第三章使用 TypeScript 编写爬虫工具
爬去 官网的 项目名称 和 当前课程学习人数
1. 构建 TypeScript文件目录 项目
1. npm init -y。 项目中新增package.json文件
2. tsc --init。 项目中新增tsconfig.json文件
3. npm uninstall ts-node -g 全局卸载ts-node
4. cnpm install -D ts-node 在本地项目中配置ts-node
5. 新建src目录,创建crowller.ts。 console.log(‘项目初始化完毕’)
6. 修改package.json配置,使用 npm run dev 启动
"scripts": { "dev": "ts-node ./src/crowller.ts" },
7. npm install typescript -D 本地安装typescript
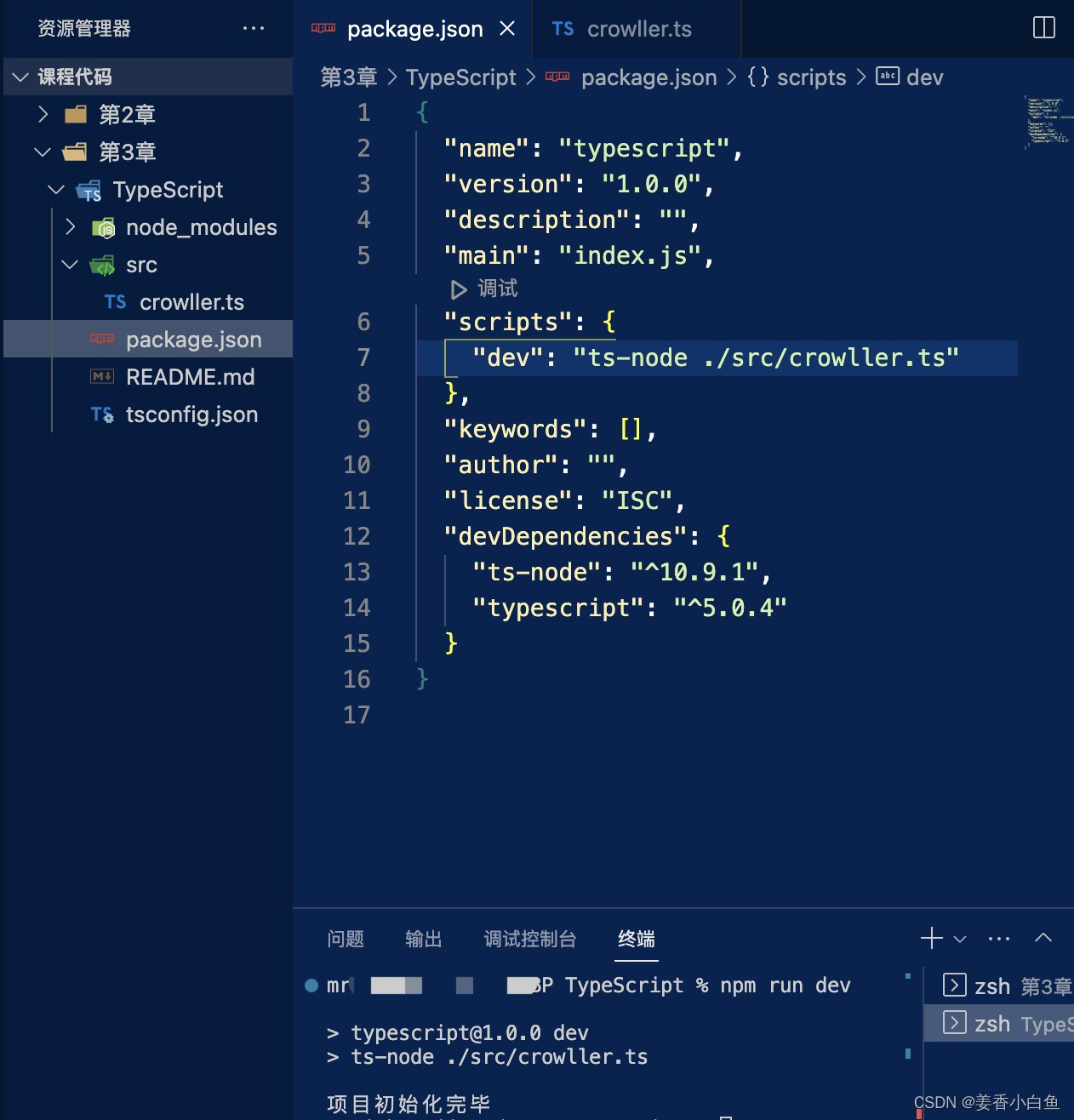
构建完成后的 package.json文件
{
"name": "typescript",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"dev": "ts-node ./src/crowller.ts"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"ts-node": "^10.9.1",
"typescript": "^5.0.4"
}
}
控制台终端 npm run dev
2. 爬取网址html上的数据内容
1. 通过 superagent 这个工具 获取网址上面,html的内容
2. js库ts无法直接读取 cnpm install superagent–save
3. ts使用翻译文件 @types/引入js库 cnpm install @types/superagent -D
/**
* 创建一个 名称为Crowller的类
* 访问类型
* public 允许 在类的内外被调用
* private 允许 在类内部被使用,不允许类外部使用
* protected 允许 在类内及 继承的子类中被使用,不允许类外使用
* ts 无法直接引用 js库 ,需要一个.d.ts的翻译文件,才可以引入 js库
*/
/* 通过 superagent 这个工具 获取网址上面,html的内容
js库ts无法直接读取 cnpm install superagent--save
ts使用翻译文件 @types/引入js库 cnpm install @types/superagent -D
*/
import superagent from 'superagent';
// cnpm install cheerio--save |cnpm install @types/cheerio -D
class Crowller {
// 慕课网准备的 地址,最后参数会有变动,到时改这个就行。
private secret = 'secretkey';
// 慕课网准备的 爬取数据的官网
private url = `http://www.dell-lee.com/typescript/demo.html?secret=${this.secret}`;
// 定义个参数,存放爬取到的html内容
private rawHtml = '';
// 定义 爬取 网站 对应的 最原始html内容
async getRawHtml() {
// superagent.get(url).then 它是一个promise返回值
const result = await superagent.get(this.url);
console.log(result.text);
// 赋值 给定义的参数
this.rawHtml = result.text
}
// constructor 在这个类被new的时候,瞬间执行,生成一个实例挂载到类上
constructor() {
// 获取最原始 html的内容
this.getRawHtml();
// console.log('测试是否成功运行');
}
}
// 有了类,下面创建一个实例
const crowller = new Crowller()
通过 npm run dev 运行 ts 文件
下载 cheerio js库解析html 模版
- cnpm install cheerio–save | cnpm install @types/cheerio -D
- 解析 html标签,取出里面内容
- 参考 js库地址 https://github.com/cheeriojs/cheerio
3. 编写爬虫文件,这样一个爬虫文件就初步构建完成了
/* 通过 superagent 这个工具 获取网址上面,html的内容
js库ts无法直接读取 cnpm install superagent--save
ts使用翻译文件 @types/引入js库 cnpm install @types/superagent -D
*/
import superagent from 'superagent';
/* cnpm install cheerio--save | cnpm install @types/cheerio -D
解析 html标签,取出里面内容
参考 js库地址 https://github.com/cheeriojs/cheerio
*/
import cheerio from 'cheerio';
// 定义 爬取完成的 数据类型
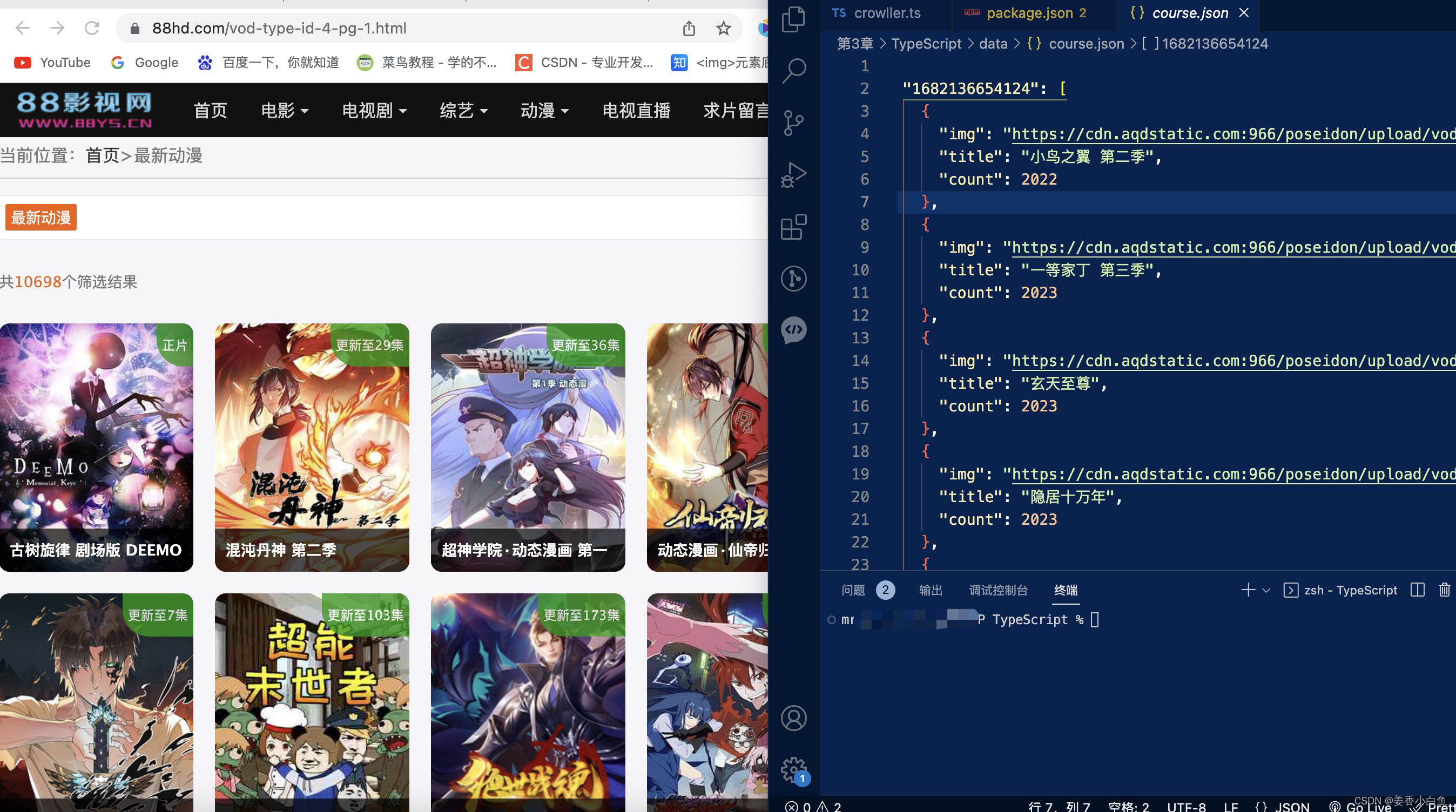
interface Course {
img: string;
title: string;
count: number;
}
/**
* 创建一个 名称为Crowller的类
* 访问类型
* public 允许 在类的内外被调用
* private 允许 在类内部被使用,不允许类外部使用
* protected 允许 在类内及 继承的子类中被使用,不允许类外使用
* ts 无法直接引用 js库 ,需要一个.d.ts的翻译文件,才可以引入 js库
*/
class Crowller {
// 慕课网准备的 地址,最后参数会有变动,到时改这个就行。
private secret = 'secretkey';
// 慕课网准备的 爬取数据的官网
// private url = `http://www.dell-lee.com/typescript/demo.html?secret=${this.secret}`;
private url = `https://www.88hd.com/`
// 解析html 函数
getCourseInfo(html: string) {
/* cheerio可以解析几乎任何HTML或XML文档。
cheerio和jQuery选择器的实现几乎是相同的,所以API非常相似。
传入 要解析的html模版或 标签 */
const $ = cheerio.load(html)
// 根据html上找到,for循环那一模块的类名
const courseItems = $('.link-hover')
// 定义新数组,存放爬去到的 数据
const courseInfos: Course[] = [];
// 通过 循环遍历获取 每一个区块中的数据
courseItems.map((index, element) => {
// 查找 单个区块中,类名为 course-desc 标签 文本
const courseDesc = $(element).find('.lzbz');
// 查找 单个区块中,类名为 course-img 标签 图片
const courseImg = $(element).find('.lazy');
// 获取到图片地址
const img = courseImg.attr('data-original')
// 这个标签类名有两个,获取第一个 标签中的 文本数据
const title = courseDesc.find('.name').text()
/* (当前课程学习人数:87)标签内文本,只获取数字
使用split进行分割,分割中文冒号。
[0为'当前课程学习人数',1为'22' ]分割后
第一个参数 转换成整数。第二个参数 10 表示使用十进制进行转换
*/
const count = parseInt(courseDesc.find('.actor').eq(2).text().split('/')[0], 10)
// 爬取完的 图片,标题,观看数,存放到新数组中
if (typeof img === 'string') {
courseInfos.push({ img, title, count })
}
})
// 返回一个对象 类型的数据
const result = {
// 现在的时间戳
time: new Date().getTime(),
// 爬取完数据后的 数组
data: courseInfos
}
console.log(result);
// console.log(courseItems.length);
}
// 定义 爬取 网站 对应的 最原始html内容
async getRawHtml() {
// superagent.get(url).then 它是一个promise返回值
const result = await superagent.get(this.url);
// result.text 是最原始的html
// 传给 getCourseInfo 函数,由函数再次进行解析,出模版中所需的数据
this.getCourseInfo(result.text)
}
// constructor 在这个类被new的时候,瞬间执行,生成一个实例挂载到类上
constructor() {
// 获取最原始 html的内容
this.getRawHtml();
// console.log('测试是否成功运行');
}
}
// 有了类,下面创建一个实例
const crowller = new Crowller()
4. 然后需要创建json文件,将解构好的数据填入
// 引入 文件操作模块
import fs from 'fs';
// 引入 路径处理模块
import path from 'path';
/* 通过 superagent 轻量的 Ajax API
这个工具 获取网址上面,html的内容
js库ts无法直接读取 cnpm install superagent--save
ts使用翻译文件 @types/引入js库 cnpm install @types/superagent -D
*/
import superagent from 'superagent';
/* cnpm install cheerio--save | cnpm install @types/cheerio -D
解析 html标签,取出里面内容
参考 js库地址 https://github.com/cheeriojs/cheerio
*/
import cheerio from 'cheerio';
// 定义 爬取完成的 数据类型
interface Course {
img: string;
title: string;
count: number;
}
// 定义 将数据添加json 文件的 类型
interface CourseResult {
time: number; // 时间戳 数字类型
data: Course[] // 解析好的数据对象类型
}
// 写入 json文件
interface ContentJson {
// propName 时间戳
[propName: number]: Course[]
}
/**
* 创建一个 名称为Crowller的类
* 访问类型
* public 允许 在类的内外被调用
* private 允许 在类内部被使用,不允许类外部使用
* protected 允许 在类内及 继承的子类中被使用,不允许类外使用
* ts 无法直接引用 js库 ,需要一个.d.ts的翻译文件,才可以引入 js库
*/
class Crowller {
// 慕课网准备的 地址,最后参数会有变动,到时改这个就行。
private secret = 'secretkey';
// 慕课网准备的 爬取数据的官网
private url = `http://www.dell-lee.com/typescript/demo.html?secret=${this.secret}`;
// path.resolve 方法用于将相对路径转为绝对路径,__dirname:在哪里使用,就是表示当前文件所在的 目录
private filePath = path.resolve(__dirname, '../data/course.json')
// 解析html 函数
getCourseInfo(html: string) {
/* cheerio可以解析几乎任何HTML或XML文档。
cheerio和jQuery选择器的实现几乎是相同的,所以API非常相似。
传入 要解析的html模版或 标签 */
const $ = cheerio.load(html)
// 根据html上找到,for循环那一模块的类名
const courseItems = $('.course-item')
// 定义新数组,存放爬去到的 数据
const courseInfos: Course[] = [];
// 通过 循环遍历获取 每一个区块中的数据
courseItems.map((index, element) => {
// 查找 单个区块中,类名为 course-desc 标签 文本
const courseDesc = $(element).find('.course-desc');
// 查找 单个区块中,类名为 course-img 标签 图片
const courseImg = $(element).find('.course-img');
// 获取到图片地址
const img = courseImg.attr('src')
// 这个标签类名有两个,获取第一个 标签中的 文本数据
const title = courseDesc.eq(0).text()
/* (当前课程学习人数:87)标签内文本,只获取数字
使用split进行分割,分割中文冒号。
[0为'当前课程学习人数',1为'22' ]分割后
第一个参数 转换成整数。第二个参数 10 表示使用十进制进行转换
*/
const count = parseInt(courseDesc.eq(1).text().split(':')[1], 10)
// 爬取完的 图片,标题,观看数,存放到新数组中
if (typeof img === 'string') {
courseInfos.push({ img, title, count })
}
})
// 返回一个对象 类型的数据
// const result =
return {
// 现在的时间戳
time: new Date().getTime(),
// 爬取完数据后的 数组
data: courseInfos
}
// console.log(result);
}
// 获取html内容。 定义 爬取 网站 对应的 最原始html内容
async getRawHtml() {
// superagent.get(url).then 它是一个promise返回值
const result = await superagent.get(this.url);
// 返回 result.text 是最原始的html
return result.text;
}
// 生成json文件。 定义 函数 将courseResult对象数据,添加进json文件中
addJsonFile(courseResultList: CourseResult) {
// path.resolve 方法用于将相对路径转为绝对路径,__dirname:在哪里使用,就是表示当前文件所在的 目录
// const filePath = path.resolve(__dirname, '../data/course.json')
// 文件不存在,创建文件的初始内容
let fileContent: ContentJson = {};
// 判断 data目录 course.json文件是否存在
if (fs.existsSync(this.filePath)) {
// 文件存在,读取文件数据 (将字符串转成json对象)
fileContent = JSON.parse(fs.readFileSync(this.filePath, 'utf-8'))
}
// 文件不存在,将时间戳,和解析好的数据。填入初始内容中
fileContent[courseResultList.time] = courseResultList.data;
return fileContent;
}
// 写入course.json中
writeFile(content: string) {
fs.writeFileSync(this.filePath, content)
}
// 初始化操作。 定义 获取 解析 html 函数
async InitSpiderProcess() {
// 调用函数 爬取 网站 对应的 最原始html内容
const html = await this.getRawHtml();
/* 调用 解析html 函数,传入 html 模版
并使用courseResult 接住 这个函数返回的 对象数据 */
const courseResultList = this.getCourseInfo(html)
// 生成json文件,传入 返回的对象数据
const fileContent = this.addJsonFile(courseResultList)
// 写入course.json中,将对象、数组转换成字符串
this.writeFile(JSON.stringify(fileContent))
}
// constructor 在这个类被new的时候,瞬间执行,生成一个实例挂载到类上
constructor() {
// 调用 获取 解析 html 函数
this.InitSpiderProcess();
// console.log('测试是否成功运行');
}
}
// 有了类,下面创建一个实例
const crowller = new Crowller()
5. 到这里只能算初步完成,还需要拆分优化
拆分文件,将解析html函数抽离,使用单例模式,配置package.json文件实现,热更新。看我下篇文章
来张效果图