深度学习知识随记
1、野生知识
- 抛弃Dropout & 全连接层 → 过拟合、梯度弥散
- 残差结构:缓解梯度爆炸、消失 & 网络退化问题
- 偏置项(bias): 是对神经元激活状态的控制,增加函数灵活性,提高神经元的拟合能力。
- **残差连接:**防止网络退化,加快收敛,防止梯度消失(标配,如同BN)
stride
padding
bn层
激活函数
损失函数
2、特征金字塔(FPN)
- 特征金字塔(Feature Pyraid Network):提供多尺度的特征表示,解决了金字塔结构计算量过高,又能较好处理目标检测中的多尺度变化问题
- FPN:第一阶段是自底向上的卷积操作,第二阶段是自顶向下的上采样和特征融合过程
- 将特征金字塔网络衔接在主干网络后,可以让不同尺度的特征图都具有较强的语义信息。
3、多尺度变化(Multi-scale variation)
- 多尺度变化(Multi-scale variation) 是指同一个物体或场景在不同尺度上具有不同的表现形式。
- 例如,同一张照片中的人物可能在不同的位置和大小,或者同一个物体在不同的场景中可能呈现出不同的大小和形状。
- 如果只使用单一尺度的特征表示,难以处理图像中物体大小和位置变化(即多尺度变化),算法性能会下降。这就需要多尺度技术,例如特征金字塔、图像金字塔、滑动窗口等。
4、epoch & batch & iteration
- epoch: 是整个训练集数据样本都输入到模型里面了,称为一个epoch。
- iteration: 是一批样本输入到模型中,就称为一个iteration。
- batchsize: 是批大小,
- 假设我们有一个数据集,里面包含80张图片,我把batchsize 设置为8,那么我们需要10个iteration才能训练完整个数据集,就是一个 epoch
- 不同尺寸的图片无法组成 batch
5、混淆矩阵(confusion matrix)
- 混淆矩阵是一种常用的评估分类模型性能的工具,它显示了每个实际类别与每个预测类别之间的匹配情况。
- 它的对角线元素表示分类正确的样本数,而其他元素表示错误分类的样本数。
图1 混淆矩阵:深蓝色表示正确预测;浅蓝色表示错误预测
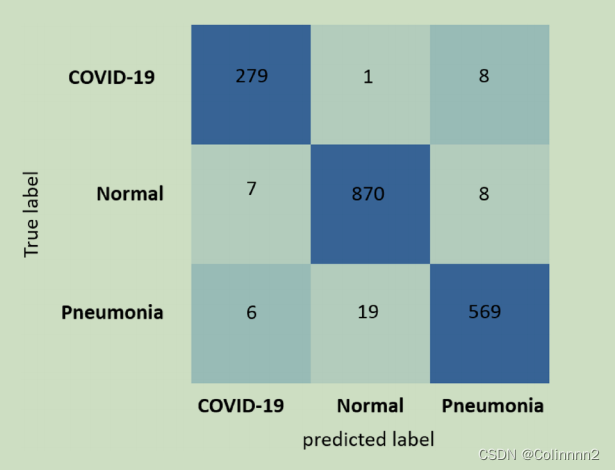
- 如下为示例代码:使用 sklearn 库中的 confusion_matrix 函数来计算混淆矩阵。
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(label, output) # label:真实标签。output:预测标签
代码解释:
- 这段代码是使用 sklearn 库中的 confusion_matrix 函数来计算混淆矩阵。
- 混淆矩阵的计算需要输入两个向量:真实标签和预测标签。
- confusion_matrix函数将这两个向量作为输入,计算出混淆矩阵并将其保存在一个名为cm的变量中。
- 在机器学习中,混淆矩阵是一个用于展示分类模型性能的矩阵。它将模型的预测结果按照真实标签进行分类
- 并计算出四个值:真正例(True Positive,TP)、假正例(False Positive,FP)、真反例(True Negative,TN)和假反例(False Negative,FN)。
- 其中,真正例表示模型正确地预测了正例,假正例表示模型错误地将负例预测为正例,真反例表示模型正确地预测了负例,假反例表示模型错误地将正例预测为负例。
6、为什么将数据移到CPU上?
- 内存限制:GPU上的内存通常比CPU上的内存小得多。当模型或数据的大小超出GPU内存的限制时,需要将其转移到CPU上进行处理。
- 预处理或后处理:有些数据需要进行预处理或后处理,这些处理可能无法在GPU上完成。例如,将数据保存到磁盘上或者进行可视化时,通常需要将数据转移到CPU上。
- 与第三方库的兼容性:有些第三方库(如OpenCV)不支持GPU上的张量操作。在这种情况下,需要将数据或模型转移到CPU上,以便于与第三方库进行交互和处理。
7、metadata(元数据)
- 在数据集中,metadata(元数据)是描述数据的数据,通常是关于数据集的信息,例如数据集的名称、创建日期、创建者、大小、格式、单位、变量名称、变量类型、缺失值等等。元数据通常不包含数据本身,而是提供了有关数据的信息和描述,以帮助人们理解和使用数据。
- 元数据对于有效管理和使用数据集非常重要。它们可以帮助人们了解数据集的结构和内容,以及如何正确地解释和分析数据。此外,元数据还可以帮助人们在使用数据时遵守法律、规定和标准,从而确保数据的质量和一致性。
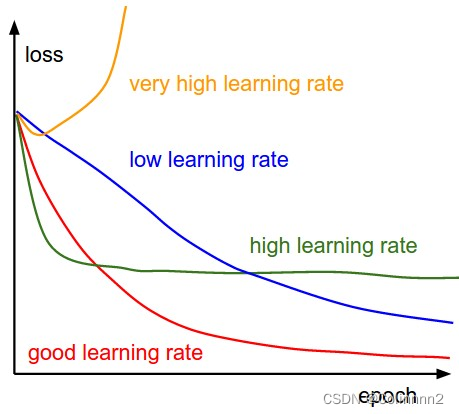
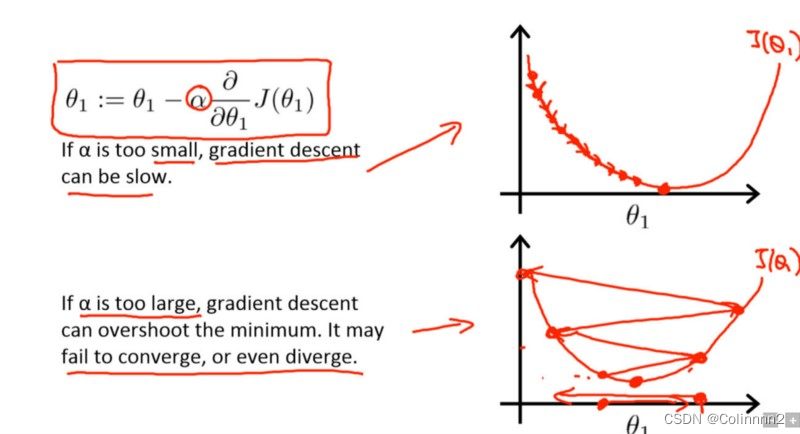
8、学习率(Learning Rate)
学习率(Learning Rate)是深度学习中一个非常重要的超参数,它控制了模型在训练过程中对于每次更新的权重调整的大小。
学习率的大小将直接影响到模型在训练过程中的速度和效果
new_weight = existing_weight — learning_rate * gradient
图片来源:吴恩达机器学习课程
不同学习速率对收敛的影响(图片来源:cs231n)