应的地理位置,比如中国北京市。EL 可以帮助机器理解文本,提高信息检索、问答系统等任务的效果。
实体抽取任务是自然语言处理中的经典问题之一,也是信息抽取任务中的重要部分。 - 常见序列标注任务:关系抽取 简介
回答来自ChatGPT:
关系抽取(Relation Extraction)是自然语言处理领域中的一项任务,其目标是从文本中抽取出实体之间的关系。
在关系抽取任务中,通常需要先进行实体识别,即识别文本中的实体,并确定它们的类别。接着,需要对这些实体进行关系抽取,找出它们之间的关系类型和关系结构。
例如,在一个句子中,“John works at Microsoft”(John 在微软工作),我们需要识别出实体“John”和“Microsoft”,并确定它们的类别(人名和公司名)。然后,我们需要抽取出它们之间的关系,即“工作”关系。
关系抽取任务在信息提取、文本分类、知识图谱构建等领域中具有重要的应用价值。近年来,随着深度学习技术的发展,基于神经网络的关系抽取方法也得到了广泛的研究和应用。 - 事件检测/事件抽取
我看具体的介绍,不同的渠道有不同的说法。总之大略来说是这么一回事,说起来好像有区别,但是一般我看都是混用的。就当是同一件事好了。
推一下我自己写的博文:NLP基础知识 | 常见任务类型 | 事件检测 有配图的示例- 常见序列标注任务:事件抽取 简介
回答来自ChatGPT:
事件抽取任务是从文本中提取出事件类型、事件参与者以及事件触发词等信息的任务。具体来说,事件抽取任务要求从文本中抽取出具体的事件类型,以及与该事件相关的主体、客体等信息,并确定这些信息之间的关系。
事件抽取任务可以被看作是实体抽取任务的扩展,因为它需要从文本中抽取出更复杂的信息。相比于实体抽取任务,事件抽取任务更加具有挑战性,因为它需要同时考虑多个实体之间的关系,并对这些关系进行建模和分类。
举例来说,假设我们有一篇新闻报道:“今天早上,一辆卡车在市中心撞上了一辆小汽车,造成3人受伤”。对于这篇报道,事件抽取任务需要从中抽取出“车祸”这个事件类型,以及与该事件相关的实体,如“卡车”、“小汽车”、“市中心”、“受伤者”等,以及这些实体之间的关系,如“卡车”和“小汽车”之间的“碰撞”关系。 - 常见序列标注任务:事件检测简介
回答来自ChatGPT:
事件检测是指从文本中识别出事件并将其分类为不同的事件类型。事件通常由触发词和与该词相关的一组实体组成,而事件类型描述了事件的本质属性。事件检测任务是NLP中的一个重要任务,可用于自然语言理解、信息提取、情感分析等应用领域。
事件检测任务通常包含以下步骤:
触发词检测:在文本中识别可能的事件触发词;
实体识别:确定与触发词相关的实体;
事件类型分类:将事件分类为事先定义好的事件类型。
例如,在一句话中,“上个月苹果公司发布了新款iPhone手机。”中,“发布”是事件触发词,“苹果公司”是事件中的实体,“发布”事件类型为“产品发布”。
事件检测任务的难点在于事件的多样性和复杂性。不同类型的事件可以涉及不同的实体、关系和动作,并且它们的表示方式和上下文都可能不同。因此,事件检测需要进行多层次的文本理解,包括词法分析、句法分析、语义分析等。 - 事件抽取和事件检测分别是什么任务,有什么关系?
回答来自ChatGPT:
事件抽取和事件检测都是信息抽取任务中的一类,主要任务是从自然语言文本中抽取出与特定事件相关的信息。
事件抽取通常是指从文本中抽取出事件类型、事件触发词以及与该事件相关的实体和时间等信息。事件抽取通常分为两个子任务:事件触发词识别和事件论元识别。事件触发词指的是表达某种事件发生的关键词或短语,事件论元则是事件中扮演重要角色的实体、时间等信息。
而事件检测则是指对文本中的事件进行识别和分类,其主要任务是对文本中的每一个事件进行分类,以及识别出触发该事件的单词或短语,并为每个事件识别和标注出相关信息。与事件抽取相比,事件检测更加注重对事件类别的分类和对事件的全面理解。
因此,可以说事件抽取是事件检测任务中的一部分。事件抽取通常是指从文本中提取出事件触发词和事件论元信息,而事件检测是在事件抽取的基础上对事件进行分类识别。
- 常见序列标注任务:事件抽取 简介
- 常见序列标注任务:词性标注 简介
回答来自ChatGPT:
词性标注(Part-of-Speech Tagging,简称POS)是自然语言处理中的一项重要任务,旨在为给定文本中的每个单词标注一个词性标签。词性标签可以指示该单词在语法结构中的作用,例如名词、动词、形容词等。
词性标注常常是许多自然语言处理任务的前置任务,如句法分析、机器翻译、文本分类等。词性标注的目标是通过对单词进行标注来自动识别文本中的语法结构,帮助自然语言处理系统更好地理解文本。词性标注通常使用训练有素的机器学习算法,如隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Fields,CRF)。
例如,对于句子“我喜欢吃苹果”,词性标注任务将对该句子进行标注,给每个单词赋予一个词性标签,如下所示:
我/代词 喜欢/动词 吃/动词 苹果/名词
通过标注每个单词的词性,可以帮助自然语言处理系统更好地理解句子的语法结构,从而进行更深入的分析和处理。 - 常见序列标注任务:命名实体识别/NER 简介
回答来自ChatGPT:
命名实体识别(Named Entity Recognition,简称NER)是一种序列标注任务,旨在从文本中识别并提取出命名实体。命名实体通常指具有特定意义的实体,如人名、地名、组织机构名、时间、日期、货币等。
NER任务的目标是将文本中的每个词标注为以下几种实体类型之一:人名、地名、组织机构名、时间、日期、货币和其它自定义实体类型。NER任务通常被广泛应用于信息提取、机器翻译、问答系统等自然语言处理任务中。
NER任务的实现方法主要包括基于规则的方法、统计机器学习方法和深度学习方法。近年来,深度学习方法在NER任务中取得了很大的成功,特别是序列标注模型,如CRF、LSTM-CRF、BERT等,在NER任务中表现优异,成为了当前主流的解决方案。 - (看到上面ChatGPT的回复,很自然会联想到的一个任务)命名实体识别还有不用序列标注的解决方案吗?
回答来自ChatGPT:
除了序列标注之外,还有其他一些命名实体识别的解决方案,比如:
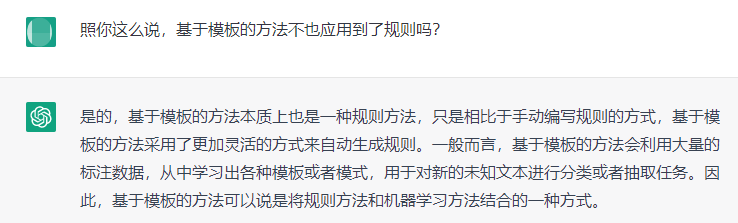
基于规则的方法:通过手动编写规则,来实现对命名实体的识别,这种方法的缺点是需要大量的人力去编写规则,并且无法覆盖所有的情况,同时也难以应对一些复杂的场景。
基于模板的方法:通过预定义的模板,来抽取出满足特定模板的文本片段,从而实现对命名实体的识别,这种方法需要事先定义好模板,但可以应对一定程度的文本变化。
基于词典的方法:通过建立一个包含命名实体的词典,来进行命名实体识别。这种方法的优点是可以很快速地对命名实体进行识别,缺点是需要大量的人力去构建词典,并且无法识别词典之外的命名实体。
基于机器学习的方法:与序列标注相似,通过机器学习算法学习从文本到命名实体标签的映射关系。这种方法的优点是可以自适应地学习文本的特征,缺点是需要大量的标注数据和计算资源。
(问了一下ChatGPT这两种古典方法的区别,感觉……也无法分辨明晰)


- 常见序列标注任务:分句简介
回答来自ChatGPT:
分句(句子分割)任务是自然语言处理中的一个基本任务,其目标是将一个包含多个句子的文本分割成多个句子。分句任务通常被认为是文本处理的第一步,因为它将文本划分成了可以独立处理的基本单元,为后续任务如词性标注、命名实体识别等打下基础。
分句任务的难点在于:有些句子可能包含缩写、数字、日期、省略号等特殊情况,使得基于标点符号的简单切分方法无法准确地判断句子的结束位置。
目前,主流的分句算法通常采用基于机器学习的方法,如基于规则、基于统计和基于深度学习等。其中,基于深度学习的方法,如使用卷积神经网络、循环神经网络和Transformer等模型,已经成为当前分句任务的主流解决方案。 - 常见序列标注任务:分词简介
回答来自ChatGPT:
分词任务是指将一段连续的文本切分成单词或词汇的任务。在自然语言处理中,分词任务是最基本的任务之一,也是许多其他自然语言处理任务的基础,如词性标注、命名实体识别、句法分析等。分词任务主要面临的挑战是多义词、歧义词和未登录词等问题,因此需要考虑上下文信息和语言学知识,例如词性、词性转换规则、命名实体等。
分词任务的解决方法包括基于规则的方法、基于统计的方法和基于深度学习的方法。基于规则的方法使用手工编写的规则来分割文本,例如使用空格分隔单词、使用标点符号分隔句子等。基于统计的方法则是根据大规模语料库中的统计信息来进行分词,例如使用最大匹配算法、最大概率模型等。而基于深度学习的方法则是利用深度神经网络来进行端到端的分词任务,例如使用卷积神经网络、循环神经网络和注意力机制等。 - 指代消解 (coreference resolution)1
回答来自ChatGPT:
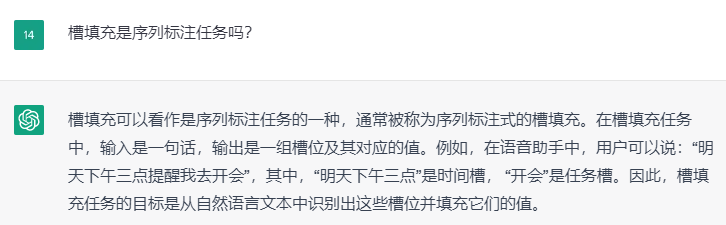
指代消解 (coreference resolution) 是指在文本中识别出两个或多个代表同一实体的词汇,并将它们归并在一起,从而理解文本中实体之间的关系。例如:在一个新闻报道中,当我们看到“美国总统奥巴马”和“他”这两个词时,我们能够理解“他”指的是“美国总统奥巴马”。 - 槽填充任务也算是序列标注任务,但因为槽填充任务往往与意图检测任务耦合,所以本文就不主要关注这一任务了。
2. 任务
2.1 分词tokenization
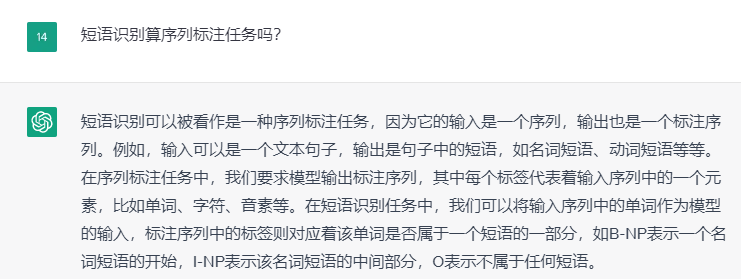
2.2 短语识别

2.3 分句 / 句子边界检测
英文可以用spacy包,可以参考我之前写的教程:spacy教程(持续更新ing…)
中文,可参考的分句用标点符号:。:();:“”,,
2.4 命名实体识别NER (named entity recognition)
- nested
- StanleyLsx/entity_extractor_by_pointer: 使用torch整合两种经典的指针NER抽取范式,分别是SpanBert和苏神的GlobalPointer,简单加了些tricks,配置后一键运行
- https://hanlp.hankcs.com/demos/ner.html
- (2021 ESWA CCF-C刊) Randomly Wired Graph Neural Network for Chinese NER
2.5 词性标注PoS Tagging
2.6 实体抽取
2.7 关系抽取relation extraction
扫描二维码关注公众号,回复:
15188092 查看本文章

2.8 事件检测/事件抽取
- 术语

- 实体
- 事件触发词event trigger(质押)
- 事件类型event type
- 事件论元Event Argument:参与事件发生的要素,由实体构成(斜体+下划线)
- 论元角色Argument Role
- 参考博文
2.9 measurement extraction
感觉越看越多。
决定用这个主题来写读书报告了,等我读书报告交了再写公开博文。
2.10 指代消解coreference resolution
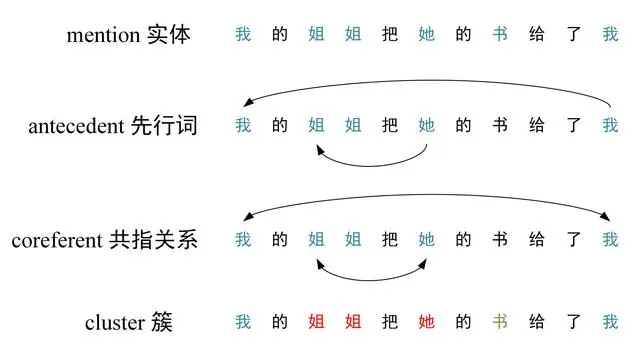
- mention 可以理解为文本中的实体
- antecedent 指先行词,例如句子 “我的姐姐把她的书给了我” 中 “姐姐” 和 “她” 指代相同,“姐姐” 出现在 “她” 之前,因此 “姐姐” 是 “她” 的先行词。
- coreferent 共指关系,例如上面的 “姐姐” 和 “她” 之间存在共指关系。
- cluster 表示簇,一个簇里面的所有词指代同一个对象。
- span 区间
- End-to-end Neural Coreference Resolution:第一篇使用神经网络对指代消解进行端到端 (End-to-end) 处理的论文2
3. 数据集
3.1 通用任务
3.2 事件/关系抽取
- 事件之间的关系:RichieLee93/EDeR: A Dataset for Event Dependency Relation Extraction
- 属于千言数据集:IREE:投资领域细颗粒度风险事件抽取数据集
- WebNLG和NYC:xiangrongzeng/copy_re: Release for acl18 paper “Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism”
3.3 NER
- davidsbatista/NER-datasets: Datasets to train supervised classifiers for Named-Entity Recognition in different languages (Portuguese, German, Dutch, French, English)
- 属于千言数据集:CNERTA中文多模态命名实体识别数据集
4. 通用解决方案
- 标注范式
- BIO格式(又名IOB格式)3
- BIOSE
- IOB
- BILOU
- BMEWO
- BMEWO+
- PaddlePaddle实现:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/information_extraction/text
- PaddlePaddle的解决方案基于UIE4
- loujie0822/DeepIE: DeepIE: Deep Learning for Information Extraction
- nlp中的实体关系抽取方法总结 - 知乎
- 医学领域信息抽取评测的解决方案:刷爆3路榜单,信息抽取冠军方案分享:嵌套NER+关系抽取+实体标准化 - 知乎
- NLP系列之实体识别/关系抽取(二):序列标注/层叠式指针网络/Multi-head Selection/Deep Biaffine Attention(附实验代码) - 知乎 https://github.com/zhoujx4/NLP-Series-relation-extraction
5. 其他本文撰写过程中参考的网络资料
- 论元抽取笔记(一)_Andy Dennis的博客-CSDN博客
- 【深度学习】信息抽取方法综述 - 知乎:值得一看,还没看完
- ACL&AAAI顶会分享:揭开事件检测的神秘面纱:就看了一点事件检测的概念介绍